
Loopy
工具简介
探索Loopy,字节跳动与浙江大学联合开发的音频驱动肖像头像生成模型。通过长期运动依赖和音频到潜在空间的映射,Loopy仅需音频输入即可生成逼真、自然的肖像头像视频,适用于多样化的视觉和音频风格。
详细介绍
Loopy:音频驱动的肖像头像生成模型,开启新时代
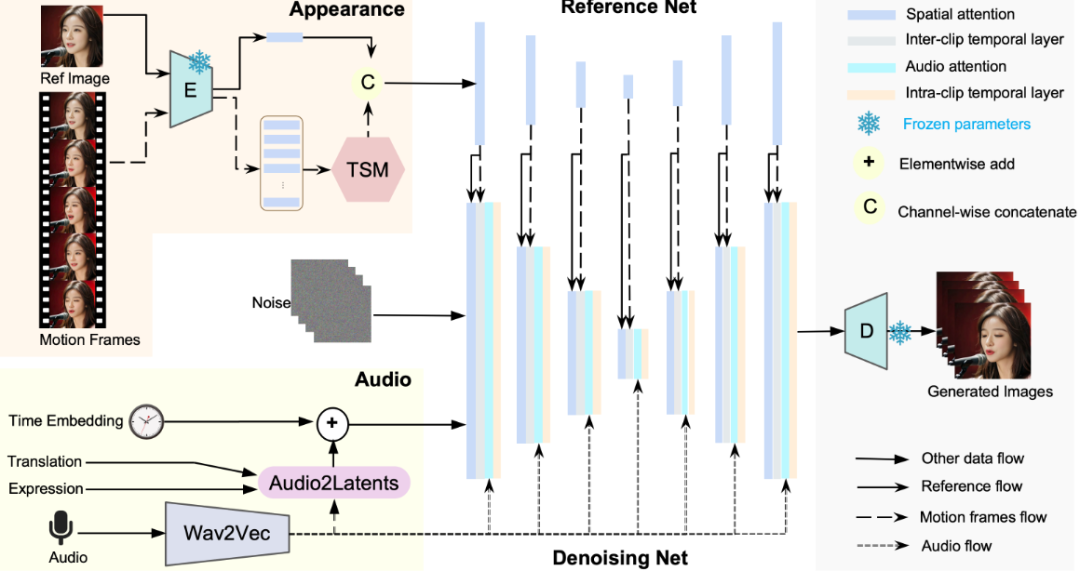
Loopy是由字节跳动和浙江大学共同研发的创新性音频驱动肖像头像生成模型。通过设计跨剪辑和剪辑内的时间模块,以及音频到潜在空间的模块,Loopy能够利用音频中的长期运动信息,生成自然且逼真的肖像头像视频。这一技术突破消除了传统方法中对空间运动模板的依赖,使得在各种场景下都能生成高质量的肖像头像。
核心特点:
- 音频驱动生成:仅通过音频输入,即可生成高质量的肖像头像视频,无需额外的空间条件。
- 长期运动依赖:通过时间模块设计,捕捉并利用音频中的长期运动信息,确保生成的肖像运动自然连贯。
- 多样化风格支持:能够处理不同的视觉和音频风格,生成适应性强的运动合成结果。
- 细节丰富的运动:从音频中生成包括非语言动作、情感驱动表情以及自然头部运动等丰富的细节。
主要功能:
- 音频到潜在空间的映射:通过音频特征映射到潜在空间,为生成肖像头像提供坚实基础。
- 时间模块设计:跨剪辑和剪辑内的时间模块,增强生成肖像的自然性和连贯性。
- 多样化肖像生成:支持生成不同视觉风格的肖像头像,包括非人类图像和侧面轮廓图像。
- 运动适应性合成:根据音频输入生成与之相匹配的运动细节,增强肖像头像的真实感。
应用示例:
- 歌唱表演肖像生成:输入歌唱音频,Loopy生成与节奏和情感相匹配的面部表情和头部运动,呈现逼真的歌唱表演。
- 非语言动作生成:通过捕捉音频中的细微变化,生成相应的非语言动作,如叹息时的眉毛微动和眼睛动作。
- 风格多样化生成:根据不同风格的音频输入,如古典音乐或流行音乐,生成相应风格的肖像头像,表现出不同的运动特性。
总结:
Loopy通过其创新的音频驱动技术和长期运动依赖,实现了仅通过音频输入生成逼真、自然的肖像头像视频。它适用于多种视觉和音频风格,提供了丰富的运动细节,为肖像头像生成领域带来了新的可能性和应用前景。
相关工具

Open Voice OS
Open Voice OS:社区驱动的高度自定义开源语音AI平台

豆包MarsCode代码练习
豆包MarsCode:AI赋能的代码练习平台,助你高效掌握算法

小浣熊AI助手
小浣熊AI助手:提升软件开发和数据分析效率的智能工具

AI开搭
AI开搭:一站式AI开发工具,无需编程即可搭建AI系统
Plandex
Plandex:终端AI编程引擎,提升开发效率的开源工具

Tabby
Tabby:自托管AI编程助手,提升开发效率的开源解决方案
iFlyCode
iFlyCode:科大讯飞智能编程助手,提升编程效率
JetBrains AI
JetBrains AI:提升开发效率的智能工具

CodeGeeX
CodeGeeX:AI编程助手,提升开发效率的利器
JamGPT
JamGPT:开发团队的错误报告利器