Follow Your Pose
工具简介
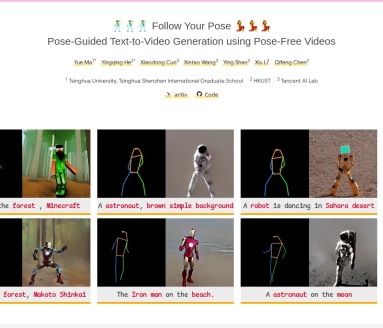
探索Follow Your Pose,由清华大学、香港科技大学、腾讯AI Lab及中科院联合开发的文本到视频生成框架。通过文本描述和姿态序列生成高质量、时间连贯的视频,支持多角色、多风格和多背景的视频内容。
详细介绍
Follow Your Pose:创新文本到视频生成框架,精准姿态控制
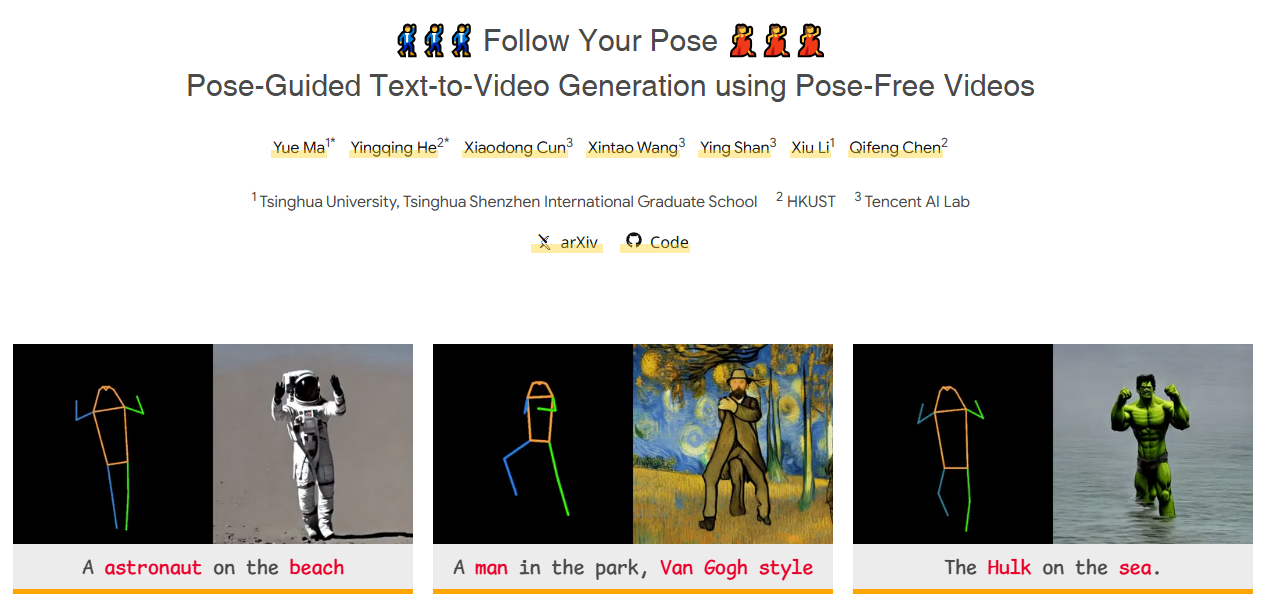
Follow Your Pose是由清华大学、香港科技大学、腾讯AI Lab以及中科院的研究人员共同开发的文本到视频生成框架。该框架通过结合文本描述和指定的人物姿态序列,生成高质量、时间连贯的视频内容,满足用户对视频生成的多样化需求。
核心优势:
- 文本到视频生成:用户输入文本描述,框架自动生成与描述相符的视频。
- 精准姿态控制:通过指定人物姿态序列,用户可以精确控制视频中角色的动作细节。
- 时间连贯性:生成的视频在时间上连贯,动作和场景变化自然流畅。
- 多样化角色和背景:支持生成不同外观、风格和背景的视频内容。
- 多角色视频生成:在同一个视频中展示多个角色,增强视频的丰富性。
- 风格化视频生成:用户可以选择生成具有特定艺术风格的视频,如卡通、赛博朋克等。
主要功能:
- 文本输入:用户通过输入文本描述来定义视频内容。
- 姿态序列指定:用户可以控制视频中角色的动作细节,实现精准的姿态控制。
- 高质量视频生成:生成与文本描述和姿态序列高度一致的高质量视频。
- 多样化风格和背景:支持生成多种风格和背景的视频内容,满足不同需求。
- 多角色协同:在视频中同时展示和控制多个角色,增强视频的互动性和复杂性。
使用示例:
- 生成特定风格视频:
- 用户输入文本描述和相应的姿态序列,框架生成具有卡通风格或赛博朋克风格等特定艺术风格的视频。
- 控制视频中的多个角色:
- 用户为视频中的每个角色指定不同的动作和身份,框架生成包含这些指定动作和角色的视频。
- 生成连贯性视频:
- 用户输入一系列姿态和文本描述,框架生成时间上连贯、动作流畅的视频。
总结:
Follow Your Pose是一个创新的文本到视频生成框架,通过两阶段训练策略实现了高度的姿态控制和时间连贯性。该框架不仅能够根据文本描述生成视频,还能让用户通过姿态序列精确控制视频中角色的动作,生成具有多样化角色、背景和风格的视频内容。这使得Follow Your Pose成为一个功能强大且灵活的视频生成工具,适用于需要对视频内容进行精细控制的应用场景。
相关工具

Open Voice OS
Open Voice OS:社区驱动的高度自定义开源语音AI平台

豆包MarsCode代码练习
豆包MarsCode:AI赋能的代码练习平台,助你高效掌握算法

小浣熊AI助手
小浣熊AI助手:提升软件开发和数据分析效率的智能工具

AI开搭
AI开搭:一站式AI开发工具,无需编程即可搭建AI系统
Plandex
Plandex:终端AI编程引擎,提升开发效率的开源工具

Tabby
Tabby:自托管AI编程助手,提升开发效率的开源解决方案
iFlyCode
iFlyCode:科大讯飞智能编程助手,提升编程效率
JetBrains AI
JetBrains AI:提升开发效率的智能工具

CodeGeeX
CodeGeeX:AI编程助手,提升开发效率的利器
JamGPT
JamGPT:开发团队的错误报告利器