ScreenAgent
工具简介
ScreenAgent是由吉林大学人工智能学院与知识驱动的人工智能教育部工程研究中心联合开发的视觉语言模型(VLM)智能体。通过观察和理解计算机屏幕截图,ScreenAgent能够生成并执行鼠标和键盘动作,完成多步骤任务。该智能体利用强化学习环境和VNC协议进行训练,并通过ScreenAgent数据集和CC-Score指标进行评估,适用于自动化各种日常计算机任务,提升操作效率。
详细介绍
新介绍内容:
ScreenAgent:吉林大学研发的视觉语言模型智能体,实现计算机屏幕自动化操作
ScreenAgent是由吉林大学人工智能学院与知识驱动的人工智能教育部工程研究中心联合开发的一个创新性计算机控制智能体。它基于视觉语言模型(VLM),能够与真实计算机屏幕进行交互,执行复杂的多步骤任务。
主要特点:
- 视觉语言模型(VLM): 结合了先进的视觉和语言处理技术,能够解析屏幕截图并理解任务提示。
- 强化学习环境: 通过VNC协议与计算机屏幕交互,构建了高效的强化学习环境,用于训练智能体。
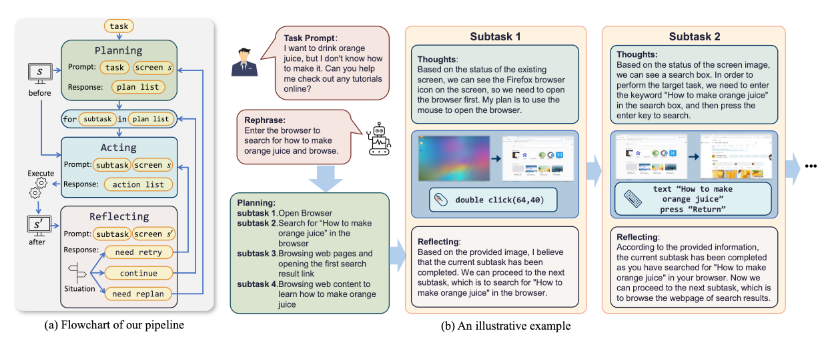
- 控制流程: 包括计划、执行和反思三个阶段,确保智能体能够持续优化与环境的交互。
- 数据集和评估: ScreenAgent数据集涵盖多种日常计算机任务的屏幕截图和动作序列,并通过CC-Score指标进行评估。
主要功能:
- 屏幕观察: 智能体能够观察和理解计算机屏幕截图,获取实时信息。
- 动作生成: 根据屏幕截图生成鼠标和键盘动作的JSON格式命令序列,精确控制操作。
- 任务规划: 将复杂任务分解为子任务,并规划相应的动作序列,确保任务顺利完成。
- 执行动作: 通过发送鼠标和键盘动作命令到计算机,执行用户指定的任务。
- 反思评估: 评估执行结果,根据反馈决定后续行动,优化操作流程。
使用示例:
- 屏幕观察: ScreenAgent实时观察桌面操作系统的屏幕图像,获取最新状态。
- 动作生成: 根据屏幕截图生成移动鼠标、点击、滚动等动作命令,确保操作精准。
- 任务规划: 将用户任务如“打开网页浏览器”分解为具体步骤,制定详细的操作计划。
- 执行动作: 执行打开浏览器、输入网址、搜索信息等动作,完成用户需求。
- 反思评估: 在尝试打开网页后,评估操作是否成功,若未成功则决定是否需要重试。
总结:
ScreenAgent作为一个先进的计算机控制智能体,通过观察屏幕截图和执行鼠标键盘动作,能够完成复杂的多步骤任务。其利用视觉语言模型和强化学习环境,在真实计算机屏幕上实现了高效的自动化操作。ScreenAgent的控制流程和评估指标使其成为一个强大的工具,能够自动化各种数字任务,显著提高操作效率和便利性。
相关工具

Open Voice OS
Open Voice OS:社区驱动的高度自定义开源语音AI平台

豆包MarsCode代码练习
豆包MarsCode:AI赋能的代码练习平台,助你高效掌握算法

小浣熊AI助手
小浣熊AI助手:提升软件开发和数据分析效率的智能工具

AI开搭
AI开搭:一站式AI开发工具,无需编程即可搭建AI系统
Plandex
Plandex:终端AI编程引擎,提升开发效率的开源工具

Tabby
Tabby:自托管AI编程助手,提升开发效率的开源解决方案
iFlyCode
iFlyCode:科大讯飞智能编程助手,提升编程效率
JetBrains AI
JetBrains AI:提升开发效率的智能工具

CodeGeeX
CodeGeeX:AI编程助手,提升开发效率的利器
JamGPT
JamGPT:开发团队的错误报告利器