在2GB的DAYU200设备上本地安装大规模语言模型
来源:51CTO.COM
时间:2024-03-14 18:57:33 286浏览 收藏
学习知识要善于思考,思考,再思考!今天golang学习网小编就给大家带来《在2GB的DAYU200设备上本地安装大规模语言模型》,以下内容主要包含等知识点,如果你正在学习或准备学习科技周边,就都不要错过本文啦~让我们一起来看看吧,能帮助到你就更好了!

实现思路和步骤
将轻量级LLM模型推理框架InferLLM移植到OpenHarmony标准系统,并编译出可以在OpenHarmony上运行的二进制文件。这个推理框架是一个简单高效的LLM CPU推理框架,可以在本地部署LLM中的量化模型。
使用OpenHarmony NDK来编译OpenHarmony上的InferLLM可执行文件(具体使用OpenHarmony lycium 交叉编译框架,然后编写一些脚本。然后把其存放在tpc_c_cplusplusSIG仓库。)
在DAYU200上本地部署大语言模型
编译获取InferLLM三方库编译产物
下载OpenHarmony sdk,下载地址:
http://ci.openharmony.cn/workbench/cicd/dailybuild/dailyList
下载本仓库
git clone https://gitee.com/openharmony-sig/tpc_c_cplusplus.git --depth=1
# 设置环境变量export OHOS_SDK=解压目录/ohos-sdk/linux# 请替换为你自己的解压目录 cd lycium./build.sh InferLLM
获取InferLLM三方库头文件及生成的库
在tpc_c_cplusplus/thirdparty/InferLLM/目录下会生成InferLLM-405d866e4c11b884a8072b4b30659c63555be41d目录,该目录下存在已编译完成的32位和64位三方库。(相关编译结果不会被打包进入lycium目录下的usr目录)。
InferLLM-405d866e4c11b884a8072b4b30659c63555be41d/arm64-v8a-buildInferLLM-405d866e4c11b884a8072b4b30659c63555be41d/armeabi-v7a-build
将编译产物和模型文件推送至开发板运行
- 下载模型文件:https://huggingface.co/kewin4933/InferLLM-Model/tree/main
- 将编译InferLLM生成的llama可执行文件、OpenHarmony sdk中的libc++_shared.so、下载好的模型文件chinese-alpaca-7b-q4.bin 打包成文件夹 llama_file
# 将llama_file文件夹发送到开发板data目录hdc file send llama_file /data
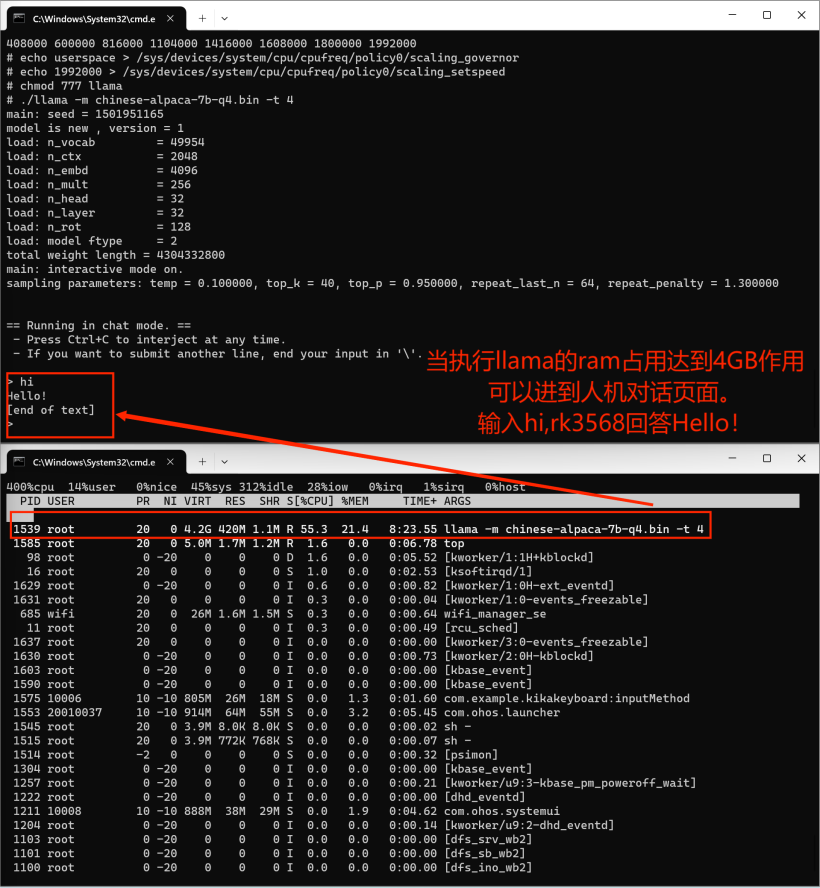
# hdc shell 进入开发板执行cd data/llama_file# 在2GB的dayu200上加swap交换空间# 新建一个空的ram_ohos文件touch ram_ohos# 创建一个用于交换空间的文件(8GB大小的交换文件)fallocate -l 8G /data/ram_ohos# 设置文件权限,以确保所有用户可以读写该文件:chmod 777 /data/ram_ohos# 将文件设置为交换空间:mkswap /data/ram_ohos# 启用交换空间:swapon /data/ram_ohos# 设置库搜索路径export LD_LIBRARY_PATH=/data/llama_file:$LD_LIBRARY_PATH# 提升rk3568cpu频率# 查看 CPU 频率cat /sys/devices/system/cpu/cpu*/cpufreq/cpuinfo_cur_freq# 查看 CPU 可用频率(不同平台显示的可用频率会有所不同)cat /sys/devices/system/cpu/cpufreq/policy0/scaling_available_frequencies# 将 CPU 调频模式切换为用户空间模式,这意味着用户程序可以手动控制 CPU 的工作频率,而不是由系统自动管理。这样可以提供更大的灵活性和定制性,但需要注意合理调整频率以保持系统稳定性和性能。echo userspace > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor# 设置rk3568 CPU 频率为1.9GHzecho 1992000 > /sys/devices/system/cpu/cpufreq/policy0/scaling_setspeed# 执行大语言模型chmod 777 llama./llama -m chinese-alpaca-7b-q4.bin -t 4
移植InferLLM三方库在OpenHarmmony设备rk3568上部署大语言模型实现人机对话。最后运行效果有些慢,跳出人机对话框也有些慢,请耐心等待。
今天关于《在2GB的DAYU200设备上本地安装大规模语言模型》的内容就介绍到这里了,是不是学起来一目了然!想要了解更多关于大语言模型,鸿蒙,alpaca模型的内容请关注golang学习网公众号!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
299 收藏
-
科技周边 · 人工智能 | 2天前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-
475 收藏
-
科技周边 · 人工智能 | 6天前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK292 收藏
-
379 收藏
-
394 收藏
-
101 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习