Linux inode 用尽排查完整流程:df -i、find 定位和清理归档
来源:17golang原创
时间:2026-06-16 10:17:21 284浏览 收藏
Linux 服务器上有一种问题很容易误判:df -h 看磁盘空间还有不少,但应用写文件时却报 No space left on device。如果只盯着容量,很可能会绕一圈才发现真正问题是 inode 被大量小文件耗尽。
本文按完整工作流来处理:先定边界,再确认容量和 inode,再定位小文件目录,最后把清理、归档、日志轮转和监控一起补上。目标不是只删掉一批文件,而是让同类问题下次能提前发现。
目录
- 目标和边界:先确认要解决什么
- 全流程总览:从写入失败到 inode 恢复
- 阶段 1:用 df -h 和 df -i 分清容量与 inode
- 阶段 2:用 find 找到小文件集中目录
- 阶段 3:清理、归档和日志轮转一起落地
- 我的推荐工作流
- 容易踩坑的地方
- 速查表
目标和边界:先确认要解决什么
这类问题的目标很明确:让应用恢复写入,同时找出 inode 被谁消耗掉,避免只靠临时删除文件续命。
本文默认场景是普通 Linux 服务器上的应用目录、日志目录、缓存目录或临时文件目录。不会展开文件系统底层原理,也不会讨论重新格式化分区这种高风险操作。线上处理时,任何删除动作都应该先确认目录归属、业务影响和保留周期。
全流程总览:从写入失败到 inode 恢复
先把路线图放出来。遇到写入失败时,不要只看 df -h。容量正常并不代表还能创建文件,inode 用完同样会导致创建失败。
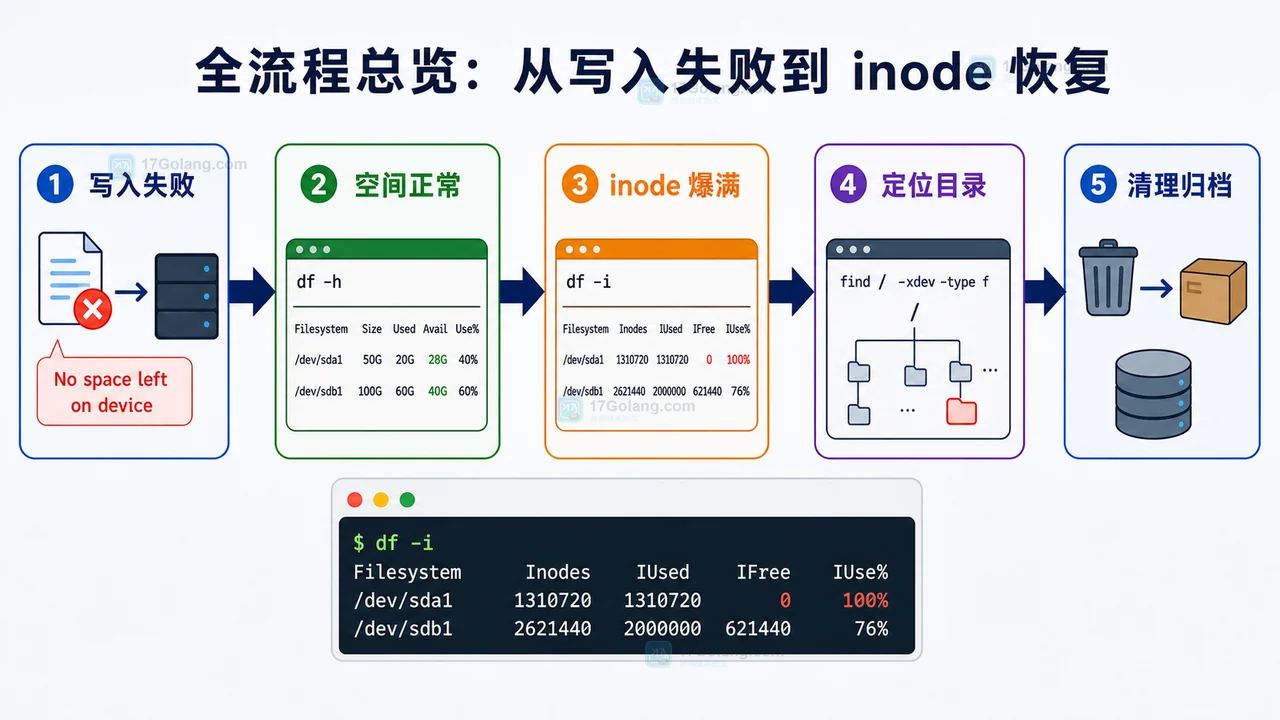
这条链路里的关键判断是:如果 df -h 显示容量还够,但 df -i 显示 IUse% 接近 100%,那就应该把排查重点转到“小文件数量”上。
阶段 1:用 df -h 和 df -i 分清容量与 inode
目标
确认当前报错到底是磁盘容量不足,还是 inode 不足。两个问题处理方式不同,不能混在一起看。
关键动作
先看容量:
df -h
再看 inode:
df -i
如果看到类似下面的结果,就说明 inode 已经被打满:
Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sda1 1310720 1310720 0 100% /
检查点
| 检查项 | 正常信号 | 异常信号 |
|---|---|---|
df -h |
容量未满 | Use% 接近 100% |
df -i |
IFree 还有余量 | IUse% 接近 100% |
| 应用报错 | 写入正常 | No space left on device |
阶段 2:用 find 找到小文件集中目录
目标
inode 用尽通常不是一个大文件导致的,而是大量小文件堆出来的。下一步要找出文件数量最多的目录。
关键动作
可以先从常见目录缩小范围,例如 /var、应用缓存目录、上传临时目录、日志目录:
find /var -xdev -type f | sed 's#/[^/]*$##' | sort | uniq -c | sort -nr | head -20
这条命令的思路是:列出文件,转换成所在目录,按目录统计文件数量,再取数量最多的前 20 个。结果可能类似:
245000 /var/cache/app/session 82000 /var/log/app/request 35000 /var/tmp/upload
检查点
定位目录后,先确认这些文件是否能清理:
- 是不是业务仍在读取的文件。
- 是否有明确保留周期,比如 7 天、30 天。
- 是否需要先归档,再删除本地旧文件。
- 是否由应用异常产生,比如失败重试不断写临时文件。
阶段 3:清理、归档和日志轮转一起落地
临时恢复可以先清理确认过的旧文件,但真正稳定的方案应该包含三件事:批量清理、日志轮转、监控告警。
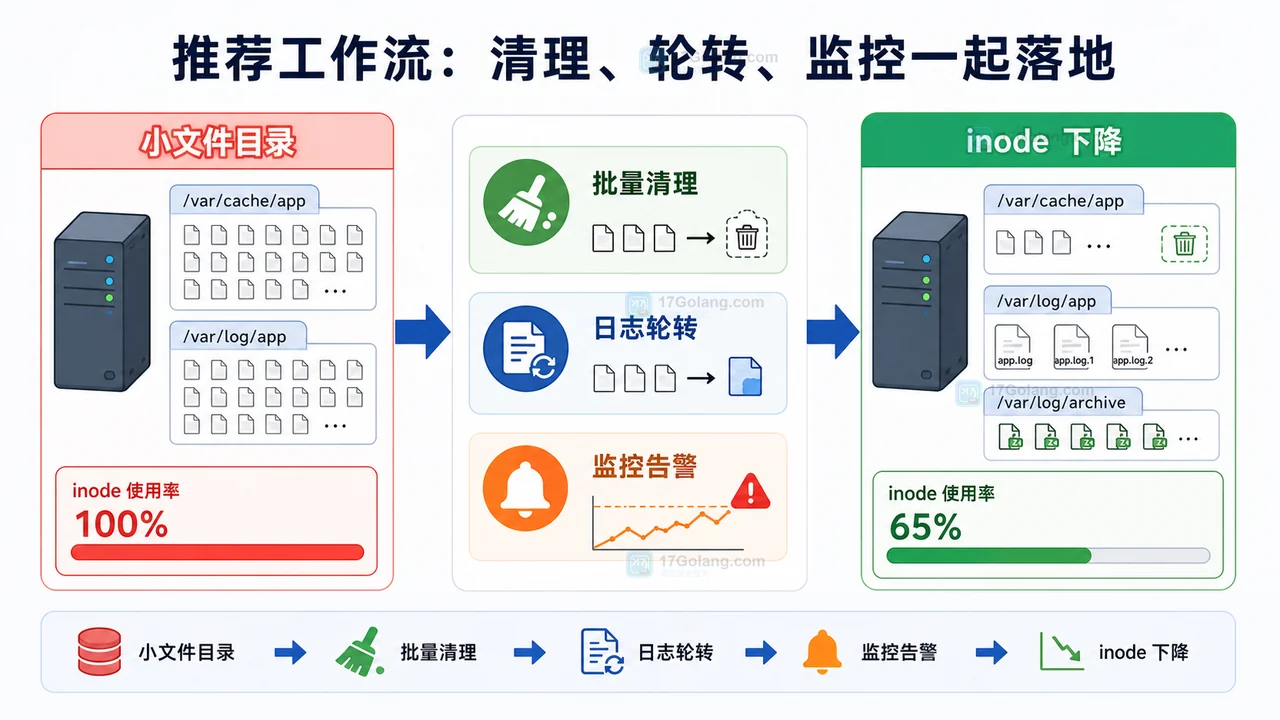
目标
把 inode 使用率从危险区降下来,并让新增小文件有固定生命周期。
关键动作
清理 7 天前的缓存文件示例:
find /var/cache/app -type f -mtime +7 -print0 | xargs -0 -r rm -f
归档 30 天前的日志示例:
mkdir -p /data/archive/app-log find /var/log/app -type f -mtime +30 -print0 | xargs -0 -r tar -rf /data/archive/app-log/old-files.tar
归档完成后,再根据业务确认是否删除本地旧文件。对于持续增长的日志目录,优先配置轮转策略,让单个目录不会无限堆文件。
检查点
清理后再次查看 inode:
df -i
如果 IUse% 从 100% 降到安全区,应用也能正常写入,说明恢复动作有效。下一步就不是继续手动删除,而是补监控和自动清理策略。
我的推荐工作流
- 先记录应用报错时间、目录和服务名。
- 运行
df -h,排除容量用尽。 - 运行
df -i,确认 inode 使用率。 - 用
find在对应挂载点下统计文件数量最多的目录。 - 确认目录归属和保留周期,先归档或清理过期文件。
- 再次运行
df -i和应用写入测试。 - 补上日志轮转、缓存过期、inode 使用率告警。
容易踩坑的地方
- 只看 df -h:容量正常不代表 inode 正常,写入失败时两个命令都要看。
- 直接全盘查找:大机器上全盘扫描很慢,先按挂载点和业务目录缩小范围。
- 不确认目录归属就删除:缓存、会话、上传临时文件的业务影响不同,删除前必须确认。
- 只清理不治理:如果生成小文件的逻辑还在,inode 迟早会再次打满。
- 没有告警阈值:建议对 inode 使用率设置 80%、90% 两级提醒。
速查表
| 阶段 | 命令或动作 | 判断信号 |
|---|---|---|
| 确认容量 | df -h |
容量是否打满 |
| 确认 inode | df -i |
IUse% 是否接近 100% |
| 定位目录 | find ... | uniq -c |
哪个目录文件数最多 |
| 恢复服务 | 清理或归档过期文件 | 应用能否重新写入 |
| 长期治理 | 轮转、过期、监控 | inode 使用率持续下降 |
总结一下:遇到 No space left on device,不要只盯容量。先用 df -h 和 df -i 把问题分型,再用文件数量定位目录,最后把清理策略和监控补上。这样处理一次,后面同类问题就不会靠猜。
-
186 收藏
-
文章 · linux | 5天前 | Linux · 服务治理 · 日志排查 · 运维教程 · Linux 服务管理器 journalctl 服务重启 运维排查 RestartSec start-limit-hit408 收藏
-
399 收藏
-
120 收藏
-
文章 · linux | 2星期前 | Linux · inode · 日志清理 · 磁盘排查 · 服务器运维 · Linux inode 磁盘空间 df du lsof No space left on device335 收藏
-
422 收藏
-
文章 · linux | 2星期前 | 服务器 · Linux · ssh · 运维排查 · 登录慢 · Linux SSH pam sshd_config 登录慢 UseDNS GSSAPI 密钥权限153 收藏
-
文章 · linux | 2星期前 | Linux · 运维排查 · 文件句柄 · ulimit · 服务限制 · Linux 文件句柄 lsof ulimit too many open files LimitNOFILE 服务限制482 收藏
-
文章 · linux | 2星期前 | Linux · 运维 · 性能排查 · 磁盘IO · iostat · pidstat · Linux 性能排查 iostat 磁盘IO pidstat %util260 收藏
-
335 收藏
-
286 收藏
-
494 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习