用python创建AI训练玩贪吃蛇的方法
来源:网易伏羲
时间:2024-02-07 14:11:01 453浏览 收藏
golang学习网今天将给大家带来《用python创建AI训练玩贪吃蛇的方法》,感兴趣的朋友请继续看下去吧!以下内容将会涉及到等等知识点,如果你是正在学习文章或者已经是大佬级别了,都非常欢迎也希望大家都能给我建议评论哈~希望能帮助到大家!
这是关于如何使用强化学习训练AI玩贪吃蛇游戏的简单指南。文章逐步展示了如何设置自定义游戏环境并使用python标准化Stable-Baselines3算法库训练AI玩贪吃蛇。
在本项目中,我们使用的是Stable-Baselines3,这是一个标准化的库,它提供了易于使用的基于PyTorch的强化学习(RL)算法实现。
首先,设置环境。Stable-Baselines库内有很多内置的游戏环境,这里我们使用经典贪吃蛇的修改版本,并在中间额外设置十字交叉的墙。
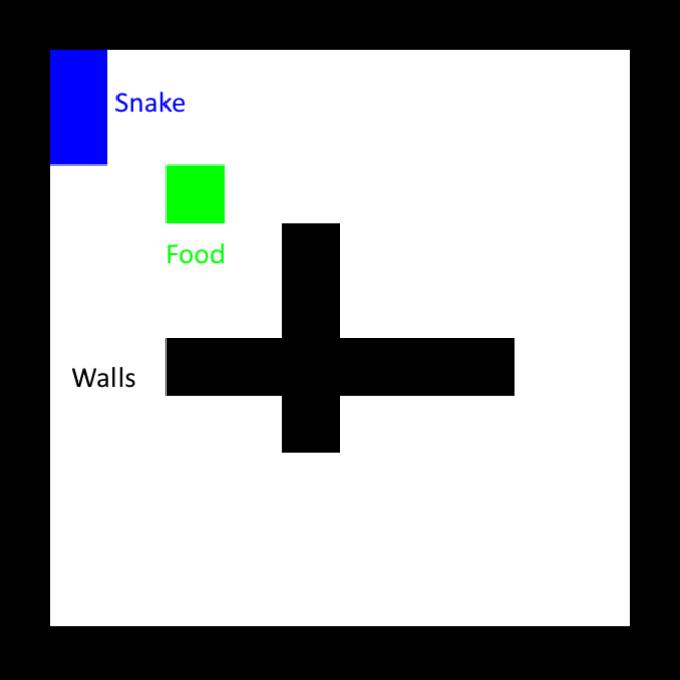
一个更好的奖励计划是只奖励更接近食物的步骤。在这里必须小心,因为贪吃蛇仍然只能学会绕圈走动,在接近食物时获得奖励,然后转身又回来。为了避免这种情况,我们还必须对远离食物给予等效的惩罚,换句话说,我们需要确保闭环上的净奖励为零。我们还需要引入对撞墙的惩罚,因为在某些情况下,贪吃蛇会选择撞墙来接近食物。
大多数机器学习算法都相当复杂且难以实现。幸运的是,Stable-Baselines3已经实现了几种我们可以使用的最先进的算法。在示例中,我们将使用Proximal Policy Optimization(PPO)。虽然我们不需要知道算法如何工作的细节(如果有兴趣,请看这个解释视频),但我们需要对它的超参数是什么以及它们的作用有一个基本的了解。幸运的是,PPO只有其中一些,我们将使用以下内容:
learning_rate:设置策略更新的步骤有多大,与其他机器学习方案相同。将其设置得太高会阻止算法找到正确的解决方案,甚至将算法推向一个永远无法恢复的方向。将其设置得太低会使训练花费更长的时间。一个常见的技巧是在训练期间使用调度器函数来调整它。
gamma:未来奖励的折扣系数,介于0(仅即时奖励重要)和1(未来奖励与即时奖励价值相同)之间。为了保持训练效果,最好将其保持在0.9以上。
clip_range1+-clip_range:PPO的一个重要特性,它的存在是为了确保模型不会在训练时发生显着改变。减少它有助于在后期训练阶段微调模型。
ent_coef:从本质上讲,它的值越高,就越鼓励算法探索不同的非最优动作,这可以帮助该方案摆脱局部奖励最大值。
一般来说,从默认的超参数开始即可。
接下来的步骤是针对一些预先确定的步骤进行训练,然后亲自查看算法的运行情况,然后使用性能最佳的可能的新参数重新开始。在这里,我们绘制了不同训练时间的奖励。
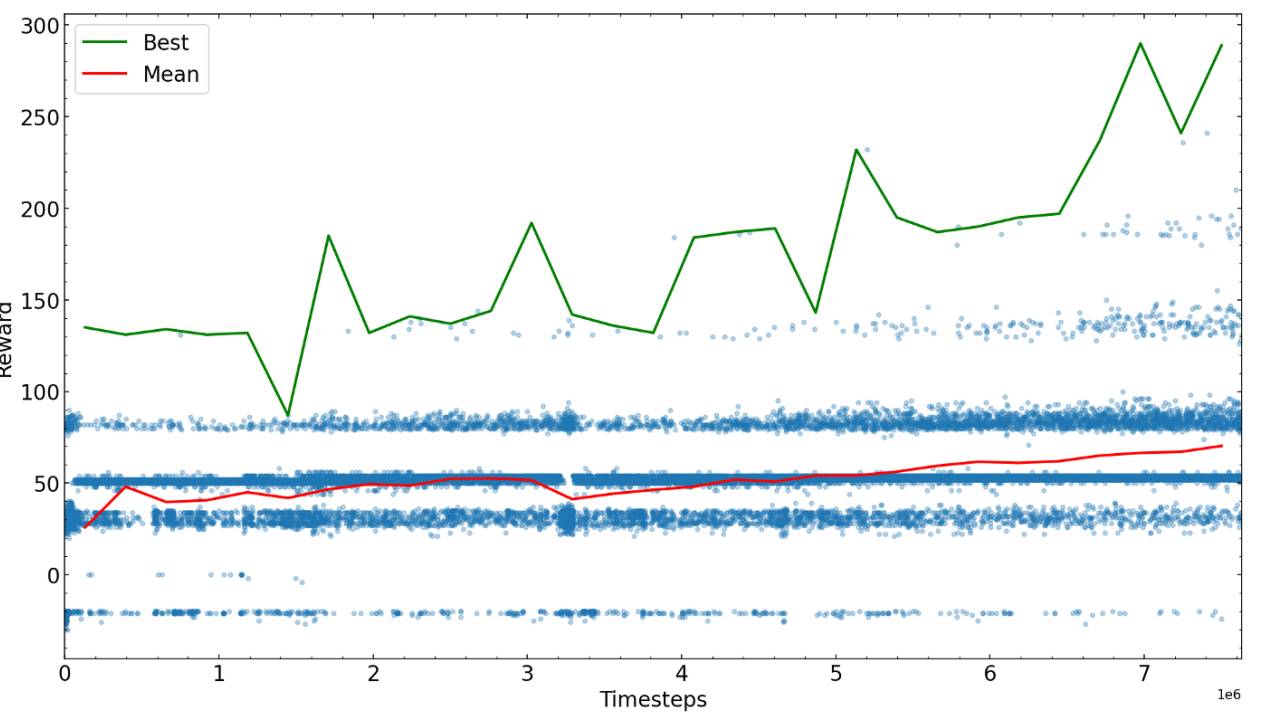
经过足够多的步骤后,训练贪吃蛇的算法收敛到某个奖励值,就可以完成训练或尝试微调参数并继续训练。
达到最大可能奖励所需的训练步骤很大程度上取决于问题、奖励方案和超参数,因此建议在训练算法前先优化一下。在训练AI玩贪吃蛇游戏示例的最后,我们发现AI已经能做到在迷宫中找到食物并避免与尾巴相撞了。
今天关于《用python创建AI训练玩贪吃蛇的方法》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
文章 · python教程 | 1天前 | 异步编程 · 生产实践 · 后端工程 · Python教程 · Celery · 任务队列 · Python 故障排查 任务队列 异步任务 幂等 生产实践 Celery 5.4 retry_backoff acks_late340 收藏
-
文章 · python教程 | 1天前 | 工程化 · 性能优化 · 内存分析 · 故障排查 · 生产实践 · Python教程 · Python 故障排查 内存泄漏 rss 性能优化 GC tracemalloc 生产实践 snapshot diff230 收藏
-
文章 · python教程 | 1天前 | 日志 · 工程化 · 异步编程 · 故障排查 · 可观测性 · Python教程 · Python 异步任务 可观测性 logging contextvars 生产实践 QueueHandler QueueListener request_id JSON日志427 收藏
-
文章 · python教程 | 4天前 | 日志 · 工程化 · 异步编程 · 故障排查 · 可观测性 · Python教程 · Python 异步任务 可观测性 logging contextvars 生产实践 QueueHandler QueueListener request_id JSON日志189 收藏
-
文章 · python教程 | 5天前 | 依赖管理 · 工程化 · CI · 生产实践 · Python教程 · 打包发布 · Python build 依赖管理 twine wheel 打包发布 pyproject.toml dependency-groups pylock.toml sdist479 收藏
-
文章 · python教程 | 5天前 | WEB开发 · 工程化 · 配置管理 · flask · 生产实践 · Python教程 · Python Flask G 配置管理 请求上下文 应用上下文 生产实践 current_app teardown app factory257 收藏
-
文章 · python教程 | 5天前 | ORM · Django · 异步编程 · 生产实践 · Python教程 · 后端开发 · Python Django 性能优化 orm 事务 ASGI 生产实践 async view sync_to_async310 收藏
-
文章 · python教程 | 5天前 | 性能优化 · 异步编程 · fastapi · 生产实践 · Python教程 · API服务 · Python API服务 FastAPI asyncio httpx 生产实践 lifespan BackgroundTasks run_in_threadpool411 收藏
-
文章 · python教程 | 6天前 | 工程化 · 自动化测试 · pytest · CI · 生产实践 · Python教程 · Python CI pytest fixture tmp_path monkeypatch pytest-xdist 测试稳定性303 收藏
-
文章 · python教程 | 6天前 | sqlalchemy · 异步编程 · fastapi · 生产实践 · Python教程 · Python 连接池 FastAPI sqlalchemy asyncio AsyncSession340 收藏
-
文章 · python教程 | 6天前 | 性能优化 · fastapi · 生产实践 · Python教程 · Pydantic · Python 性能优化 FastAPI Pydantic v2 TypeAdapter validate_json342 收藏
-
文章 · python教程 | 6天前 | 性能优化 · gil · 生产实践 · Python教程 · CPython · Python 性能优化 线程安全 gil CPython free-threaded381 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习