Redis Pipeline 批量读写变慢排查:网络往返、批量大小和结果对齐
来源:17golang原创
时间:2026-06-16 12:46:59 436浏览 收藏
一个接口需要展示 100 个用户的缓存资料,代码里循环调用 Redis:每个用户查一次 GET user:{id}。单次 Redis 读取很快,但接口总耗时却越来越长。这个场景很典型:慢的不是 Redis 数据结构本身,而是应用和 Redis 之间的网络往返被重复放大了。
这篇文章按一次排查过程来写。我们先复现循环 GET 的慢点,再确认是不是网络往返累积,最后用 Pipeline 把多条命令合并成批量发送,并补上批量大小、结果顺序和失败兜底检查。
摘要
Redis Pipeline 适合把一批独立命令一次性发给 Redis,减少应用和服务端之间的多次等待。使用时要控制批量大小,按请求顺序对齐返回结果,并给超时、空值和部分失败准备兜底逻辑,避免把一个优化点变成新的稳定性风险。
适合人群
- 接口里循环读取 Redis 多个 key,响应时间不稳定的后端开发者。
- 正在做缓存批量查询、排行榜补充信息、用户资料聚合的同学。
- 希望用 Redis Pipeline 优化网络开销,但担心批量过大和结果错位的团队。
- 问题现场:单次 GET 快,接口还是慢
- 初步判断:是不是网络往返在累积
- 动手验证:把多次 GET 改成 Pipeline
- 定位关键:Pipeline 不是事务,也不是无限批量
- 修复方案:分批窗口和结果对齐
- 上线复查:延迟、内存和空值都要看
- 总结
问题现场:单次 GET 快,接口还是慢
我们先看一段常见逻辑。页面拿到一批用户 ID 后,后端逐个读取缓存:
ids = [1001, 1002, 1003, ...]
for id in ids:
key = "user:" + id
value = GET key
append result
如果只查 3 个 key,这段逻辑看起来没有问题。但当列表扩大到几十个、上百个 key 时,接口时间会被一轮又一轮等待拉长。每次 GET 都要从应用发到 Redis,再等 Redis 返回,下一条命令才继续。
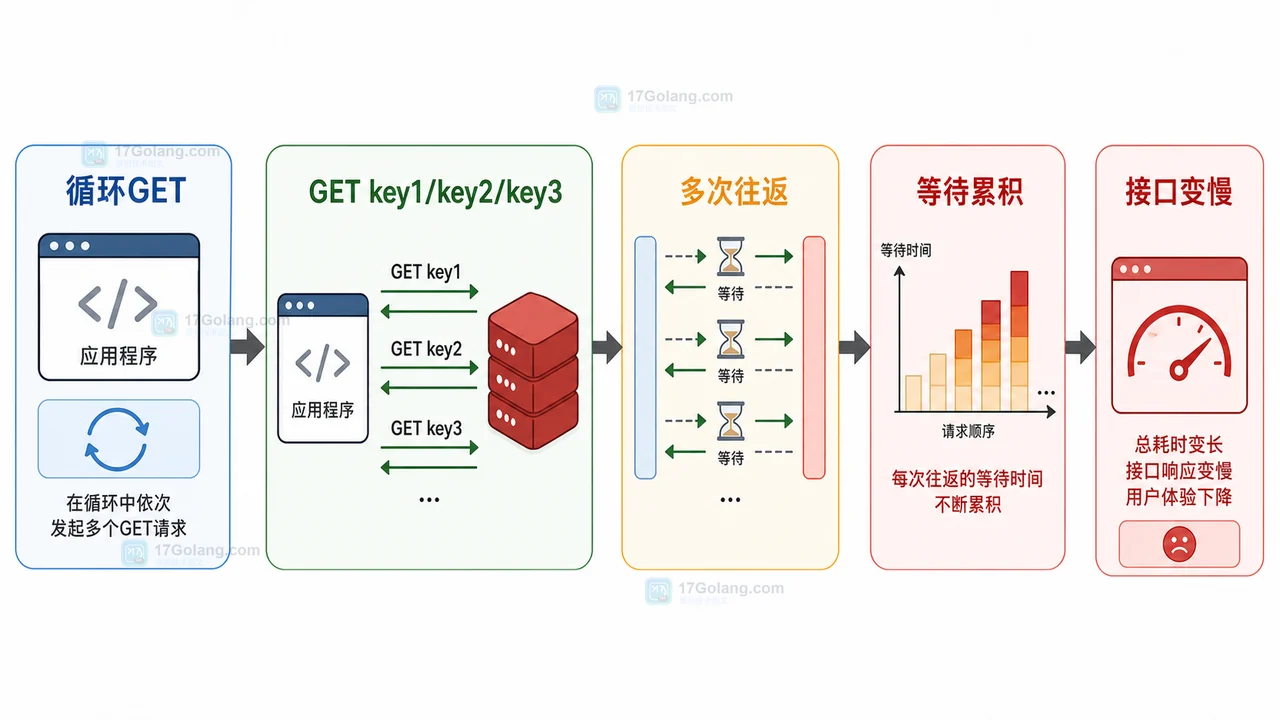
这张图里的重点不是 Redis 处理慢,而是“等待”被重复叠加。单次往返可能并不明显,次数一多,总耗时就会变成接口瓶颈。
初步判断:是不是网络往返在累积
我们先提出一个猜测:Redis 命令本身不慢,慢在应用和 Redis 之间来回等待。要验证这个猜测,可以先记录三个数据:
- 本次请求读取了多少个 key。
- 每次单独 GET 的平均耗时。
- 整个批量读取阶段的总耗时。
如果单次 GET 只需要很短时间,但批量阶段接近“单次耗时乘以 key 数量”,基本就可以判断是串行等待造成的。
keys_count: 120 single_get_avg: 2ms cache_read_total: 240ms+
这一步说明了一个关键信号:Redis 服务端没有明显压力,但应用侧等待次数太多。此时优先考虑 Pipeline,而不是先去改数据结构。
动手验证:把多次 GET 改成 Pipeline
Pipeline 的核心思路很简单:把多条命令先收集起来,一次性发给 Redis,再按顺序拿回一批结果。它减少的是网络往返次数,不是把 Redis 命令变成并行计算。
batch = []
for key in keys:
batch.add(["GET", key])
values = redis.send_pipeline(batch)
注意这里用了伪代码,不绑定某个客户端库。不同语言的 Redis 客户端方法名不一样,但思路一致:收集命令、批量发送、按顺序读取返回值。
如果这一版上线前先在测试环境跑,会看到批量读取阶段明显少了多次等待。尤其是应用和 Redis 不在同一机器、网络延迟稍高时,改善更明显。
定位关键:Pipeline 不是事务,也不是无限批量
现在我们要把结论说清楚。Pipeline 并不等于事务,它不会保证这一批命令要么全部成功、要么全部回滚。它只是把多条命令打包发送,减少等待。
另外,Pipeline 也不是越大越好。一次塞入太多命令,可能带来几个新问题:
- 应用侧需要保存更大的命令列表和结果列表。
- Redis 需要处理更大的输入缓冲和输出缓冲。
- 单次等待时间变长,失败后重试成本更高。
- 结果列表变长后,更容易在业务代码里对错 key。
所以真正稳的方案不是“全部 key 一次扔进去”,而是按窗口分批。
修复方案:分批窗口和结果对齐
我们把修复方案收拢成三步:先收集 key,再按固定窗口分批 Pipeline,最后按顺序把返回结果和原 key 对齐。
batch_size = 100
all_values = {}
for part in split(keys, batch_size):
commands = []
for key in part:
commands.add(["GET", key])
values = redis.send_pipeline(commands)
for index, value in values:
all_values[part[index]] = value
这里最容易漏的是“结果对齐”。Pipeline 返回结果通常按命令发送顺序排列,所以业务代码要保留原始 key 顺序,不能只拿到一个结果列表就直接拼到页面上。
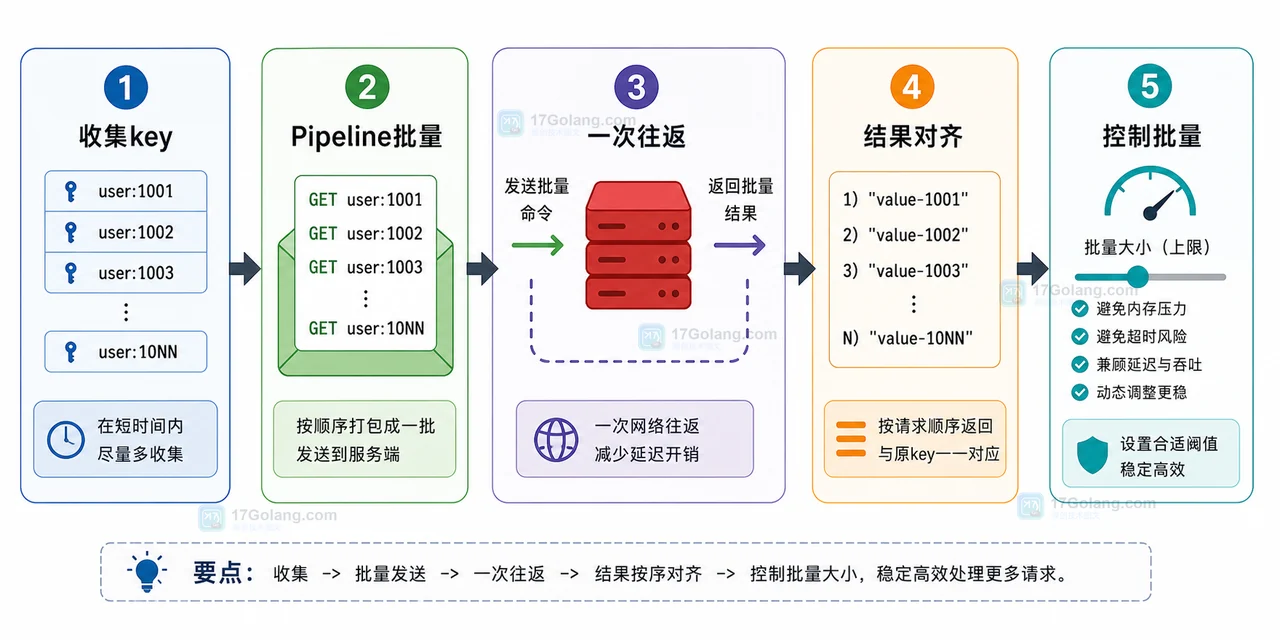
这张图展示的是修复后的链路:先把 key 收集起来,打包成一批命令,一次网络往返拿回结果,再按顺序和原 key 对齐,同时给批量大小设置上限。
上线复查:延迟、内存和空值都要看
改成 Pipeline 后,不要只看接口平均耗时。至少要复查四项:
一、延迟是否真的下降
对比串行读取和 Pipeline 读取的总耗时。建议同时看常规请求和 key 数量较多的请求,避免只优化了少数样本。
二、批量大小是否合适
批量过小,往返次数仍然偏多;批量过大,单次压力和失败成本会升高。可以从 50、100、200 这类窗口开始测试,根据业务负载调整。
三、空值和缺失 key 是否处理正确
不是每个 key 都一定命中。返回空值时要保持位置对齐,不要因为某个 key 缺失就让后面的结果整体错位。
四、失败时是否有兜底
如果某批 Pipeline 超时,不建议无限重试。可以只重试一次,或者降级返回部分数据,并把失败批次、key 数量和耗时写入日志,方便后续排查。
总结
Redis Pipeline 解决的是多条独立命令的网络往返问题。遇到循环 GET、批量补充缓存信息、列表页聚合资料时,可以先判断是否存在串行等待,再用 Pipeline 减少往返次数。
落地时要记住三点:第一,Pipeline 不是事务,不负责回滚;第二,批量要设置窗口,不要无限堆命令;第三,返回结果按命令顺序排列,必须和原 key 对齐。把这三点守住,Pipeline 才是稳定的优化手段,而不是新的线上风险。
-
286 收藏
-
117 收藏
-
185 收藏
-
426 收藏
-
134 收藏
-
407 收藏
-
数据库 · Redis | 21小时前 | Redis · Streams · 消费者组 · Pending · XACK · 消息堆积 消费者组 XACK XPENDING XAUTOCLAIM Redis Streams385 收藏
-
194 收藏
-
368 收藏
-
118 收藏
-
464 收藏
-
180 收藏
-
数据库 · Redis | 3天前 | Redis · 消息队列 · Stream · 消费组 · redis 消息队列 Redis Stream 消费组 XREADGROUP XACK XPENDING XAUTOCLAIM187 收藏
-
139 收藏
-
116 收藏
-
111 收藏
-
438 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习