AtomoVideo
工具简介
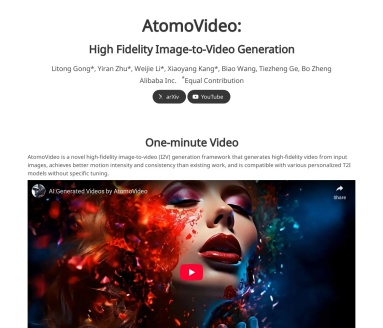
探索AtomoVideo,一款先进的图像到视频(I2V)生成框架,实现高保真视频生成。适用于内容创作、广告制作、教育和艺术领域,支持多种个性化文本到图像模型,带来更强的运动强度和一致性。
详细介绍

AtomoVideo:高保真图像到视频生成框架,革新您的内容创作
AtomoVideo是一款革命性的图像到视频(Image-to-Video, I2V)生成框架,专为从静态图像生成高保真视频而设计。它不仅在运动强度和一致性方面表现优异,还能无缝兼容多种个性化的文本到图像(T2I)模型,无需特定调整。
核心优势:
- 高保真视频生成: 通过多粒度图像注入技术,AtomoVideo确保生成的视频与输入图像的高度一致性,提供卓越的视觉体验。
- 更强的运动强度: 得益于高质量的数据集和训练策略,AtomoVideo在保持优越的时间一致性和稳定性的同时,实现了更大的运动强度。
- 灵活的架构扩展: 该架构可以灵活地扩展到视频帧预测任务,支持长序列预测,满足多样化需求。
- 兼容性与可组合性: AtomoVideo通过适配器训练设计,可以与现有的个性化模型和可控模块无缝结合,提升生成效果。
强大功能:
- 图像信息注入: 通过修改输入通道为9通道,添加图像条件潜在变量和二进制掩码,AtomoVideo能够在低层次上注入图像信息,增强视频与给定图像的保真度。
- 高级图像语义注入: 以交叉注意力的形式注入高级图像语义,实现更语义化的图像可控性。
- 预训练T2I模型集成: 利用预训练的T2I模型,并在每个空间卷积和注意力层后新增1D时间卷积和时间注意力模块,固定T2I模型参数,仅训练新增的时间层。
应用场景:
- 内容创作: 内容创作者可以使用AtomoVideo从静态图像生成动态视频,为社交媒体、博客或视频项目增添生动的视觉效果。
- 广告制作: 广告公司可以利用该工具从产品图像生成吸引人的视频广告,增强广告的吸引力和影响力。
- 教育和培训: 教育工作者可以生成与教学内容相关的视频,帮助学生更好地理解和记忆知识。
- 艺术创作: 艺术家可以探索图像到视频的转换,创作独特的艺术作品,表达创意和情感。
总结:
AtomoVideo作为一款创新的图像到视频生成框架,通过先进的技术和灵活的架构,为用户提供了一种从静态图像生成高保真视频的新方法。其在运动强度和一致性方面的优势,以及与个性化模型的兼容性,使其在内容创作、广告制作、教育和艺术创作等多个领域具有广泛的应用前景。
相关工具

Open Voice OS
Open Voice OS:社区驱动的高度自定义开源语音AI平台

豆包MarsCode代码练习
豆包MarsCode:AI赋能的代码练习平台,助你高效掌握算法

小浣熊AI助手
小浣熊AI助手:提升软件开发和数据分析效率的智能工具

AI开搭
AI开搭:一站式AI开发工具,无需编程即可搭建AI系统
Plandex
Plandex:终端AI编程引擎,提升开发效率的开源工具

Tabby
Tabby:自托管AI编程助手,提升开发效率的开源解决方案
iFlyCode
iFlyCode:科大讯飞智能编程助手,提升编程效率
JetBrains AI
JetBrains AI:提升开发效率的智能工具

CodeGeeX
CodeGeeX:AI编程助手,提升开发效率的利器
JamGPT
JamGPT:开发团队的错误报告利器