Python sched 定时任务小实验:注册任务、轮询运行和失败重试
来源:17golang原创
时间:2026-06-29 10:19:36 432浏览 收藏
有些本地自动化脚本不需要 Celery、APScheduler 或系统级计划任务。比如每隔几秒刷新一次状态、延迟几秒再处理一个文件、在小工具里排几个一次性动作,这类场景用 Python 标准库 sched 就能完成。
本文按“后端实验室”的方式做一个小实验:先注册几个定时任务,再用轮询循环驱动调度器,随后加入周期任务和失败重试,最后用输出结果确认它是否按预期工作。
- 前置条件:sched 适合什么场景
- 初始化:准备任务函数和 sched 调度器
- 编写代码:一次性任务和轮询循环
- 运行检查:确认顺序、延迟和输出
- 扩展实验:给失败任务加一次重试
- 清理总结:哪些边界不要忽略
前置条件:sched 适合什么场景
sched 是 Python 标准库里的轻量调度器。它负责按时间顺序保存任务,到点后调用对应函数。它不自带持久化、不负责跨进程协调,也不适合承载大量线上任务。
适合使用它的场景通常有三个特点:
- 任务数量少,运行在单个 Python 进程里。
- 任务可以接受秒级延迟,不要求毫秒级精度。
- 重启后任务丢失可以接受,或者任务可由上层逻辑重新注册。
本实验只需要 Python 3、终端和一个空目录。代码只使用标准库,不需要额外安装依赖。
初始化:准备任务函数和 sched 调度器
先准备一个最小版本:两个任务分别在 1 秒和 3 秒后运行。sched.scheduler 需要两个函数:一个用来获取当前时间,一个用来等待。这里用 time.monotonic 和 time.sleep,避免系统时间调整影响相对延迟。
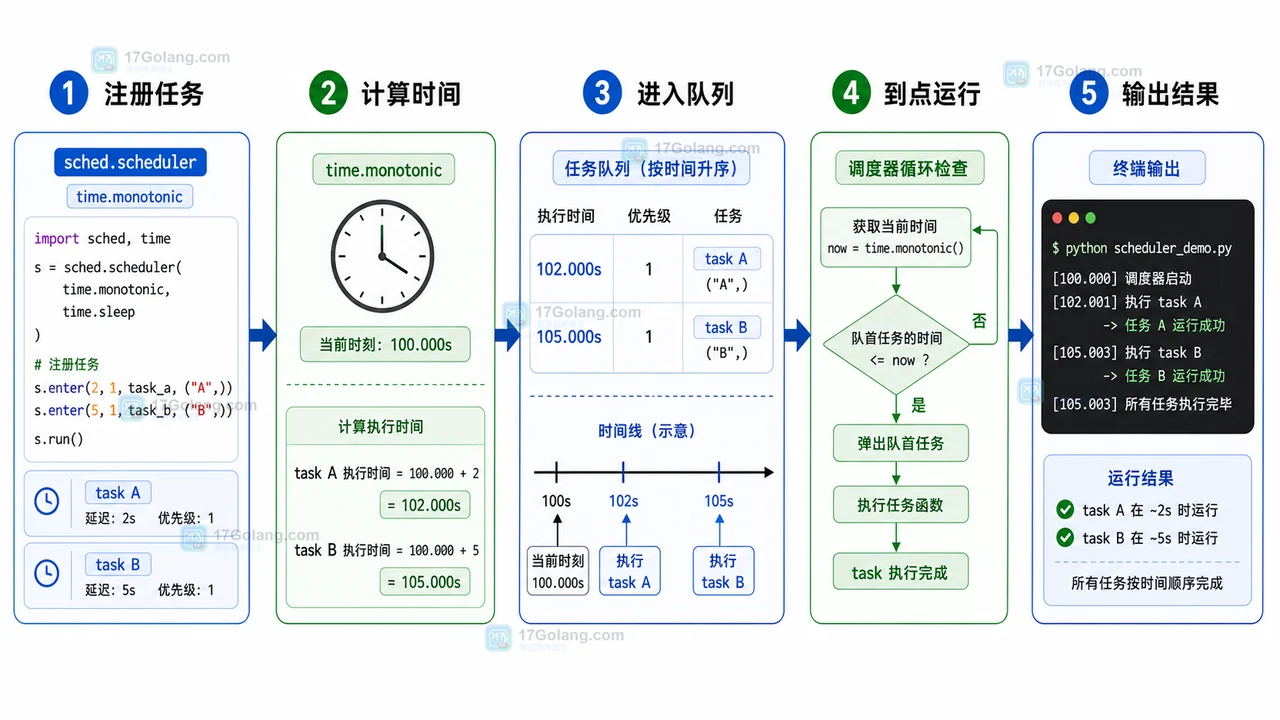
import sched
import time
timer = sched.scheduler(time.monotonic, time.sleep)
def log_line(name: str) -> None:
now = time.strftime("%H:%M:%S")
print(f"[{now}] {name}")
timer.enter(delay=1, priority=1, action=log_line, argument=("task A",))
timer.enter(delay=3, priority=1, action=log_line, argument=("task B",))
timer.run()
delay 表示从当前时间往后推多少秒,priority 用来处理同一时刻的多个任务,数字越小越先运行。action 是到点后调用的函数,argument 是传给函数的位置参数。
编写代码:一次性任务和轮询循环
直接调用 timer.run() 会阻塞到队列清空。很多本地工具还要同时处理键盘输入、文件扫描或网络轮询,所以更常见的方式是用 blocking=False 做非阻塞检查。
import sched
import time
timer = sched.scheduler(time.monotonic, time.sleep)
def log_line(name: str) -> None:
now = time.strftime("%H:%M:%S")
print(f"[{now}] {name}")
def add_once(delay: int, name: str) -> None:
timer.enter(delay, 1, log_line, argument=(name,))
def run_loop(seconds: int) -> None:
end_at = time.monotonic() + seconds
while time.monotonic()
这段代码的关键是固定轮询间隔。timer.run(blocking=False) 只会运行已经到点的任务,不会在下一个任务前一直等待;循环里的 sleep(0.2) 用来避免 CPU 空转。
加入周期任务
sched 没有内置 cron 表达式,但可以在任务函数末尾重新注册自己,从而形成周期任务。
def every(seconds: int, name: str) -> None:
def job() -> None:
log_line(name)
timer.enter(seconds, 1, job)
timer.enter(seconds, 1, job)
every(2, "heartbeat")
run_loop(7)
这种写法的优点是简单直观,缺点也要明确:如果任务本身运行很久,下一次注册时间会被推迟。对于本地脚本这通常可以接受;如果要严格固定时间点,就需要更完整的调度框架。
运行检查:确认顺序、延迟和输出
先保存为 mini_timer.py,再运行:
python mini_timer.py
你应该能看到类似输出:
[10:12:01] check config [10:12:02] refresh cache [10:12:04] write report
检查时关注三点:
- 顺序是否和 delay 一致。
- 程序是否在任务队列清空后退出。
- 轮询间隔是否过小导致 CPU 占用异常。
如果输出顺序不符合预期,先看注册任务时的 delay 和 priority。如果程序迟迟不退出,通常是周期任务一直重新注册,需要给循环设置结束条件。
扩展实验:给失败任务加一次重试
定时任务最容易被忽略的是失败边界。下面模拟一个任务第一次失败,3 秒后重试一次,第二次成功。
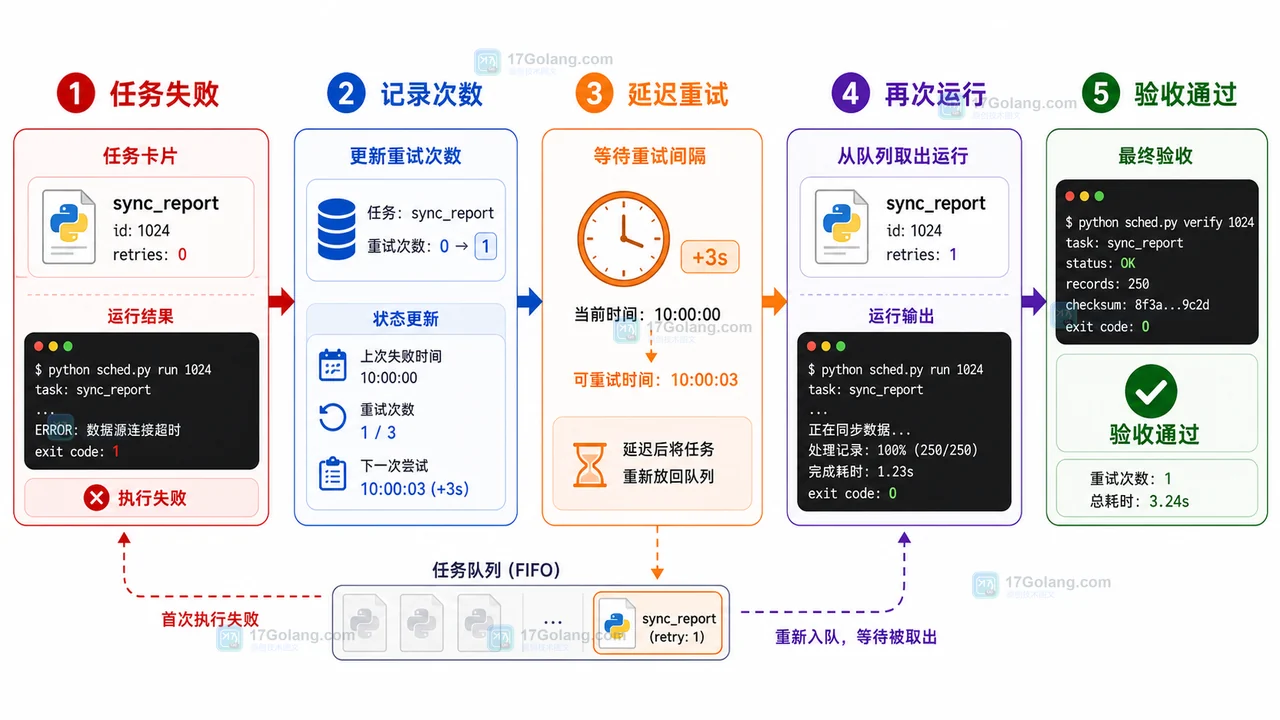
attempts = {"sync_report": 0}
def sync_report() -> None:
attempts["sync_report"] += 1
count = attempts["sync_report"]
if count == 1:
print("[warn] sync_report failed, retry after 3s")
timer.enter(3, 1, sync_report)
return
print("[ok] sync_report finished")
timer.enter(1, 1, sync_report)
run_loop(6)
预期输出如下:
[warn] sync_report failed, retry after 3s [ok] sync_report finished
真实项目里不要无限重试。可以给任务记录最大次数,例如最多 3 次;超过次数后打印错误日志,或者把任务写入待人工处理的文件。这样脚本不会因为一个坏任务一直占用运行时间。
清理总结:哪些边界不要忽略
这个小实验可以帮我们理解 sched 的使用边界:
- 它适合单进程、本地、小规模任务,不适合分布式任务队列。
- 任务函数不要阻塞太久,否则后面的任务会被拖慢。
- 周期任务要有停止条件,尤其是在测试脚本里。
- 失败重试要限制次数,并把最终失败记录清楚。
- 如果任务必须跨重启保留,需要把任务状态放到文件、数据库或更专业的任务系统里。
总结一下,sched 的价值不是替代大型调度平台,而是给小工具一个足够清晰的时间队列。注册任务、轮询运行、观察输出、再补失败重试,这条路径很适合快速完成本地自动化实验。
-
131 收藏
-
166 收藏
-
文章 · python教程 | 3星期前 | 日志 · 工程化 · 异步编程 · 故障排查 · 可观测性 · Python教程 · Python 异步任务 可观测性 logging contextvars 生产实践 QueueHandler QueueListener request_id JSON日志189 收藏
-
196 收藏
-
208 收藏
-
196 收藏
-
文章 · python教程 | 1天前 | logging · Python教程 · 后端开发 · 日志排查 · Python logging 日志重复 propagate addHandler basicConfig324 收藏
-
435 收藏
-
478 收藏
-
文章 · python教程 | 1星期前 | 异步编程 · 后端工程 · Python教程 · asyncio · 超时排查 · Python 超时控制 asyncio 任务取消 wait_for 异步清理320 收藏
-
321 收藏
-
365 收藏
-
文章 · python教程 | 1星期前 | 默认值 · python · 数据建模 · dataclass · default_factory · field · Python 数据类 Field 可变默认值 dataclass default_factory228 收藏
-
文章 · python教程 | 1星期前 | 重试机制 · timeout · requests · Python教程 · 接口调试 · Python Http请求 Requests timeout retry 接口排查330 收藏
-
299 收藏
-
308 收藏
-
209 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习