Python 读取大文件内存飙升复盘:从 read() 一次读入到分块迭代修复
来源:17golang原创
时间:2026-06-27 23:56:58 196浏览 收藏
线上任务偶尔会因为一行看起来很普通的 read() 把内存打满。问题不一定出在 Python 语言本身,而是文件处理方式没有和数据规模匹配:小文件时代没问题,大文件一来就变成事故。
这篇文章按一次故障复盘的方式,把“Python 读取大文件内存飙升”拆开看:影响面是什么,时间线里哪些现象最关键,触发条件是什么,根因为什么是一次性读入,最后如何改成分块迭代并建立防复发检查。
- 影响面:导入任务卡住并拖高内存
- 时间线:从上传成功到任务被杀掉
- 触发条件:文件体积从几十 MB 变成数 GB
- 根因:read() 把整份文件搬进内存
- 修复动作:改成分块迭代和逐段处理
- 防复发:给文件处理链路加上边界
影响面:导入任务卡住并拖高内存
问题出现在一个 Python 后台导入任务里。用户上传数据文件后,任务会读取文件内容,做简单清洗,再写入后续处理队列。小文件一直正常,直到某次上传了一个接近 2GB 的日志文件。
可见影响有三个:
- 导入任务长时间没有完成。
- 机器内存快速升高,其他任务开始变慢。
- 进程最终被系统终止,用户只能看到导入失败。
这类问题的危险点在于:它不像语法错误那样立刻暴露,而是在文件规模增长后才出现。
时间线:从上传成功到任务被杀掉
先把故障过程按时间线还原,避免一开始就跳到代码结论:
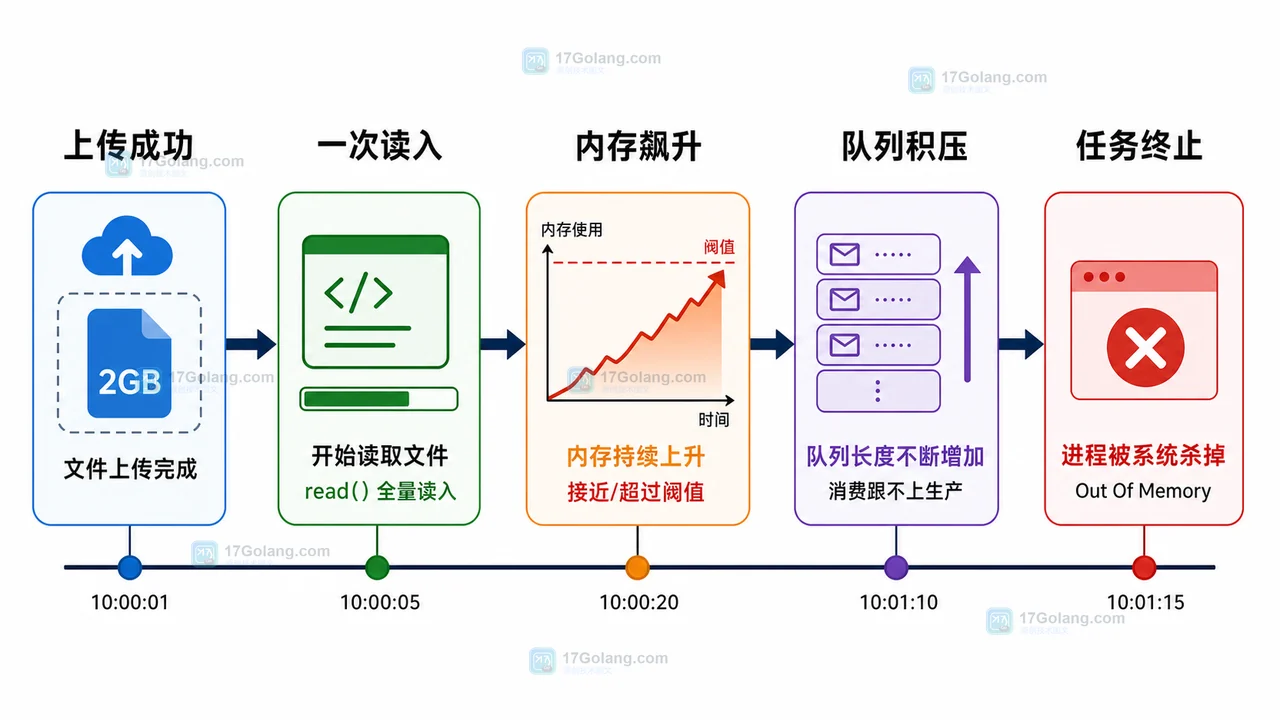
- 10:02 用户上传大文件,上传接口返回成功。
- 10:03 后台导入任务开始读取文件。
- 10:04 内存曲线快速升高,CPU 也出现明显抖动。
- 10:05 任务日志停止刷新,队列积压开始增加。
- 10:06 进程被系统终止,本次导入失败。
这条时间线提示我们:问题发生在“读取文件”和“进入清洗逻辑”之间,重点应该先查文件读取方式。
触发条件:文件体积从几十 MB 变成数 GB
复查历史任务后,发现之前大多数文件只有几十 MB,最大也不到 200MB。出问题的文件接近 2GB,刚好把原来隐藏的内存风险放大。
一个典型的风险写法如下:
from pathlib import Path
def import_log_file(path: str) -> int:
text = Path(path).read_text(encoding="utf-8")
rows = text.splitlines()
total = 0
for row in rows:
if row.strip():
total += 1
return total
这段代码在小文件上很好懂:先读出全部文本,再按行拆分。但在大文件上,它会同时持有整份文本和拆分后的行列表,内存占用会明显高于文件本身体积。
根因:read() 把整份文件搬进内存
根因不是“Python 不能处理大文件”,而是代码把文件当成小字符串处理。常见问题有三类:
read()或read_text()一次性读取整份文件。splitlines()再复制出一份行列表。- 清洗逻辑把中间结果继续放进列表,导致内存层层叠加。
可以用一个简单示意理解旧链路:文件先进入内存成为大字符串,再拆成大列表,最后才开始逐行处理。文件越大,中间对象越多,峰值内存越不可控。
修复动作:改成分块迭代和逐段处理
修复思路是把“整份文件先读完”改成“按行或按块逐段处理”。如果业务逻辑按行清洗,直接迭代文件对象通常就够用:
from pathlib import Path
def import_log_file(path: str) -> int:
total = 0
with Path(path).open("r", encoding="utf-8") as file:
for row in file:
if row.strip():
total += 1
return total
如果处理的是二进制文件,或者需要固定大小分段,可以使用 read(size):
from pathlib import Path
def count_bytes(path: str, chunk_size: int = 1024 * 1024) -> int:
total = 0
with Path(path).open("rb") as file:
while True:
chunk = file.read(chunk_size)
if not chunk:
break
total += len(chunk)
return total
修复后的链路应该变成这样:
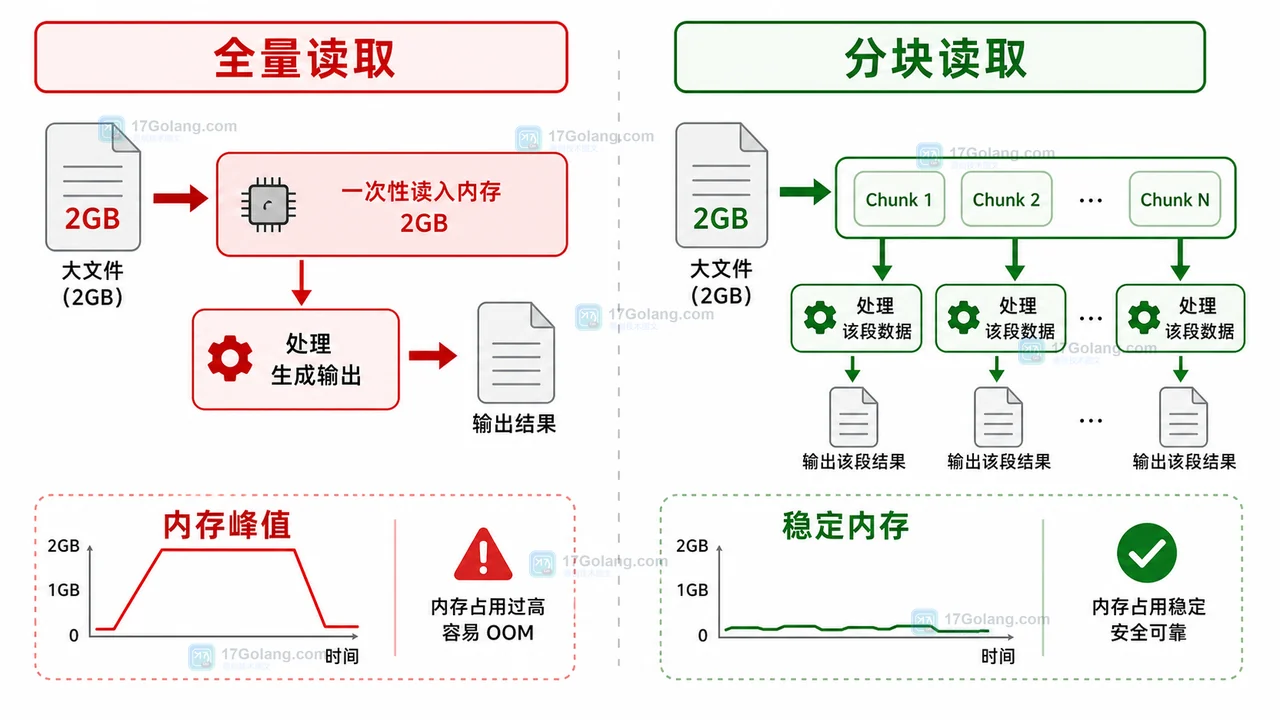
这次改动的关键不是把某个函数换成另一个函数,而是把处理模型从“先全量加载”改成“边读边处理”。这样峰值内存主要由单行长度或块大小决定,而不是由整个文件体积决定。
防复发:给文件处理链路加上边界
事故修好以后,还要把边界补上,否则下一类大文件仍然可能触发类似问题。
- 入口限制:上传入口明确最大文件体积,超过限制给出清晰提示。
- 读取规则:评审文件处理代码时,重点检查是否有全量读取。
- 任务监控:为导入任务加内存、耗时和失败计数。
- 异常样本:保留一个大文件测试样本,发布前做回归运行。
- 中间结果:避免把所有清洗结果攒在列表里,能逐批写出就逐批写出。
总结一下:Python 处理大文件的核心原则是避免一次性把全部内容搬进内存。先还原影响和时间线,再定位触发条件,最后把读取模型改成迭代式处理,这样才能把问题从“偶发事故”变成“可控边界”。
-
250 收藏
-
103 收藏
-
389 收藏
-
428 收藏
-
222 收藏
-
429 收藏
-
432 收藏
-
文章 · python教程 | 1天前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig324 收藏
-
435 收藏
-
478 收藏
-
文章 · python教程 | 1星期前 | 异步编程 · 后端工程 · Python教程 · asyncio · 超时排查 · Python 超时控制 asyncio 任务取消 wait_for 异步清理320 收藏
-
321 收藏
-
365 收藏
-
文章 · python教程 | 1星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory228 收藏
-
文章 · python教程 | 1星期前 | 重试机制 · timeout · requests · Python教程 · 接口调试 · Python Http请求 Requests timeout retry 接口排查330 收藏
-
299 收藏
-
308 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习