Redis HyperLogLog 统计 UV 实战:PFADD、PFCOUNT 和误差边界怎么用
来源:17golang原创
时间:2026-06-13 17:00:40 180浏览 收藏
统计 UV 时,最直接的做法是把每个用户 ID 放进 Set,然后用集合大小得到去重人数。这个方案很准,但当一天有几百万、几千万访问用户时,内存成本会越来越明显。Redis HyperLogLog 适合处理这种“只关心数量,不关心具体名单”的场景。
摘要
HyperLogLog 是 Redis 提供的近似去重计数结构。它不保存完整用户列表,而是用固定大小的结构估算基数。本文用站点日 UV 做例子,演示 PFADD 写入访问用户、PFCOUNT 读取 UV、按天拆 Key、合并多天结果,以及什么时候不该使用它。
适合人群
适合正在做访问统计、活动曝光统计、搜索词去重、接口独立调用人数统计的后端开发者。你需要会基本 Redis 命令,并理解“精确统计”和“近似统计”的区别。
目录
- 为什么不用 Set 直接统计所有 UV
- HyperLogLog 的基本流程
- 按天统计 UV 的命令示例
- 多天 UV 合并怎么做
- 常见坑和适用边界
为什么不用 Set 直接统计所有 UV
Set 的优点是精确:你可以知道哪些用户来过,也能得到准确数量。但它必须保存每一个用户 ID。访问量越大,内存占用越高。
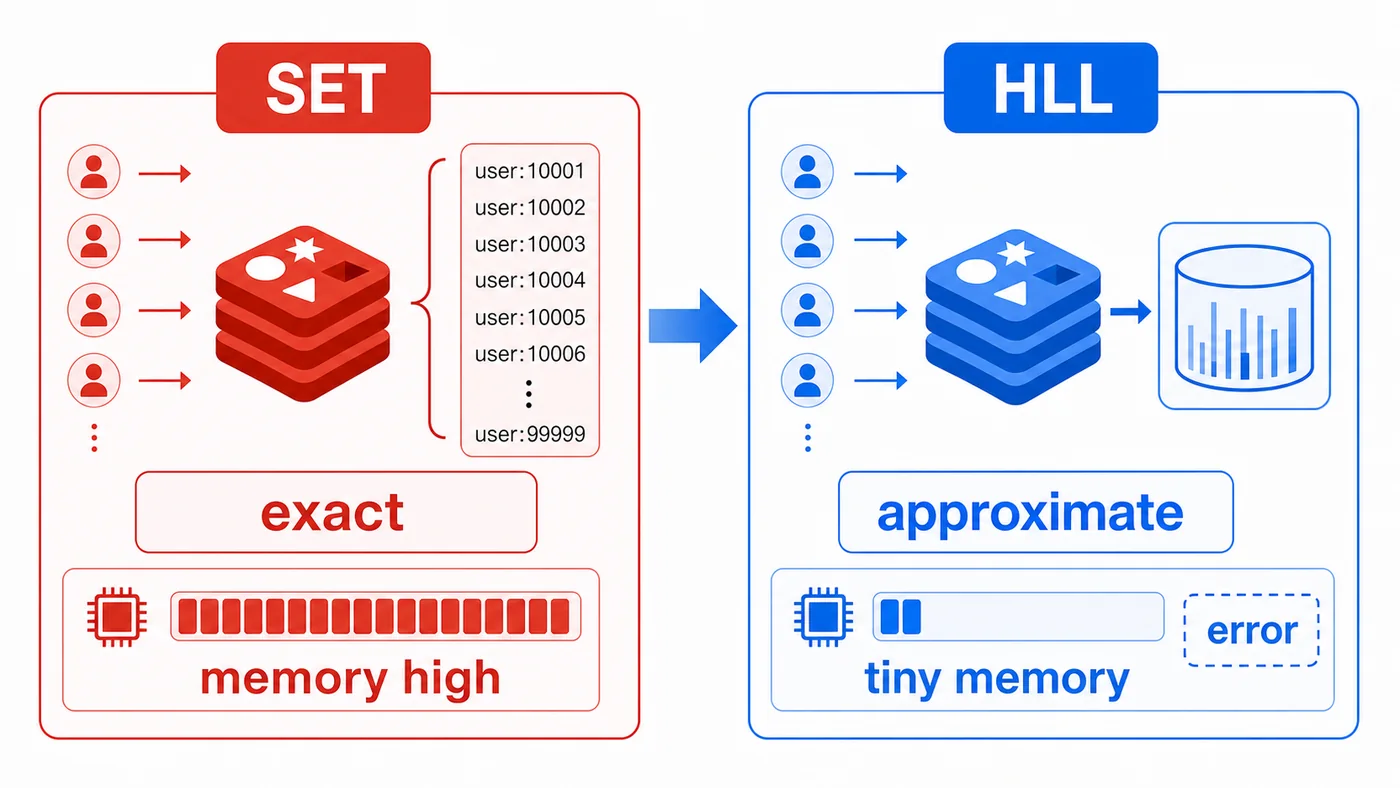
如果业务只需要“今天大约有多少独立访客”,并不需要查出具体用户列表,HyperLogLog 就更合适。它用很小的空间换来可接受的统计误差,适合监控趋势、运营看板、活动效果统计。
HyperLogLog 的基本流程
HyperLogLog 的使用流程很简单:每次用户访问时,把用户唯一标识写入当天的 HLL;需要展示 UV 时,读取这个 Key 的估算值。
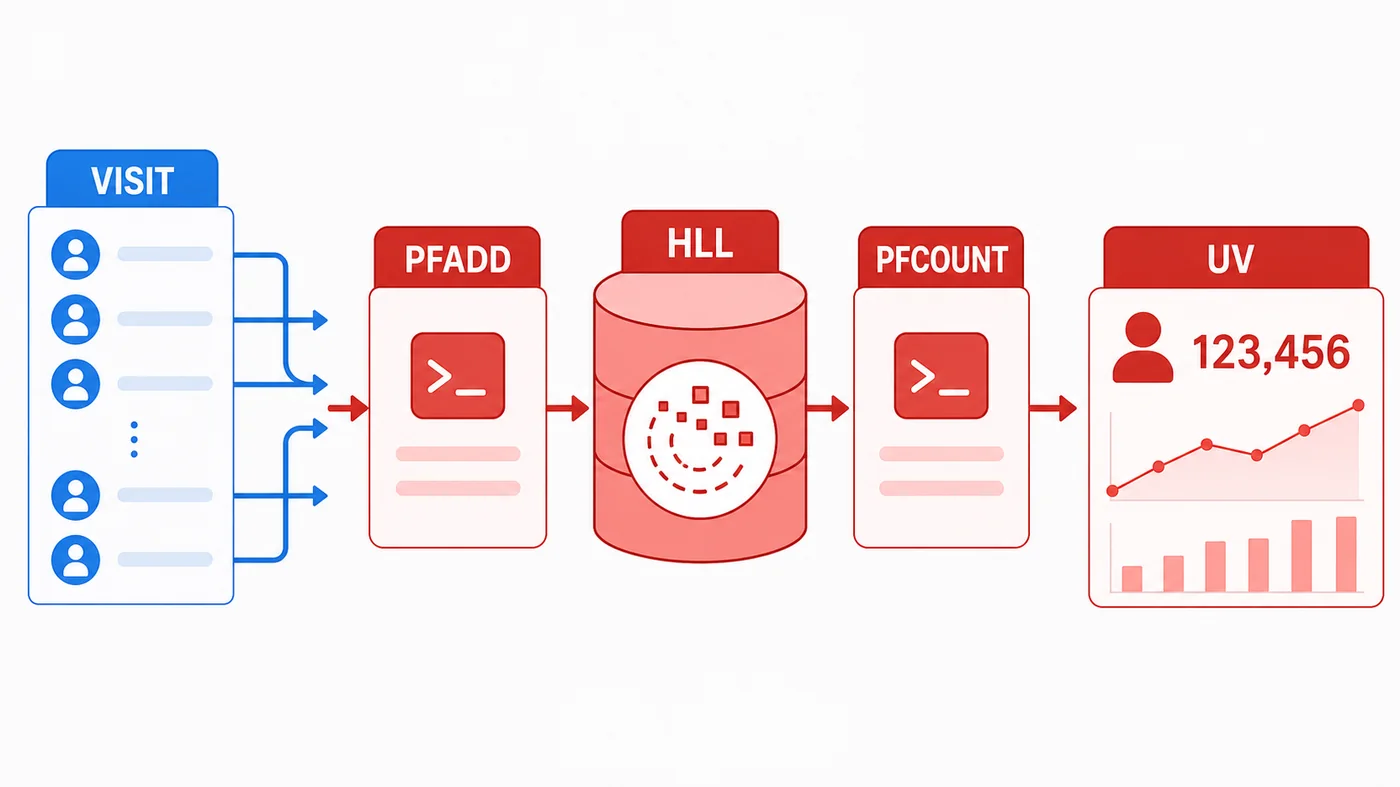
常用命令只有几个:
PFADD:向 HyperLogLog 添加一个或多个元素。PFCOUNT:返回一个或多个 HyperLogLog 的近似基数。PFMERGE:把多个 HyperLogLog 合并到一个目标 Key。
按天统计 UV 的命令示例
假设我们按天存 Key,命名为 uv:site:20260613。用户访问时写入用户 ID:
PFADD uv:site:20260613 user:10001 PFADD uv:site:20260613 user:10002 PFADD uv:site:20260613 user:10001
同一个用户重复写入不会让 UV 一直增加,因为 HyperLogLog 做的是去重后的基数估算。
读取当天 UV:
PFCOUNT uv:site:20260613
在业务代码里,通常把写入放在访问入口或埋点消费逻辑里:
from datetime import date
def record_uv(redis_client, user_id: str) -> None:
key = f"uv:site:{date.today():%Y%m%d}"
redis_client.pfadd(key, f"user:{user_id}")
def read_today_uv(redis_client) -> int:
key = f"uv:site:{date.today():%Y%m%d}"
return redis_client.pfcount(key)
这里用 user_id 比 IP 更稳定。如果是未登录用户,可以使用设备 ID、匿名访客 ID 或经过脱敏处理的浏览器标识。
多天 UV 合并怎么做
如果要统计近 7 天 UV,不能把每天的 PFCOUNT 简单相加,因为同一个用户可能多天访问。正确做法是让 Redis 对多个 HLL 做合并估算。
PFCOUNT uv:site:20260607 uv:site:20260608 uv:site:20260609
如果这个统计结果会被反复查询,可以先合并到一个临时 Key:
PFMERGE uv:site:7d:20260613 uv:site:20260607 uv:site:20260608 uv:site:20260609 PFCOUNT uv:site:7d:20260613
临时合并 Key 可以设置过期时间,避免统计中间结果长期堆积。
常见坑和适用边界
- 不要拿它做精确名单:HyperLogLog 只能估算数量,不能反查有哪些用户。
- 不要用于强一致计费:如果金额、奖励、风控名单必须精确,优先用 Set、数据库或明细表。
- Key 粒度要先设计:按天、按活动、按页面拆 Key,后续查询和合并会更清晰。
- 用户标识要稳定:随机会话 ID 会放大 UV,最好使用登录用户 ID 或稳定匿名 ID。
- 接受近似误差:看趋势和大盘通常够用,看单个小样本时要谨慎。
总结
Redis HyperLogLog 适合“只要去重数量,不要完整名单”的场景。用 PFADD 记录访问,用 PFCOUNT 读取 UV,用 PFMERGE 做多天合并,可以用很低的内存成本支撑大规模统计。它不是 Set 的完全替代品,而是为大规模近似基数统计准备的工具。
-
374 收藏
-
398 收藏
-
117 收藏
-
426 收藏
-
171 收藏
-
数据库 · Redis | 9小时前 | Redis · go · Pipeline · 批处理 · 重试 · 幂等性 · 重试 go-redis 幂等键 批量写入 Redis Pipeline 逐条结果391 收藏
-
154 收藏
-
386 收藏
-
127 收藏
-
422 收藏
-
326 收藏
-
494 收藏
-
数据库 · Redis | 3天前 | Redis · 缓存 · 限流 · Redis 8.8 · INCREX · Redis 8.8 INCREX Redis窗口限流 Redis计数器 ENX UBOUND123 收藏
-
数据库 · Redis | 5天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT259 收藏
-
183 收藏
-
413 收藏
-
数据库 · Redis | 1星期前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计364 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习