MySQL 明明加了索引,为什么查询还是很慢?先查这 6 个点
来源:17golang原创
时间:2026-06-27 16:53:12 374浏览 收藏
问题很常见:表上已经建了索引,SQL 也写得不复杂,但接口还是慢,甚至在压测时突然飙到几秒。很多人第一反应是“索引没生效”,但真实原因通常不止一个。索引存在,不等于一定会被选中;被选中,也不等于查询一定快。
这篇文章直接回答这个问题:MySQL 明明加了索引,为什么查询还是很慢?我们先给结论,再拆常见误区,最后给一套可复用的排查顺序。
- 问题原文:加了索引为什么还是慢
- 先给结论:索引只是候选路径
- 常见误区一:只看有没有索引
- 正确排查:先看查询计划和过滤比例
- 正确做法:按 6 个高频原因逐项检查
- 边界情况:索引用了也可能慢
- 延伸问题:什么时候该改 SQL,什么时候该改索引
- 总结
问题原文:加了索引为什么还是慢
假设有一张订单表,业务希望按用户、状态和时间查询最近订单,于是加了一个索引:
CREATE INDEX idx_user_status_created ON orders(user_id, status, created_at);
查询语句是:
SELECT id, order_no, amount, created_at FROM orders WHERE status = 'paid' AND created_at >= '2026-06-01' ORDER BY created_at DESC LIMIT 20;
看起来表上有索引,条件里也出现了 status 和 created_at,但查询仍然慢。这个例子里,第一个问题就是:联合索引最左列是 user_id,而查询条件没有它,MySQL 不一定能按你预期使用这个索引。
先给结论:索引只是候选路径
MySQL 优化器会根据统计信息、过滤比例、排序成本、回表成本和可用索引来选择路径。索引不是强制通道,而是候选方案。一个索引是否适合当前 SQL,取决于条件顺序、字段选择性、排序方式、返回列、数据分布等因素。
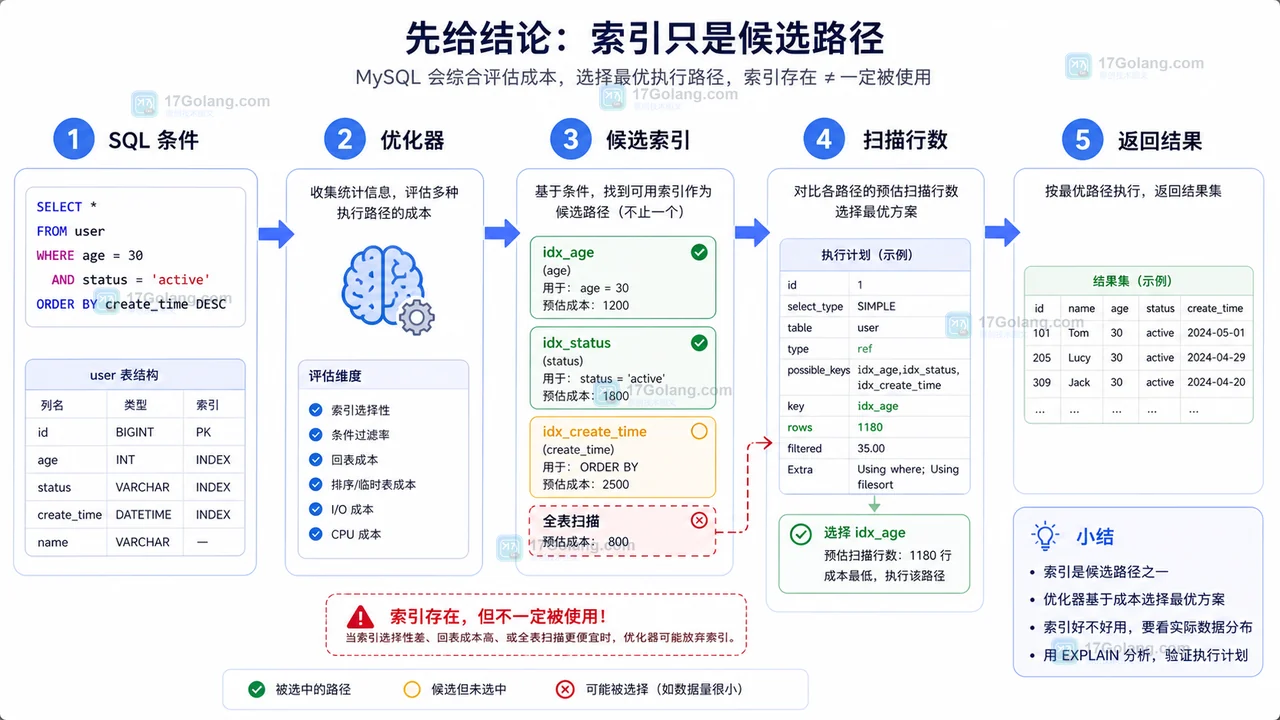
可以先记住一个实用判断:如果 SQL 条件不能有效缩小扫描范围,或者用了索引后需要大量回表、排序,MySQL 可能选择别的路径,甚至扫描更多行。
常见误区一:只看有没有索引
很多排查会停在这一步:
SHOW INDEX FROM orders;
看到索引存在,就认为数据库“应该快”。这不够。索引存在只能证明表结构里有这个候选路径,不能证明当前 SQL 正在使用它,更不能证明这个路径成本最低。
还要避免另一个误区:给每个查询字段都建单列索引。多个单列索引并不等于一个合适的联合索引。对多条件查询来说,字段顺序、过滤能力和排序方式通常更关键。
正确排查:先看查询计划和过滤比例
先用 EXPLAIN 看查询计划。重点看这些字段:
| 字段 | 关注点 | 常见信号 |
|---|---|---|
key | 实际使用的索引 | 为空说明没有选中索引 |
rows | 预估扫描行数 | 过大说明过滤效果差 |
filtered | 条件过滤比例 | 太低说明后置过滤多 |
Extra | 额外动作 | 关注临时表、排序、回表压力 |
EXPLAIN SELECT id, order_no, amount, created_at FROM orders WHERE status = 'paid' AND created_at >= '2026-06-01' ORDER BY created_at DESC LIMIT 20;
如果 key 为空,先看条件是否匹配索引左侧字段。如果 key 有值但 rows 仍然很大,就要看字段选择性和排序成本。不要只凭“用了索引”判断问题已经解决。
正确做法:按 6 个高频原因逐项检查
1. 联合索引没有从最左侧字段开始
索引 (user_id, status, created_at) 更适合先按用户过滤,再按状态和时间过滤的查询。如果 SQL 没有 user_id,这个索引对当前查询可能不是最佳选择。
如果业务确实经常按状态和时间查最近订单,可以考虑补一个更贴近查询的索引:
CREATE INDEX idx_status_created ON orders(status, created_at);
2. 条件写法让字段变成了计算结果
如果在字段上套函数,索引使用可能受影响。下面这种写法不推荐:
WHERE DATE(created_at) = '2026-06-27'
可以改成范围条件,让字段保持原样:
WHERE created_at >= '2026-06-27 00:00:00' AND created_at
3. 类型不一致导致隐式转换
字段是字符串,查询却传数字;字段是数字,查询却传字符串,都可能让优化器做额外转换。排查时要确认参数类型和字段类型一致。
4. 返回列太多,回表成本高
SELECT * 可能让数据库先从索引里找到主键,再回到数据页读取完整行。返回列越多,回表压力越明显。只取业务需要的列,能让查询更容易接近覆盖索引。
5. 排序字段和索引顺序不匹配
查询带 ORDER BY created_at DESC 时,索引顺序是否能帮助排序很关键。如果过滤字段和排序字段组合不合理,数据库可能先筛选,再额外排序。
6. 数据分布变化,统计信息不准
如果表经历过大批量导入、删除或状态值分布变化,统计信息可能不够准确。可以在低峰期更新统计信息,再重新观察查询计划。

边界情况:索引用了也可能慢
有些慢查询确实用了索引,但仍然慢。常见原因包括:
- 扫描范围太大,例如一个状态值覆盖了大部分订单。
- 回表次数太多,返回列又比较多。
- 排序和分页成本高,尤其是深分页。
- 热点数据集中,磁盘、缓存或锁等待成为主要瓶颈。
所以排查不要只问“索引用没用”,还要问“扫描了多少行”“过滤掉多少行”“排序是否额外发生”“回表是否太多”。
延伸问题:什么时候该改 SQL,什么时候该改索引
如果 SQL 写法让字段不能直接参与索引比较,优先改 SQL。例如函数包裹字段、类型不一致、范围过宽。若 SQL 已经清晰,但业务查询模式和现有索引不匹配,再考虑补索引或调整联合索引顺序。
可以按下面顺序决策:
- 先确认慢的是哪条 SQL,而不是凭感觉改表结构。
- 用
EXPLAIN看实际索引、扫描行数和额外动作。 - 能改写条件的先改写条件。
- 能减少返回列的先减少返回列。
- 最后再根据稳定查询模式设计联合索引。
总结
MySQL 加了索引仍然慢,并不矛盾。索引只是候选路径,是否真正适合当前查询,要看联合索引顺序、条件写法、类型一致性、返回列、排序方式和数据分布。排查时先看查询计划,再按 6 个高频原因逐项排除,最后再决定是改 SQL、补索引,还是调整业务查询方式。
-
398 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
265 收藏
-
165 收藏
-
196 收藏
-
408 收藏
-
259 收藏
-
文章 · 常见问题 | 4天前 | 常见问题 · 正版漫画App · 漫画订阅 · 漫画网页版 · 漫画试读 · 漫画试读 漫画地区限制 正版漫画app推荐 漫画网页版和app区别 漫画网页阅读 漫画订阅281 收藏
-
269 收藏
-
157 收藏
-
文章 · 常见问题 | 4天前 | 常见问题 · 正版漫画App · 漫画版权 · 漫画官网 · 阅读安全 · 正版漫画推荐 正版漫画app怎么辨别 漫画app官网 漫画授权标识 漫画版权查询 漫画app安全339 收藏
-
文章 · 常见问题 | 4天前 | 常见问题 · 正版漫画App · 漫画推荐 · 漫画语言 · 漫画地区 · 漫画地区限制 正版漫画app中文 漫画app没有中文 漫画语言怎么选 繁体中文漫画 漫画官网推荐114 收藏
-
文章 · 常见问题 | 4天前 | 常见问题 · 漫画追更 · 正版漫画App · 漫画推荐 · 漫画订阅 · 正版漫画app订阅 漫画app要不要会员 漫画订阅值不值 漫画追连载 漫画补完作品 正版漫画推荐137 收藏
-
文章 · 常见问题 | 4天前 | 常见问题 · 漫画阅读 · 正版漫画App · 漫画推荐 · 漫画版权 · 漫画版权 漫画地区限制 正版漫画app推荐 漫画app哪个内容全 漫画官方平台 漫画语言272 收藏
-
442 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习