victoriaMetrics库布隆过滤器初始化及使用详解
来源:脚本之家
时间:2022-12-29 10:41:45 206浏览 收藏
IT行业相对于一般传统行业,发展更新速度更快,一旦停止了学习,很快就会被行业所淘汰。所以我们需要踏踏实实的不断学习,精进自己的技术,尤其是初学者。今天golang学习网给大家整理了《victoriaMetrics库布隆过滤器初始化及使用详解》,聊聊初始化、victoriaMetrics布隆过滤器,我们一起来看看吧!
代码路径:/lib/bloomfilter
概述
victoriaMetrics的vmstorage组件会接收上游传递过来的指标,在现实场景中,指标或瞬时指标的数量级可能会非常恐怖,如果不限制缓存的大小,有可能会由于cache miss而导致出现过高的slow insert。
为此,vmstorage提供了两个参数:maxHourlySeries和maxDailySeries,用于限制每小时/每天添加到缓存的唯一序列。
唯一序列指表示唯一的时间序列,如metrics{label1="value1",label2="value2"}属于一个时间序列,但多条不同值的metrics{label1="value1",label2="value2"}属于同一条时间序列。victoriaMetrics使用如下方式来获取时序的唯一标识:
func getLabelsHash(labels []prompbmarshal.Label) uint64 {
bb := labelsHashBufPool.Get()
b := bb.B[:0]
for _, label := range labels {
b = append(b, label.Name...)
b = append(b, label.Value...)
}
h := xxhash.Sum64(b)
bb.B = b
labelsHashBufPool.Put(bb)
return h
}
限速器的初始化
victoriaMetrics使用了一个类似限速器的概念,限制每小时/每天新增的唯一序列,但与普通的限速器不同的是,它需要在序列级别进行限制,即判断某个序列是否是新的唯一序列,如果是,则需要进一步判断一段时间内缓存中新的时序数目是否超过限制,而不是简单地在请求层面进行限制。
hourlySeriesLimiter = bloomfilter.NewLimiter(*maxHourlySeries, time.Hour) dailySeriesLimiter = bloomfilter.NewLimiter(*maxDailySeries, 24*time.Hour)
下面是新建限速器的函数,传入一个最大(序列)值,以及一个刷新时间。该函数中会:
- 初始化一个限速器,限速器的最大元素个数为
maxItems - 则启用了一个goroutine,当时间达到
refreshInterval时会重置限速器
func NewLimiter(maxItems int, refreshInterval time.Duration) *Limiter {
l := &Limiter{
maxItems: maxItems,
stopCh: make(chan struct{}),
}
l.v.Store(newLimiter(maxItems)) //1
l.wg.Add(1)
go func() {
defer l.wg.Done()
t := time.NewTicker(refreshInterval)
defer t.Stop()
for {
select {
case
限速器只有一个核心函数Add,当vmstorage接收到一个指标之后,会(通过getLabelsHash计算该指标的唯一标识(h),然后调用下面的Add函数来判断该唯一标识是否存在于缓存中。
如果当前存储的元素个数大于等于允许的最大元素,则通过过滤器判断缓存中是否已经存在该元素;否则将该元素直接加入过滤器中,后续允许将该元素加入到缓存中。
func (l *Limiter) Add(h uint64) bool {
lm := l.v.Load().(*limiter)
return lm.Add(h)
}
func (l *limiter) Add(h uint64) bool {
currentItems := atomic.LoadUint64(&l.currentItems)
if currentItems >= uint64(l.f.maxItems) {
return l.f.Has(h)
}
if l.f.Add(h) {
atomic.AddUint64(&l.currentItems, 1)
}
return true
}
上面的过滤器采用的是布隆过滤器,核心函数为Has和Add,分别用于判断某个元素是否存在于过滤器中,以及将元素添加到布隆过滤器中。
过滤器的初始化函数如下,bitsPerItem是个常量,值为16。bitsCount统计了过滤器中的总bit数,每个bit表示某个值的存在性。bits以64bit为单位的(后续称之为slot,目的是为了在bitsCount中快速检索目标bit)。计算bits时加上63的原因是为了四舍五入向上取值,比如当maxItems=1时至少需要1个unit64的slot。
func newFilter(maxItems int) *filter {
bitsCount := maxItems * bitsPerItem
bits := make([]uint64, (bitsCount+63)/64)
return &filter{
maxItems: maxItems,
bits: bits,
}
}
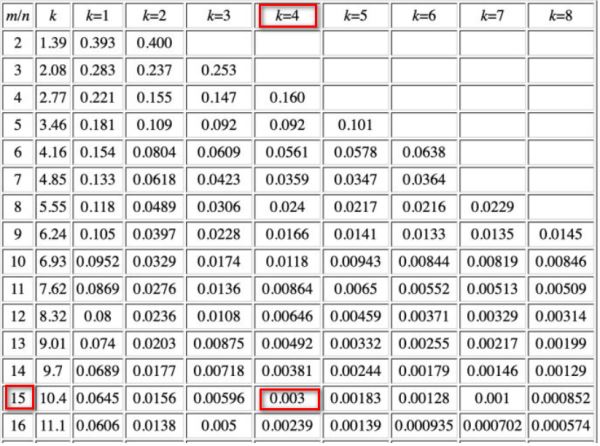
为什么bitsPerItem为16?这篇文章给出了如何计算布隆过滤器的大小。在本代码中,k为4(hashesCount),期望的漏失率为0.003(可以从官方的filter_test.go中看出),则要求总存储和总元素的比例为15,为了方便检索slot(64bit,为16的倍数),将之设置为16。
if p > 0.003 {
t.Fatalf("too big false hits share for maxItems=%d: %.5f, falseHits: %d", maxItems, p, falseHits)
}
下面是过滤器的Add操作,目的是在过滤器中添加某个元素。Add函数中没有使用多个哈希函数来计算元素的哈希值,转而改变同一个元素的值,然后对相应的值应用相同的哈希函数,元素改变的次数受hashesCount的限制。
- 获取过滤器的完整存储,并转换为以bit单位
- 将元素
h转换为byte数组,便于xxhash.Sum64计算 - 后续将执行hashesCount次哈希,降低漏失率
- 计算元素h的哈希
- 递增元素
h,为下一次哈希做准备 - 取余法获取元素的bit范围
- 获取元素所在的slot(即uint64大小的bit范围)
- 获取元素所在的slot中的bit位,该位为1表示该元素存在,为0表示该元素不存在
- 获取元素所在bit位的掩码
- 加载元素所在的slot的数值
- 如果
w & mask结果为0,说明该元素不存在, - 将元素所在的slot(
w)中的元素所在的bit位(mask)置为1,表示添加了该元素 - 由于
Add函数可以并发访问,因此bits[i]有可能被其他操作修改,因此需要通过重新加载(14)并通过循环来在bits[i]中设置该元素的存在性
func (f *filter) Add(h uint64) bool {
bits := f.bits
maxBits := uint64(len(bits)) * 64 //1
bp := (*[8]byte)(unsafe.Pointer(&h))//2
b := bp[:]
isNew := false
for i := 0; i
看懂了Add函数,Has就相当简单了,它只是Add函数的缩减版,无需设置bits[i]:
func (f *filter) Has(h uint64) bool {
bits := f.bits
maxBits := uint64(len(bits)) * 64
bp := (*[8]byte)(unsafe.Pointer(&h))
b := bp[:]
for i := 0; i
总结
由于victoriaMetrics的过滤器采用的是布隆过滤器,因此它的限速并不精准,在源码条件下, 大约有3%的偏差。但同样地,由于采用了布隆过滤器,降低了所需的内存以及相关计算资源。此外victoriaMetrics的过滤器实现了并发访问。
在大流量场景中,如果需要对请求进行相对精准的过滤,可以考虑使用布隆过滤器,降低所需要的资源,但前提是过滤的结果能够忍受一定程度的漏失率。
今天关于《victoriaMetrics库布隆过滤器初始化及使用详解》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
118 收藏
-
159 收藏
-
320 收藏
-
415 收藏
-
102 收藏
-
427 收藏
-
Golang · Go教程 | 17小时前 | golang · HTTP · 安全 · Go教程 · net/http · 接口防护 · net/http 请求超时 MaxBytesReader Go HTTP 请求体限制 内存防护173 收藏
-
405 收藏
-
144 收藏
-
Golang · Go教程 | 1天前 | WEB开发 · go · 表单 · 用户体验 · html/template · 表单校验 html/template 无障碍 Go教程 字段错误 输入回填 aria-invalid485 收藏
-
467 收藏
-
352 收藏
-
494 收藏
-
355 收藏
-
450 收藏
-
473 收藏
-
407 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 虚心的钢笔
- 这篇文章真是及时雨啊,好细啊,真优秀,已收藏,关注师傅了!希望师傅能多写Golang相关的文章。
- 2023-05-12 17:28:59
-
- 怕孤独的河马
- 细节满满,已加入收藏夹了,感谢老哥的这篇博文,我会继续支持!
- 2023-05-03 22:54:56
-
- 活力的小懒猪
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢师傅分享技术贴!
- 2023-03-16 08:44:28
-
- 雪白的发卡
- 感谢大佬分享,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢师傅分享技术贴!
- 2023-02-14 06:06:39
-
- 合适的春天
- 这篇技术贴真及时,太全面了,感谢大佬分享,收藏了,关注作者大大了!希望作者大大能多写Golang相关的文章。
- 2023-01-25 16:45:28
-
- 平常的大神
- 好细啊,已加入收藏夹了,感谢作者的这篇博文,我会继续支持!
- 2023-01-20 14:49:17
-
- 典雅的镜子
- 赞 ??,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢作者大大分享技术文章!
- 2023-01-16 10:28:52
-
- 合适的果汁
- 这篇技术贴真是及时雨啊,太详细了,很有用,已加入收藏夹了,关注up主了!希望up主能多写Golang相关的文章。
- 2023-01-16 09:28:56
-
- 闪闪的飞机
- 太细致了,收藏了,感谢大佬的这篇文章内容,我会继续支持!
- 2023-01-05 00:14:22