Linux 服务反复重启怎么办:journalctl 和 RestartSec 排查清单
来源:17golang原创
时间:2026-07-01 17:17:00 408浏览 收藏
Linux 服务交给 systemd 托管后,最常见的故障之一是“刚启动就退出,然后被系统反复拉起,最后变成 failed”。这类问题不要先猜配置,也不要盲目重启服务器;更稳的做法是先看 systemctl status 的结果,再用 journalctl -u 找到退出原因,最后调整重启策略、清除失败计数并做一次可回滚验证。
- systemd 重启策略解决什么问题
- 哪些服务适合打开自动重启
- 最小示例:从 start-limit-hit 看故障链路
- 排查命令:先确认退出原因再改策略
- 修复流程:重载、清计数、重启验证和回滚
- 不同系统里的兼容细节
- 线上注意事项:避免把故障放大
systemd 重启策略解决什么问题
systemd 的自动重启能力,适合处理“进程短暂异常退出后可以重新拉起”的场景。例如应用依赖的临时连接抖动、进程被信号结束、配置热更新后短时间失败,都可能通过一次重启恢复。
但它不是万能修复器。如果服务每次启动都因为配置缺失、端口占用、权限不足而立刻退出,自动重启只会把同一个错误快速重复多次。达到 systemd 的启动限流阈值后,服务就会进入 failed,常见结果里会看到 start-limit-hit。
所以这篇文章的核心思路是:自动重启负责兜底,日志负责定位根因,限流负责避免无意义重试,回滚负责保证修复动作可撤回。
哪些服务适合打开自动重启
不是所有服务都应该打开强力自动重启。建议先按服务类型判断:
| 服务类型 | 是否适合 | 建议策略 |
|---|---|---|
| 无状态 Web API | 适合 | 异常退出后自动拉起,并配合健康检查 |
| 消费队列 Worker | 适合但要谨慎 | 重启前保证任务幂等,避免重复处理 |
| 一次性迁移脚本 | 不适合 | 失败后停住,让运维先看日志 |
| 数据库或状态型组件 | 谨慎 | 优先使用官方服务管理方式和恢复流程 |
如果服务启动失败会继续写坏数据、重复扣减、反复调用外部接口,就不要只靠 systemd 拉起。先把应用侧的幂等、锁、状态检查做好,再考虑重启策略。
最小示例:从 start-limit-hit 看故障链路
假设 myapp.service 每次启动都读不到配置文件,进程立刻退出。Unit 文件里又配置了自动重启,于是 systemd 会不断尝试拉起它,直到触发启动限流。
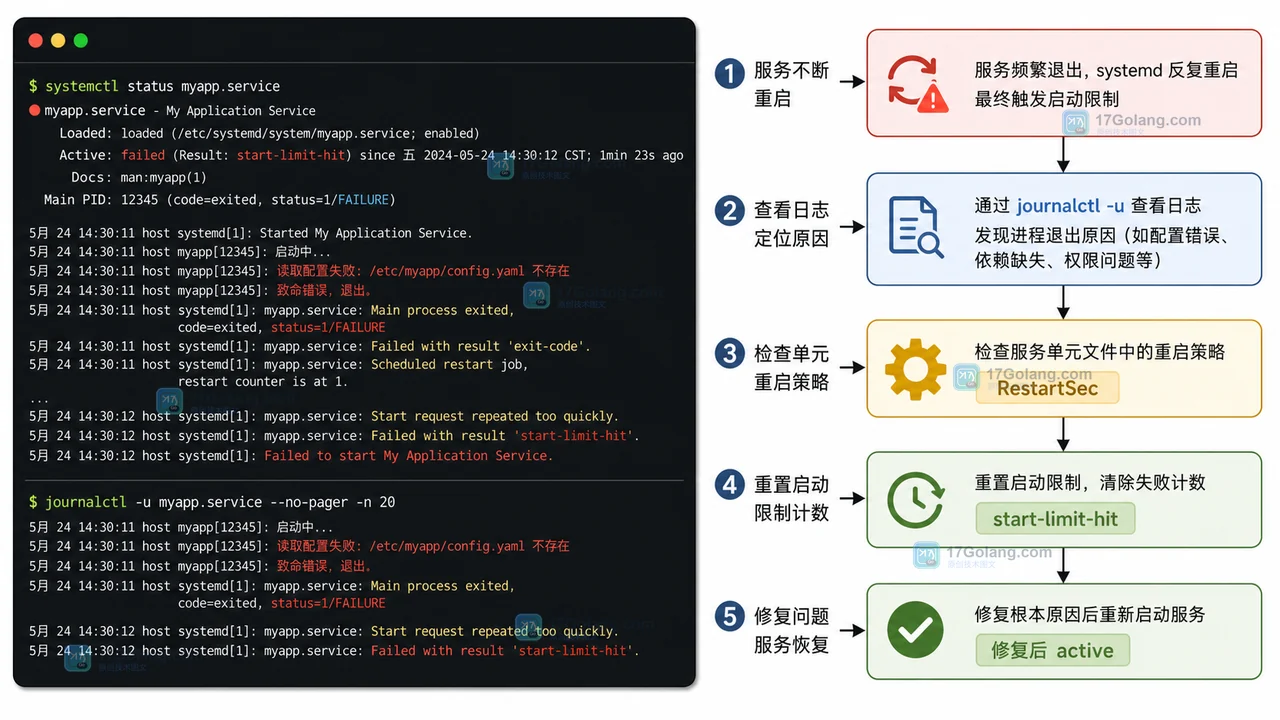
现场通常会有三类信号:
Active: failed表示服务当前没有正常运行。Result: start-limit-hit表示短时间启动失败次数过多,systemd 暂停继续拉起。Main process exited或应用自己的日志,会指向真正的退出原因。
很多人看到 start-limit-hit 后只记得执行 systemctl reset-failed。这只能清掉失败计数,不能修复根因。如果配置文件仍然缺失,服务很快又会回到同一个状态。
排查命令:先确认退出原因再改策略
建议把排查顺序固定下来,先看概览,再看当前服务日志,最后检查 Unit 配置。
1. 看服务当前状态
sudo systemctl status myapp.service --no-pager
重点看 Active、Result、最近几行日志和主进程退出状态。状态页只能告诉你“系统看到什么”,不一定能告诉你“应用为什么退出”。
2. 看服务日志
sudo journalctl -u myapp.service --no-pager -n 80 sudo journalctl -u myapp.service -f
如果日志里出现配置文件不存在、端口已占用、权限不足、依赖连接失败,就应该先修这些根因。不要把 RestartSec 改得更短,也不要把启动限流调得很高来掩盖错误。
3. 查看 Unit 里的重启相关字段
sudo systemctl cat myapp.service
常见需要确认的字段包括:
Restart:进程以什么结果退出时自动重启。RestartSec:两次重启之间等待多久。StartLimitBurst:一个时间窗口内允许失败几次。StartLimitIntervalSec:启动限流统计窗口。
这里故意先看日志再看策略,是为了避免把“应用配置错误”误当成“systemd 策略错误”。策略只决定是否重试、隔多久重试、什么时候停住;真正退出原因仍然在应用日志和环境里。
修复流程:重载、清计数、重启验证和回滚
确认根因后,再进入修复。以配置文件缺失为例,应该先补齐配置或修正环境文件,再重载 systemd 管理器,清除失败计数,最后重启并跟日志。
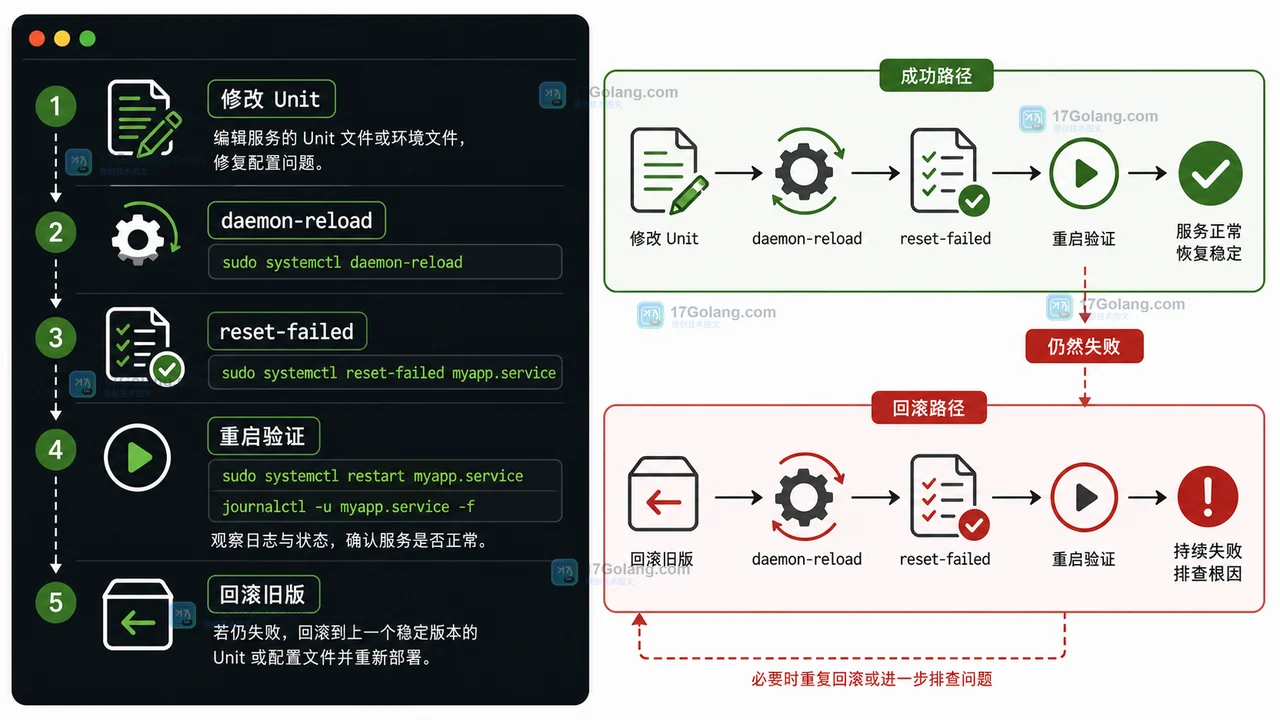
sudo systemctl daemon-reload sudo systemctl reset-failed myapp.service sudo systemctl restart myapp.service sudo systemctl status myapp.service --no-pager sudo journalctl -u myapp.service -f
如果修改后服务恢复为 active,再观察一段时间的日志和业务指标。若仍然失败,先按发布系统或配置管理系统的方式回滚到上一版稳定 Unit 或环境文件,再继续排查。
线上建议保留一个简单的修复记录:
- 失败时的
Result和最近日志片段。 - 修改了哪个 Unit 或环境文件。
- 是否执行过
daemon-reload和reset-failed。 - 重启后服务状态、端口监听、健康检查和核心业务指标。
不同系统里的兼容细节
不同 Linux 发行版和 systemd 版本,对启动限流字段的支持细节可能略有差异。常见处理原则如下:
- 优先使用
systemctl cat 服务名查看最终生效配置,避免只看源码文件。 - 修改 Unit 后必须执行
systemctl daemon-reload,否则 systemd 可能仍使用旧配置。 - 如果服务由包管理器安装,尽量使用 drop-in 覆盖文件,而不是直接改包自带 Unit。
- 旧系统上字段名或默认值可能不同,遇到不生效时用
man systemd.unit和man systemd.service对照当前机器。
drop-in 的好处是变更更清晰,也不容易被软件包升级覆盖。常见命令是:
sudo systemctl edit myapp.service
然后只覆盖需要调整的重启策略。调整完成后仍然要重载、清计数、重启验证。
线上注意事项:避免把故障放大
自动重启策略设置太激进,会把一个普通故障放大成资源风暴。生产环境尤其要注意下面几件事。
不要把 RestartSec 设得过短
如果服务依赖数据库、Redis、配置中心或外部接口,连续快速重启可能让依赖雪上加霜。一般建议留出几秒到几十秒的间隔,再配合应用自己的退避逻辑。
不要只清失败计数
reset-failed 是恢复手段,不是诊断手段。它适合在根因已经修好后使用,帮助 systemd 重新允许启动;如果根因没修好,清计数只会让同一轮失败重演。
不要忽略业务验证
服务进程变成 active,不代表业务已经恢复。还要看端口、健康检查、请求错误率、队列堆积和关键日志。对 Web 服务来说,至少要确认入口能返回正常响应;对 Worker 来说,还要确认任务消费速度恢复。
总结
systemd 服务反复重启的排查,可以按一条稳定链路走:先用 systemctl status 看系统视角,再用 journalctl -u 找应用退出原因,然后检查 Restart、RestartSec 和启动限流字段。根因修复后,执行 daemon-reload、reset-failed、重启验证,并准备好回滚路径。这样处理,自动重启就会成为服务韧性的一部分,而不是把错误重复放大的开关。
-
100 收藏
-
100 收藏
-
101 收藏
-
102 收藏
-
104 收藏
-
399 收藏
-
120 收藏
-
文章 · linux | 1星期前 | Linux · inode · 日志清理 · 磁盘排查 · 服务器运维 · Linux inode 磁盘空间 df du lsof No space left on device335 收藏
-
422 收藏
-
文章 · linux | 1星期前 | 服务器 · Linux · ssh · 运维排查 · 登录慢 · Linux SSH pam sshd_config 登录慢 UseDNS GSSAPI 密钥权限153 收藏
-
文章 · linux | 2星期前 | Linux · 运维排查 · 文件句柄 · ulimit · 服务限制 · Linux 文件句柄 lsof ulimit too many open files LimitNOFILE 服务限制482 收藏
-
文章 · linux | 2星期前 | Linux · 运维 · 性能排查 · 磁盘IO · iostat · pidstat · Linux 性能排查 iostat 磁盘IO pidstat %util260 收藏
-
335 收藏
-
284 收藏
-
286 收藏
-
494 收藏
-
360 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习