Cloudflare 吸收 Ensemble AI 团队:开发者该怎么重新审视 AI 推理链路
来源:17golang原创
时间:2026-06-16 12:32:57 430浏览 收藏
Cloudflare 在 2026 年 6 月 15 日发布官方博客,宣布 Ensemble AI 的团队人才加入 Cloudflare。官方信息里提到,这支团队的方向集中在 AI 推理、模型压缩和推理引擎优化,这些能力会与 Cloudflare 的 AI 基础设施结合。
这条新闻对普通开发者的价值,不只是“又一家公司加强 AI 布局”。更实际的问题是:如果云厂商开始把模型运行、压缩优化、边缘网络和 AI 网关做成更紧密的一体化能力,业务团队评估 AI 应用时,就不能只看模型效果,还要重新检查延迟、成本、稳定性和迁移边界。
摘要
Cloudflare 吸收 Ensemble AI 团队,说明 AI 基础设施竞争正在从“能不能接模型”转向“模型能不能更快、更省、更容易接入生产”。开发团队应从任务类型、延迟目标、成本结构、数据合规和小流量试点五个角度重新审视自己的 AI 推理链路。
适合人群
- 正在接入 AI 问答、客服助手、内容生成、代码辅助的开发者。
- 需要评估云端 AI 平台、边缘推理和模型网关的架构负责人。
- 关注 AI 基础设施、模型压缩、推理成本变化的技术管理者。
- 先说结论:这条新闻看的是推理链路效率
- 事实边界:官方消息里确认了什么
- 阶段一:盘点自己的 AI 任务类型
- 阶段二:重新测延迟和稳定性
- 阶段三:把成本拆到单次调用和月度预算
- 阶段四:用小流量试点验证收益
- 容易踩坑:不要只看平台宣传
- 速查表
先说结论:这条新闻看的是推理链路效率
Cloudflare 这次官方消息的关键词,不只是 AI,而是推理基础设施。对开发团队来说,真正要关注的是三件事:
- 延迟。 用户请求进入 AI 应用后,多久能拿到第一段有效结果。
- 成本。 同样的业务任务,每次调用和每月总量是否可控。
- 部署路径。 AI 网关、模型运行环境、边缘网络和业务接口能否串成稳定链路。
如果一个平台能把模型运行和压缩优化放进统一链路,开发者就有机会减少自建推理层的复杂度。但这不是自动等于“立刻迁移”,而是意味着我们需要更系统地重新评估现有链路。
事实边界:官方消息里确认了什么
按照 Cloudflare 官方博客披露的信息,Ensemble AI 团队加入 Cloudflare 后,会把其 AI 推理相关经验带入 Cloudflare 的平台能力中。官方文章提到的重点包括推理引擎、模型压缩,以及让更大模型更容易在基础设施中运行的方向。
这里要把边界说清楚:这不是某个开发者今天就能直接得出“成本一定下降多少”的结论。官方消息表达的是平台能力方向,具体收益仍然取决于业务任务、模型选择、上下文长度、并发模式、区域分布和缓存策略。
| 观察点 | 对开发者的含义 | 需要自己验证什么 |
|---|---|---|
| 推理引擎优化 | 可能改善模型响应体验 | 首包时间、完整响应时间、并发稳定性 |
| 模型压缩 | 可能降低运行资源占用 | 质量损失、任务准确度、召回稳定性 |
| 平台整合 | 可能减少自建链路维护成本 | 接口适配、日志追踪、权限和数据边界 |
阶段一:盘点自己的 AI 任务类型
到这一步不要急着切平台。先把团队里的 AI 任务列出来,分清楚哪些任务真的受推理效率影响。
常见任务可以分成四类:
- 实时交互。 客服助手、搜索问答、代码补全,对延迟很敏感。
- 半实时处理。 工单总结、邮件草稿、运营文案,对稳定性更敏感。
- 批量任务。 文档分类、日志摘要、数据清洗,更关注成本和吞吐。
- 高风险决策。 风控、财务、自动操作,需要人工确认和审计。
只有把任务类型列清楚,后面的延迟测试和成本估算才有意义。否则很容易拿一个低风险批量任务的结果,去判断实时交互场景是否值得迁移。
阶段二:重新测延迟和稳定性
推理平台的体验不能只看平均值。开发者至少要记录三类指标:
- 首段响应时间。 用户什么时候看到第一段有意义输出。
- 完整响应时间。 任务真正完成需要多久。
- 尾部延迟。 少量慢请求是否会影响整体体验。
测试时建议准备固定样本集,覆盖短问答、长上下文、多轮对话和异常输入。每次只替换一个变量,例如平台、模型、上下文长度或是否启用压缩,避免把多个因素混在一起。
阶段三:把成本拆到单次调用和月度预算
AI 成本不能只看“单价”。一个真实业务系统里,成本通常由这些部分叠加:
- 模型输入和输出规模。
- 上下文缓存、检索、重排序等前置步骤。
- 失败重试和降级调用。
- 日志、审计、监控和存储。
- 高峰期并发带来的资源冗余。
如果平台优化能降低模型运行资源,团队仍然要检查整体账本:是否因为上下文变长、重试变多、任务范围扩大,抵消了优化收益。成本评估应该落到“单次任务”和“月度预算”两个层面。
阶段四:用小流量试点验证收益
我的建议是:不要因为一条基础设施新闻立刻大规模迁移。更稳的流程是小流量试点。
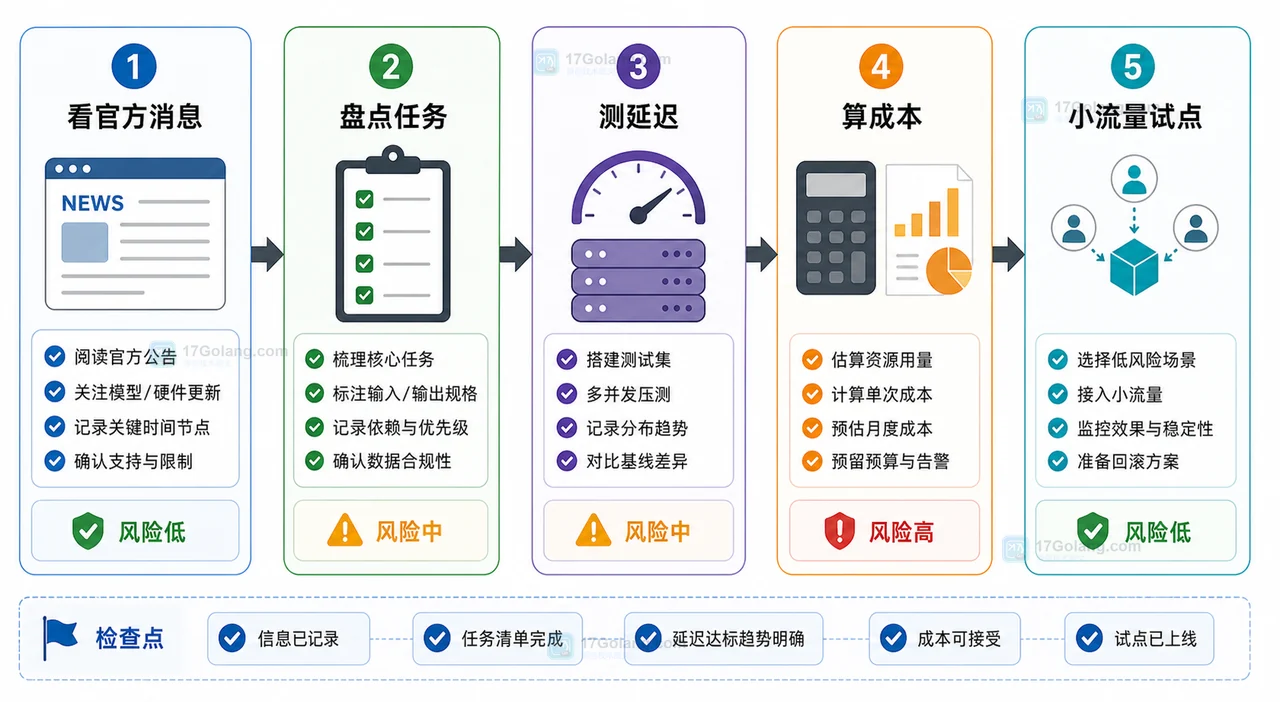
试点时可以按这条顺序走:
- 选择低风险、可回滚的 AI 场景。
- 固定输入样本和成功标准。
- 记录延迟、失败率、质量差异和成本变化。
- 保留原链路作为回退方案。
- 确认监控、日志和权限边界完整。
这张图的重点不是某个具体平台,而是评估顺序:先看官方消息,再盘点任务,接着测延迟、算成本,最后用小流量验证。
容易踩坑:不要只看平台宣传
第一个坑是只看“更快”和“更省”。AI 生产链路里,速度和成本只是两个指标,质量、可追踪、合规和回滚同样重要。
第二个坑是忽略数据边界。如果任务涉及用户数据、内部文档或业务报表,迁移平台前必须确认数据传输、日志保存、权限隔离和删除策略。
第三个坑是没有基线。没有旧链路指标,就无法判断新平台是否真的更好。上线前至少要保存一组可复跑的样本集。
第四个坑是一次性全量替换。AI 链路的不确定性更高,建议保留回退开关,让业务可以在异常时快速切回原方案。
速查表
| 检查项 | 要问的问题 | 通过标准 |
|---|---|---|
| 任务类型 | 实时、半实时、批量还是高风险决策 | 每类任务都有独立指标 |
| 延迟 | 首段响应和完整响应是否稳定 | 关键场景达到用户体验要求 |
| 成本 | 单次任务和月度预算是否可控 | 有预算上限和告警规则 |
| 质量 | 压缩或平台变化是否影响答案质量 | 样本集复查没有明显退化 |
| 回退 | 异常时能否快速切回旧链路 | 有开关、日志和回滚步骤 |
总的来看,Cloudflare 吸收 Ensemble AI 团队,是 AI 基础设施竞争继续深入的一次信号。开发者不需要被新闻推动着马上迁移,但应该借这个节点把自己的 AI 推理链路重新梳理一遍:任务是什么、瓶颈在哪、成本怎么算、风险怎么兜底。只有这些问题回答清楚,平台升级才会真正变成工程收益。
-
284 收藏
-
103 收藏
-
387 收藏
-
411 收藏
-
328 收藏
-
科技周边 · 业界新闻 | 21小时前 | 业界新闻 · Cloudflare · AI Gateway · Spend Limits · AI成本 · Cloudflare AI Gateway Spend Limits AI成本治理 AI预算 模型降级495 收藏
-
科技周边 · 业界新闻 | 22小时前 | Node.js · javascript · 安全版本 · 运行时 · 升级排查 · 业界新闻 Node.js安全版本 Node.js 26.3.0 运行时升级 JavaScript安全308 收藏
-
科技周边 · 业界新闻 | 2天前 | devops · CI/CD · gitHub actions · 业界新闻 · 自托管Runner · DevOps CI/CD GitHub Actions self-hosted runner Runner升级431 收藏
-
科技周边 · 业界新闻 | 3天前 | github · gitHub actions · 业界新闻 · AI代理 · GitHub AI代理 GitHub Actions Agentic Workflows CI分析 Issue分流 工程自动化354 收藏
-
科技周边 · 业界新闻 | 3天前 | 安全 · CI/CD · gitHub actions · 业界新闻 · 开发者工具 · 代码审查 供应链安全 业界新闻 GitHub Actions 机器人PR CI安全473 收藏
-
214 收藏
-
345 收藏
-
356 收藏
-
277 收藏
-
285 收藏
-
270 收藏
-
370 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习