DreaMoving
工具简介
DreaMoving是一个先进的视频生成工具,利用扩散模型技术生成高质量、定制化的人类视频。通过Video ControlNet和Content Guider,用户可以精确控制视频中的身份、动作和外观,适用于娱乐、教育和广告等领域。
详细介绍
DreaMoving是什么:
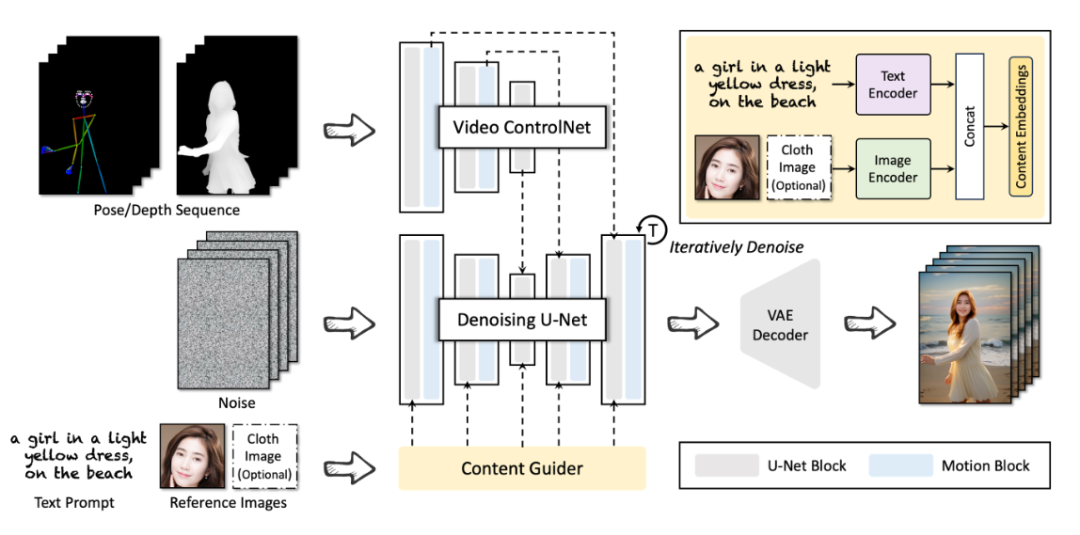
DreaMoving是一款基于扩散模型的可控视频生成框架,专为生成高质量、定制化的人类视频而设计。通过给定目标身份和姿势序列,DreaMoving能够生成目标身份在任何场景中跳舞的视频,受姿势序列驱动。为了实现这一目标,DreaMoving引入了Video ControlNet用于动作控制,以及Content Guider用于身份保持。该框架操作简便,兼容大多数风格化的扩散模型,生成多样化的视频结果。
主要特点:
- 高质量视频生成:利用指导序列和简单的内容描述(如文本和参考图像),生成高质量、高保真度的视频。
- 精确身份控制:通过面部参考图像,实现对视频中人物身份的精确控制。
- 动作操控:通过姿势序列,实现对视频中人物动作的精确控制。
- 视频外观控制:通过指定的文本提示,实现对视频整体外观的全面控制。
- 强大的泛化能力:在未见过的领域中表现出色,具有强大的泛化能力。
主要功能:
- Video ControlNet:通过在每个U-Net块后注入运动块,处理控制序列(如姿势或深度),生成额外的时间残差,实现动作控制。
- Content Guider:将输入的文本提示和外观表达(如人脸和服装)转换为内容嵌入,用于交叉注意力,实现身份保持。
- Denoising U-Net:基于Stable-Diffusion U-Net的衍生版本,包含用于视频生成的运动块。
使用示例:
- 身份控制:通过提供一个女孩的面部参考图像,DreaMoving可以生成她在不同场景中跳舞的视频,保持身份的一致性。
- 动作操控:通过输入不同的姿势序列,DreaMoving可以生成目标人物在不同场景中执行特定动作的视频。
- 视频外观控制:通过指定的文本提示,如“一个女孩,微笑着,在法国小镇跳舞,穿着浅蓝色长裙”,DreaMoving可以生成符合描述的视频。
总结:
DreaMoving是一个创新的视频生成框架,通过其独特的Video ControlNet和Content Guider,实现了对视频内容的高度控制。它不仅能够生成高质量的视频,还能在身份、动作和外观方面提供精细的控制。DreaMoving的泛化能力使其在处理未见过的领域时也能保持良好的性能,这为视频生成领域带来了新的可能性,特别是在娱乐、教育和广告等行业中具有广泛的应用前景。
相关工具

Open Voice OS
Open Voice OS:社区驱动的高度自定义开源语音AI平台

豆包MarsCode代码练习
豆包MarsCode:AI赋能的代码练习平台,助你高效掌握算法

小浣熊AI助手
小浣熊AI助手:提升软件开发和数据分析效率的智能工具

AI开搭
AI开搭:一站式AI开发工具,无需编程即可搭建AI系统
Plandex
Plandex:终端AI编程引擎,提升开发效率的开源工具

Tabby
Tabby:自托管AI编程助手,提升开发效率的开源解决方案
iFlyCode
iFlyCode:科大讯飞智能编程助手,提升编程效率
JetBrains AI
JetBrains AI:提升开发效率的智能工具

CodeGeeX
CodeGeeX:AI编程助手,提升开发效率的利器
JamGPT
JamGPT:开发团队的错误报告利器