Java Stream 分组统计实战:groupingBy、counting 和 summarizingInt 怎么用
来源:17golang原创
时间:2026-06-13 17:54:47 478浏览 收藏
业务代码里经常会遇到这种需求:一批订单按状态统计数量、按用户汇总金额、按分类算平均值。很多人第一反应是写循环和多个 Map,当然能做,但代码会越来越散。
Java Stream 的 Collectors.groupingBy() 更适合这类“先分组,再聚合”的场景。本文用订单列表做例子,讲清分组计数、分组求和,以及用 summarizingInt 一次拿到多项统计指标。
适合人群
适合已经会使用 Java 集合和 Lambda 的开发者。如果你经常写列表统计、报表小接口、管理后台汇总数据,这篇文章可以直接套用。
目录
- 准备一份订单数据
- 按订单状态分组计数
- 按用户汇总订单金额
- 用 summarizingInt 一次拿到多项统计
- 常见坑位和使用建议
准备一份订单数据
先定义一个简单的订单记录。这里为了让示例聚焦统计逻辑,只保留用户、状态和金额三个字段。
import java.util.List;
record Order(String userId, String status, int amount) {}
List orders = List.of(
new Order("u01", "PAID", 120),
new Order("u02", "PAID", 80),
new Order("u01", "REFUND", 30),
new Order("u03", "NEW", 200),
new Order("u02", "PAID", 60)
);
接下来所有统计都基于这份列表完成。真实项目里,orders 可能来自数据库查询结果、消息消费结果,或者某个接口的内存聚合。
按订单状态分组计数
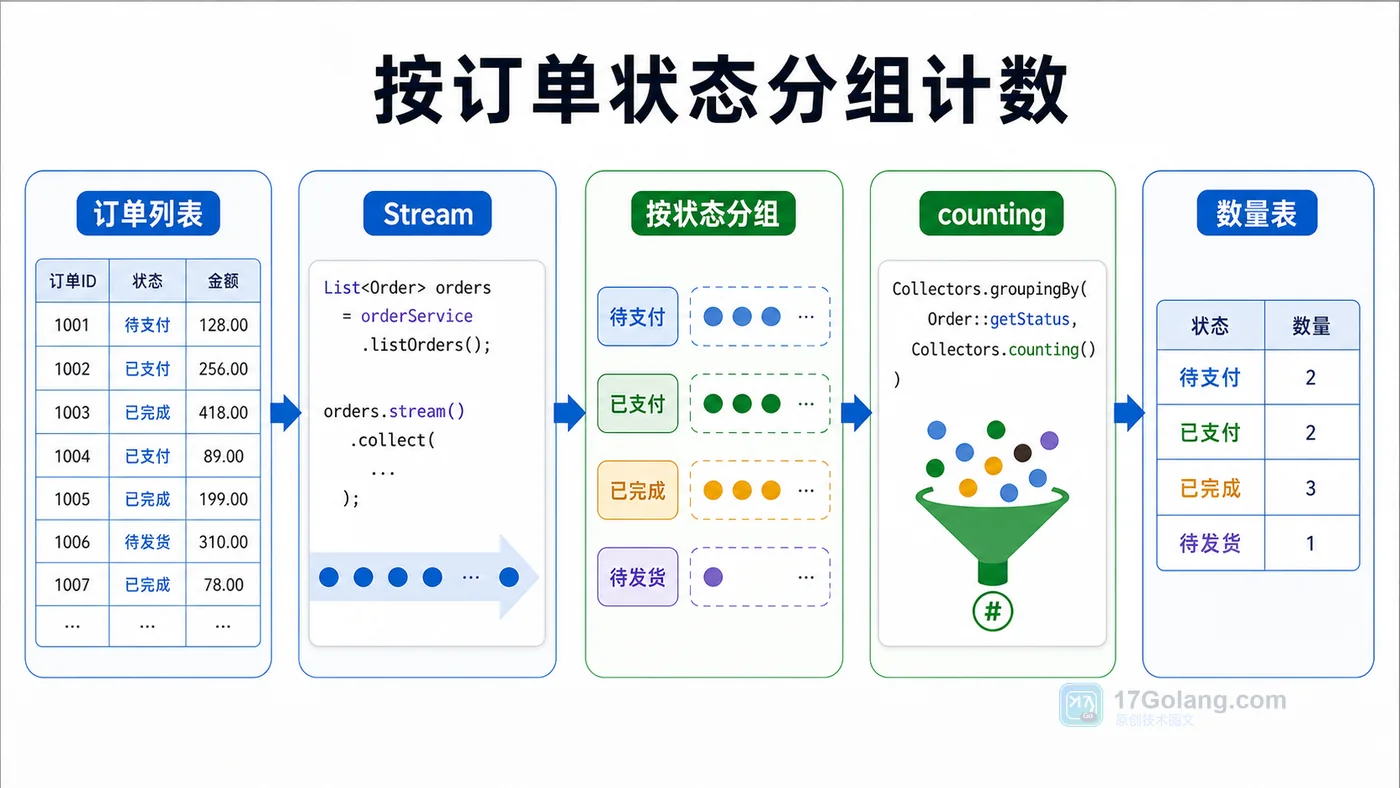
最常见的统计是“每种状态有多少单”。用 groupingBy 搭配 counting 就能完成:
import java.util.Map; import java.util.stream.Collectors; MapcountByStatus = orders.stream() .collect(Collectors.groupingBy( Order::status, Collectors.counting() )); System.out.println(countByStatus);
输出可能是:
{NEW=1, REFUND=1, PAID=3}
这段代码的含义是:先按 Order::status 取分组 key,再对每组元素做 counting 聚合。下面这张图把数据从列表到分组结果的流向拆开看。
按用户汇总订单金额
如果要统计每个用户的订单金额总和,可以把下游收集器换成 summingInt:
MapamountByUser = orders.stream() .collect(Collectors.groupingBy( Order::userId, Collectors.summingInt(Order::amount) )); System.out.println(amountByUser);
输出可能是:
{u01=150, u02=140, u03=200}
这里的关键是:groupingBy 负责把订单按用户切成几组,summingInt 只关心每组里的金额字段怎么相加。
用 summarizingInt 一次拿到多项统计
如果一个接口既要返回订单数,又要返回总金额、最大金额、平均金额,可以使用 summarizingInt。它会返回 IntSummaryStatistics,里面包含多项统计结果。
import java.util.IntSummaryStatistics;
IntSummaryStatistics stats = orders.stream()
.collect(Collectors.summarizingInt(Order::amount));
System.out.println("count = " + stats.getCount());
System.out.println("sum = " + stats.getSum());
System.out.println("max = " + stats.getMax());
System.out.println("avg = " + stats.getAverage());
如果想先按状态分组,再对每个状态分别做金额统计,也可以把它作为 groupingBy 的下游统计器:
MapamountStatsByStatus = orders.stream() .collect(Collectors.groupingBy( Order::status, Collectors.summarizingInt(Order::amount) ));
这类写法很适合报表接口:先选好分组维度,再选好每组需要的指标。

常见坑位和使用建议
1. 注意返回类型
counting() 返回的是 Long,不是 Integer。如果你把结果塞进 DTO,字段类型要提前对齐。
2. key 可能为空时要先处理
分组 key 如果可能为 null,建议在进入分组之前先做过滤或默认值转换,否则后续展示层很容易出现奇怪分组。
3. 复杂统计不要硬塞进一行
Stream 适合表达清晰的数据流。如果统计逻辑已经包含多种判断、补偿规则和外部查询,拆成几个具名方法反而更容易维护。
4. 大数据量统计优先交给数据库
Stream 分组适合内存中的中小批量数据。如果数据量很大,并且统计维度能用 SQL 表达,优先让数据库完成过滤和聚合,Java 侧只做结果整理。
小结
groupingBy 解决“按什么分组”,counting、summingInt、summarizingInt 解决“每组怎么算”。把这两个层次分开理解,Java Stream 的分组统计就会变得很自然。日常写报表接口时,先确定分组 key,再选择合适的下游统计器,代码会比手写多个循环更集中、更容易检查。
-
387 收藏
-
435 收藏
-
130 收藏
-
479 收藏
-
337 收藏
-
455 收藏
-
文章 · java教程 | 2天前 | hashmap · 集合 · Java教程 · hashCode · equals · java HashMap map equals hashCode 可变key474 收藏
-
178 收藏
-
文章 · java教程 | 3天前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存236 收藏
-
204 收藏
-
文章 · java教程 | 4天前 | Java · 集合 · ArrayList · Iterator · removeIf · java iterator ArrayList ConcurrentModificationException removeIf410 收藏
-
文章 · java教程 | 4天前 | Java · 异步编程 · 后端开发 · CompletableFuture · 接口聚合 · java 结果合并 completablefuture 并行调用 超时兜底428 收藏
-
文章 · java教程 | 4天前 | Java · 线程安全 · DateTimeFormatter · 日期处理 · 并发问题 · java 线程安全 日期格式化 threadlocal SimpleDateFormat DateTimeFormatter481 收藏
-
224 收藏
-
文章 · java教程 | 6天前 | 时间处理 · instant · Java教程 · 时区转换 · DateTimeFormatter · java DateTimeFormatter java.time 时区处理 ZoneId INSTANT461 收藏
-
文章 · java教程 | 6天前 | Java · 文件读取 · 异常处理 · 资源管理 · try-with-resources · java 异常处理 try-with-resources 资源关闭 AutoCloseable 文件流268 收藏
-
324 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习