Go context 超时控制实战:从接口入口到 goroutine 回收的完整流程
来源:17golang原创
时间:2026-06-17 17:17:02 166浏览 收藏
Go 项目里,慢接口最容易把问题扩散成一串连锁反应:HTTP 请求已经超时,DB 查询还在跑,远程调用还在等,goroutine 也没有及时退出。用户看到的是接口慢,服务端看到的是连接、协程和资源慢慢堆起来。
context 的价值就在这里:它把取消信号、超时时间和请求范围串起来,让一条调用链知道什么时候该停止。本文按完整工作流讲解:从接口入口设置超时预算,到传给 DB 和远程请求,再到 goroutine 主动响应取消并释放资源。
- 目标和边界
- 全流程总览
- 阶段一:在入口定义超时预算
- 阶段二:把 ctx 传给 DB 查询和远程请求
- 阶段三:让 goroutine 主动响应取消
- 阶段四:验证超时是否真的生效
- 我的推荐流程
- 容易踩坑
- 落地速查表
目标和边界
本文讨论的是 Go 服务端常见的 context 超时和取消控制。我们不展开 context 源码实现,也不把主题扩展成完整分布式链路治理。读完后,你应该能完成三件事:
- 在 HTTP 入口为每个请求设置合理的超时预算。
- 把
ctx传到 DB 查询、远程请求和后台 goroutine。 - 用测试和日志确认取消信号真的触发了资源回收。
先说结论:context 不是用来存所有业务参数的全局背包,它更适合传递请求范围内的取消、超时和少量跨边界值。真正要做稳,是让每一层都接收 ctx,并在可能阻塞的位置主动响应 ctx.Done()。
全流程总览
一条健康的 Go 请求链路,可以按五步理解:入口 ctx、超时预算、传给 DB、监听 Done、释放资源。只在入口创建 context 不够,后面的 DB 查询、远程请求和 goroutine 都要接住这个信号。
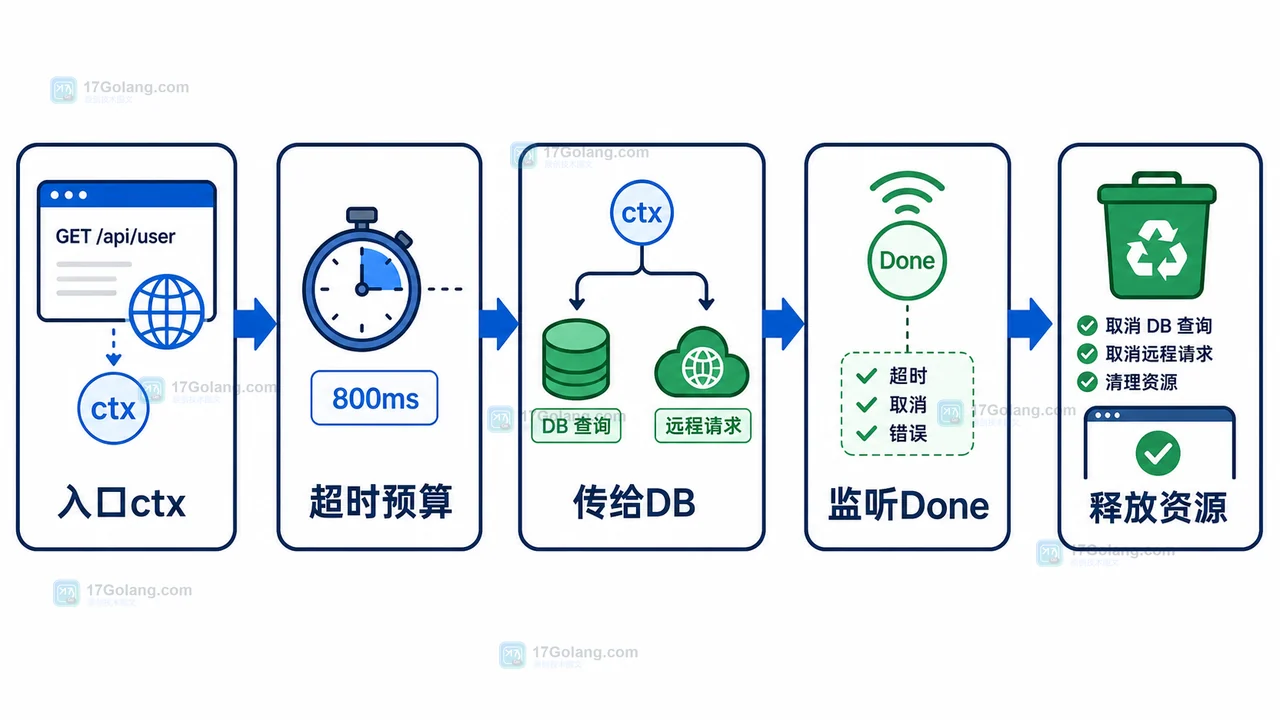
| 阶段 | 目标 | 关键动作 | 检查点 |
|---|---|---|---|
| 入口预算 | 限定请求最长处理时间 | 用 WithTimeout 派生请求 ctx | 每个请求都有清晰时间上限 |
| 向下传递 | 让依赖感知取消信号 | DB 查询、远程请求都使用 ctx | 下游阻塞能被取消 |
| 主动退出 | 避免 goroutine 泄漏 | select 监听 ctx.Done | 请求结束后后台任务不继续空跑 |
| 释放资源 | 归还连接、计时器和通道 | defer cancel、关闭结果通道、停止计时器 | 压测后 goroutine 数量稳定 |
阶段一:在入口定义超时预算
目标
入口层先决定这个请求最多能花多少时间。没有统一预算,后面每一层都会按自己的节奏等待,最终就是接口慢、资源占用高、用户体验差。
关键动作
在 HTTP handler 里从请求 context 派生一个带超时的 ctx,并且立刻安排 cancel。即使请求提前结束,也能及时释放内部计时资源。
func userHandler(w http.ResponseWriter, r *http.Request) {
ctx, cancel := context.WithTimeout(r.Context(), 800*time.Millisecond)
defer cancel()
user, err := loadUser(ctx, r.URL.Query().Get("id"))
if err != nil {
http.Error(w, err.Error(), http.StatusGatewayTimeout)
return
}
json.NewEncoder(w).Encode(user)
}
常用工具/代码选择
入口超时不要随手写一个很大的数。可以按接口目标拆分:轻量读接口 300 到 800ms,复杂聚合接口 1 到 3 秒,批处理走异步任务,不要占用在线请求链路。
检查点
每个对外接口都应该能说清楚:总超时是多少,DB 占多少预算,远程请求占多少预算,超时后返回什么状态和日志。
阶段二:把 ctx 传给 DB 查询和远程请求
目标
入口创建了 ctx 只是第一步。真正能不能取消,取决于下游调用是否使用了支持 context 的 API。
关键动作
DB 查询要使用带 Context 的方法,例如 QueryContext。远程 HTTP 请求也要把 ctx 绑定到请求对象上。
func loadUser(ctx context.Context, id string) (User, error) {
row := db.QueryRowContext(ctx,
"SELECT id, name FROM users WHERE id = ?",
id,
)
var u User
if err := row.Scan(&u.ID, &u.Name); err != nil {
return User{}, err
}
return u, nil
}
func callProfile(ctx context.Context, url string) (*http.Response, error) {
req, err := http.NewRequestWithContext(ctx, http.MethodGet, url, nil)
if err != nil {
return nil, err
}
return http.DefaultClient.Do(req)
}
常用工具/代码选择
函数签名建议把 ctx context.Context 放在第一个参数。这样代码审查时很容易看出某个方法是否参与请求取消链路。
检查点
搜索核心链路里的 DB 查询、远程 HTTP、缓存访问、消息发送,确认它们是否能接收 ctx。不能接收 ctx 的依赖,要在外层加时间限制或隔离。
阶段三:让 goroutine 主动响应取消
最容易被忽略的地方,是 handler 里临时启动的 goroutine。请求已经结束,但 goroutine 没监听取消信号,就会继续跑,甚至一直占着资源。
目标
让每个可能长时间等待的 goroutine 都能在 ctx 取消时退出。
关键动作
在 select 里监听 ctx.Done()。如果 goroutine 还会等待 channel、ticker 或外部结果,就把取消分支和业务分支放在同一个 select 里。
func watchStatus(ctx context.Context, in
如果使用 ticker,也要在函数退出时停止它:
func poll(ctx context.Context) {
ticker := time.NewTicker(200 * time.Millisecond)
defer ticker.Stop()
for {
select {
case
常用工具/代码选择
短生命周期任务直接使用请求 ctx;长生命周期后台任务建议使用服务级 ctx,在服务关闭时统一取消。不要把一次 HTTP 请求的 ctx 传给需要长期存在的任务。
检查点
压测请求超时场景时,goroutine 数量应该先上升后回落,而不是一直涨。日志中也应该能看到取消原因,而不是只有业务错误。
阶段四:验证超时是否真的生效
目标
context 相关代码很容易“看起来写了,实际上没传到底”。所以必须用测试和观测验证。
关键动作
写一个很短超时的测试,让慢任务在 ctx 取消后退出。下面的例子验证函数会在超时时返回,而不是继续等待。
func TestTimeoutReturn(t *testing.T) {
ctx, cancel := context.WithTimeout(context.Background(), 20*time.Millisecond)
defer cancel()
start := time.Now()
err := waitOrStop(ctx, 200*time.Millisecond)
if err == nil {
t.Fatal("want timeout error")
}
if time.Since(start) > 100*time.Millisecond {
t.Fatal("return too late")
}
}
func waitOrStop(ctx context.Context, d time.Duration) error {
timer := time.NewTimer(d)
defer timer.Stop()
select {
case
常用工具/代码选择
测试看行为,日志看链路,指标看资源。建议记录请求耗时、超时次数、ctx 错误类型、DB 查询耗时和 goroutine 数量趋势。
检查点
验证通过的标准是:超时请求按预期返回,下游调用不继续占用资源,goroutine 数量能回落,日志能说明是超时还是上游主动取消。
我的推荐流程
- 先给每个在线接口定义总超时预算,不要让请求无限等待。
- 所有业务函数签名统一把
ctx context.Context放第一个参数。 - DB 查询使用
QueryContext,HTTP 请求使用NewRequestWithContext。 - 所有循环、等待 channel、ticker 的 goroutine 都监听
ctx.Done()。 - 创建派生 ctx 后立刻安排
cancel,避免计时资源滞留。 - 用测试模拟超时,用压测观察 goroutine 和连接数是否回落。
容易踩坑
| 坑点 | 表现 | 修法 |
|---|---|---|
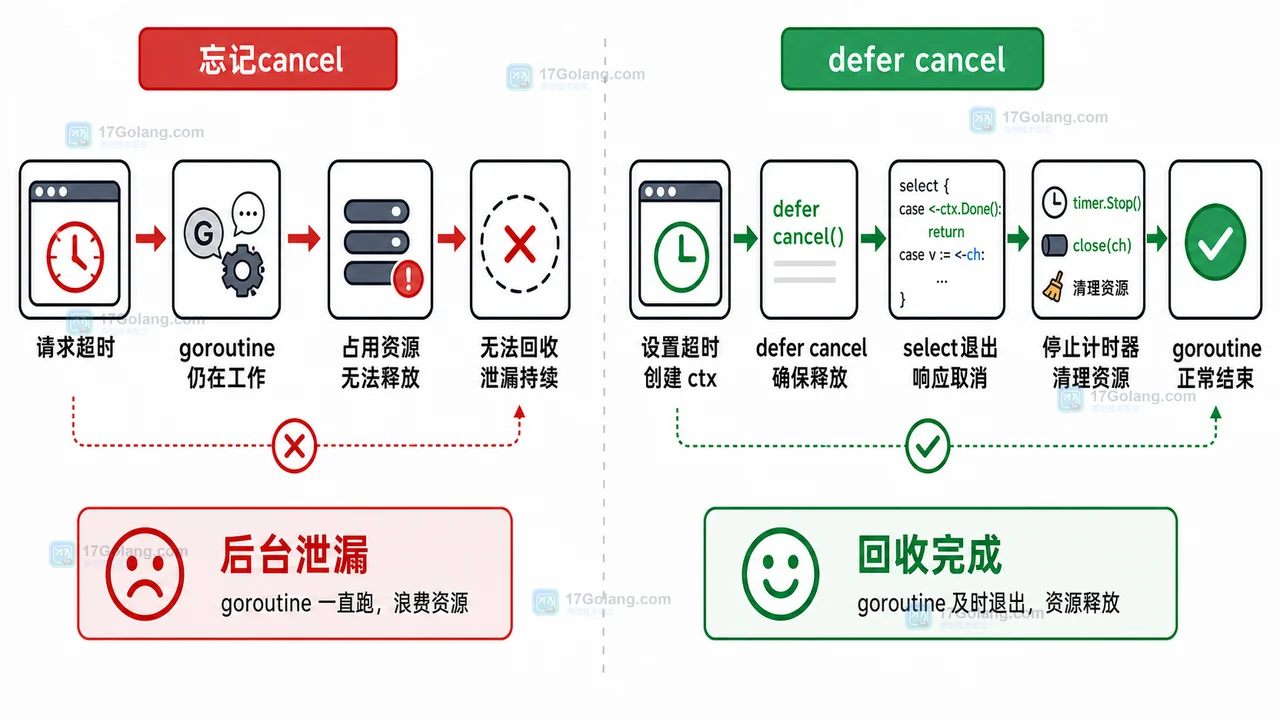
| 创建 ctx 后忘记 cancel | 计时器资源不能及时释放 | 创建后立刻写 defer cancel |
| 只在入口有 ctx | DB 或远程请求仍然继续等待 | 把 ctx 传到所有阻塞调用 |
| goroutine 不监听 Done | 请求结束后后台仍在跑 | select 同时监听业务事件和 ctx.Done |
| 把 ctx 当参数袋 | 业务字段散落在 context 里,难以维护 | 只放跨边界的请求级少量值 |
| 超时时间层层变大 | 总耗时不可控 | 从入口预算向下切分,而不是每层随手设置 |
落地速查表
| 检查项 | 最低要求 | 上线前确认 |
|---|---|---|
| 入口超时 | 每个接口有明确时间预算 | 超时响应和日志一致 |
| ctx 传递 | 业务函数第一个参数是 ctx | 核心链路没有断层 |
| DB 查询 | 使用支持 ctx 的查询方法 | 慢查询能被取消或及时返回 |
| 远程请求 | 请求对象绑定 ctx | 上游取消后下游不继续等待 |
| goroutine | 循环和等待都监听 Done | 压测后数量能回落 |
| 资源清理 | cancel、timer.Stop、通道关闭有明确位置 | 无持续增长的资源曲线 |
总结一下,Go context 超时控制不是在入口包一层 WithTimeout 就结束了。真正完整的流程,是入口定义预算、下游接收 ctx、阻塞点响应 Done、退出时释放资源,并用测试和指标确认这条链路真的生效。
-
221 收藏
-
106 收藏
-
418 收藏
-
401 收藏
-
122 收藏
-
Golang · Go教程 | 9小时前 | 并发 · 闭包 · for range · 迁移 · Go教程 · Go 1.22 · Goroutine 闭包 循环变量 Go教程 Go 1.22 for range113 收藏
-
331 收藏
-
Golang · Go教程 | 10小时前 | 单元测试 · 错误处理 · Go教程 · errors.Join · errors.Is · errors.Is Go错误处理 Go教程 errors.Join 多错误返回 批量校验352 收藏
-
Golang · Go教程 | 10小时前 | Context · 超时控制 · Go教程 · http.Client · Transport · Go context 请求超时 Transport http.Client Client.Timeout ResponseHeaderTimeout218 收藏
-
Golang · Go教程 | 11小时前 | 文件下载 · Go教程 · 审计日志 · 接口安全 · 路径穿越 · Go 文件下载 审计日志 HTTP接口 filepath.Clean 安全下载 路径穿越362 收藏
-
Golang · Go教程 | 12小时前 | Go教程 · HMAC · API安全 · 接口签名 · 防重放 · timestamp Go 中间件 API安全 HMAC 接口签名 nonce 防重放273 收藏
-
Golang · Go教程 | 12小时前 | CI/CD · gitHub actions · Go教程 · 自托管 Runner · 持续集成 · Go 持续集成 CI Go test GitHub Actions self-hosted runner 自托管 runner340 收藏
-
124 收藏
-
Golang · Go教程 | 20小时前 | HTTP · 文件下载 · Go教程 · Range请求 · ServeContent · 断点续传 Content-Range Go教程 HTTP Range ServeContent 206 Partial Content 视频拖动250 收藏
-
Golang · Go教程 | 1天前 | csv · Go教程 · 后端架构 · 流式响应 · 大文件导出 · 大文件下载 FLUSH CSV导出 Go教程 流式写出 csv.Writer rows.Next251 收藏
-
Golang · Go教程 | 1天前 | HTTP服务 · Go教程 · 后端开发 · 超时配置 · 服务稳定性 · net/http WriteTimeout HTTP超时 Go教程 ReadHeaderTimeout IdleTimeout140 收藏
-
Golang · Go教程 | 1天前 | 错误处理 · Context · 并发控制 · Go教程 · 并发控制 Go教程 context取消 context.WithCancelCause context.Cause342 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习