参数量不到10亿的OctopusV3,如何媲美GPT-4V和GPT-4?
来源:机器之心
时间:2024-05-02 15:54:32 385浏览 收藏
积累知识,胜过积蓄金银!毕竟在科技周边开发的过程中,会遇到各种各样的问题,往往都是一些细节知识点还没有掌握好而导致的,因此基础知识点的积累是很重要的。下面本文《参数量不到10亿的OctopusV3,如何媲美GPT-4V和GPT-4?》,就带大家讲解一下知识点,若是你对本文感兴趣,或者是想搞懂其中某个知识点,就请你继续往下看吧~
多模态 AI 系统的特点在于能够处理和学习包括自然语言、视觉、音频等各种类型的数据,从而指导其行为决策。近期,将视觉数据纳入大型语言模型(如 GPT-4V)的研究取得了重要进展,但如何有效地将图像信息转化为 AI 系统的可执行操作仍面临挑战。 为了实现图像信息的转化,一种常见的方法是将图像数据转化为对应的文本描述,然后由 AI 系统根据描述进行操作。这可以通过在现有的图像数据集上进行监督学习,让 AI 系统自动学习图像到文本的映射关系。此外,还可以利用强化学习方法,通过与环境互动来学习如何根据图像信息进行决策。 另一种方法是直接将图像信息与语言模型结合,构建
在最近的一篇论文中,研究者提出了一种专为 AI 应用设计的多模态模型,引入了「functional token」的概念。
论文标题:Octopus v3: Technical Report for On-device Sub-billion Multimodal AI Agent
论文链接:https://arxiv.org/pdf/2404.11459.pdf
模型权重和推理代码:https://www.nexa4ai.com/apply
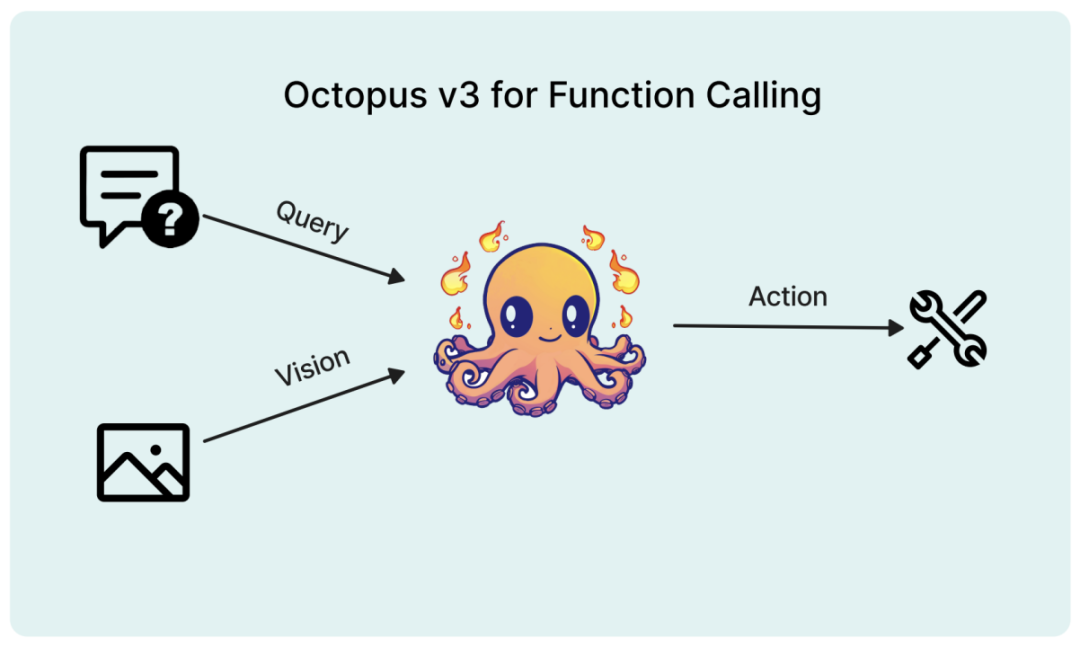
该模型能完整支持边缘设备,研究者将其参数量优化至10亿以内。与GPT-4类似,该模型能同时处理英文和中文。实验证明,该模型能在包括树莓派等各类资源受限的终端设备上高效运行。
研究背景
人工智能技术的飞速发展彻底改变了人机交互的方式,催生出一批能够根据自然语言、视觉等多种形式的输入执行复杂任务、做出决策的智能 AI 系统。这些系统有望实现从图像识别、语言翻译等简单任务到医疗诊断、自动驾驶等复杂应用的自动化。多模态语言模型是这些智能系统的核心,使其能够通过处理整合文本、图像乃至音视频等多模态数据,理解和生成近乎人类的回复。相较于主要关注文本处理和生成的传统语言模型,多模态语言模型是一大飞跃。通过纳入视觉信息,这些模型能够更好地理解输入数据的语境和语义,从而给出更加准确、相关的输出。处理和整合多模态数据的能力,对于开发多模态 AI 系统至关重要,使其能够同时理解语言和视觉信息的任务,如视觉问答、图像导航、多模态情感分析等。
开发多模态语言模型的一大挑战在于,如何将视觉信息有效地编码为模型可处理的格式。这通常借助神经网络架构,例如视觉变换器(ViT)和卷积神经网络(CNN),从图像中提取层次化特征的能力,在计算机视觉任务中得到广泛应用。使用这些架构作为模型,可以学习从输入数据中提取更加复杂的表征。此外,基于transformer的架构不仅能够捕捉长距离依赖关系,还在理解图像中物体之间关系方面表现出色。近年来备受青睐。这些架构使模型能够从输入图像中提取有意义的特征,并将其转化为可与文本输入相结合的向量表示。
编码视觉信息的另一种方法是图像符号化 (tokenization), 即将图像分割为更小的离散单元或 token。这种方法让模型能以类似处理文本的方式来处理图像,实现两种模态的更无缝融合。图像 token 信息可与文本输入一同送入模型,使其能同时关注两种模态并生成更准确、更契合上下文的输出。例如,OpenAI 开发的 DALL-E 模型采用 VQ-VAE (向量量化变分自编码器) 的变体对图像做符号化,使模型能根据文本描述生成新颖图像。开发出能够根据用户提供的查询和图像采取行动的小型高效模型,对 AI 系统的未来发展影响深远。这些模型可部署于智能手机、物联网设备等资源受限的设备上,扩大其应用范围和场景。借助多模态语言模型的威力,这些小型系统能以更自然、直观的方式理解和回应用户的问询,同时考虑用户提供的视觉语境。这为实现更具吸引力、个性化的人机互动开启了可能,如根据用户喜好提供视觉推荐的虚拟助手,或根据用户面部表情调节设置的智能家居设备。
此外,多模态 AI 系统的发展有望实现人工智能技术的民主化,让更广泛的用户和行业受益。更小巧高效的模型可在算力较弱的硬件上训练,降低部署所需的计算资源和能耗。这可能带来 AI 系统在医疗、教育、娱乐、电商等各个领域的广泛应用,最终改变人们的生活和工作方式。
相关工作
多模态模型由于能够处理和学习文本、图像、音频等多种数据类型而备受关注。这类模型能捕捉不同模态间复杂的交互,并利用它们的互补信息来提升各类任务的性能。视觉 - 语言预训练 (VLP) 模型如 ViLBERT、LXMERT、VisualBERT 等,通过跨模态注意力学习视觉和文本特征的对齐,生成丰富的多模态表征。多模态 transformer 架构如 MMT、ViLT 等则对 transformer 做了改进,以高效处理多种模态。研究者还尝试将音频、面部表情等其他模态纳入模型,如多模态情感分析 (MSA) 模型、多模态情绪识别 (MER) 模型等。通过利用不同模态的互补信息,多模态模型相比单模态方法取得了更优的性能和泛化能力。
终端语言模型定义为参数量少于 70 亿的模型,因为研究者发现即使采用量化,在边缘设备上运行 130 亿参数的模型也非常困难。这一领域近期的进展包括 Google 的 Gemma 2B 和 7B、Stable Diffusion 的 Stable Code 3B 以及 Meta 的 Llama 7B。有趣的是,Meta 的研究表明,与大型语言模型不同,小型语言模型采用深而窄的架构会有更好的表现。其他对终端模型有益的技术还包括 MobileLLM 中提出的 embedding 共享、分组 query 注意力以及即时分块权重共享等。这些发现凸显了在开发终端应用的小型语言模型时,需要考虑不同于大模型的优化方法和设计策略。
Octopus 方法
Octopus v3 模型开发中采用的主要技术。多模态模型开发的两个关键方面是:将图像信息与文本输入相整合,以及优化模型预测动作的能力。
视觉信息编码
图像处理中存在多种视觉信息编码方法,常用隐藏层的 embedding。例如,VGG-16 模型的隐藏层 embedding 被用于风格迁移任务。OpenAI 的 CLIP 模型展示了对齐文本和图像 embedding 的能力,利用其图像编码器来嵌入图像。ViT 等方法则采用了图像 tokenization 等更先进的技术。研究者评估了多种图像编码技术,发现 CLIP 模型的方法最为有效。因此,本文采用基于 CLIP 的模型进行图像编码。
Functional token
与应用于自然语言和图像的 tokenization 类似,特定 function 也可封装为 functional token。研究者为这些 token 引入了一种训练策略,借鉴了自然语言模型处理未见词的技术。这一方法与 word2vec 类似,通过 token 的上下文环境来丰富其语义。例如,高级语言模型最初可能难以应对 PEGylation 和 Endosomal Escape 等复杂化学术语。但通过因果语言建模,尤其是在包含这些术语的数据集上训练,模型能够习得这些术语。类似地,functional token 也可通过并行策略习得,其中 Octopus v2 模型可为此类学习过程提供强大的平台。研究表明,functional token 的定义空间是无限的,从而能够将任意特定 function 表示为 token。
多阶段训练
为开发出高性能的多模态 AI 系统,研究者采用了集成因果语言模型和图像编码器的模型架构。该模型的训练过程分为多个阶段。首先,因果语言模型和图像编码器分别训练,建立基础模型。随后,将这两个部件合并,并进行对齐训练以同步图像和文本处理能力。在此基础上,借鉴 Octopus v2 的方法来促进 functional token 的学习。最后一个训练阶段中,这些能够与环境交互的 functional token 提供反馈,用于进一步优化模型。因此,最后阶段研究者采用强化学习,并选择另一个大型语言模型作为奖励模型。这种迭代训练方式增强了模型处理和整合多模态信息的能力。
模型评估
本节介绍模型的实验结果,并与集成 GPT-4V 和 GPT-4 模型的效果进行对比。在对比实验中,研究者首先采用 GPT-4V (gpt-4-turbo) 处理图像信息。然后将提取的数据输入 GPT-4 框架 (gpt-4-turbo-preview), 将所有 function 描述纳入上下文并应用小样本学习以提升性能。在演示中,研究者将 10 个常用的智能手机 API 转化为 functional token 并评估其表现,详见后续小节。
值得注意的是,虽然本文仅展示了 10 个 functional token, 但该模型可以训练更多 token 以创建更通用的 AI 系统。研究者发现,对于选定的 API, 参数量不到 10 亿的模型作为多模态 AI 表现可与 GPT-4V 和 GPT-4 的组合相媲美。
此外,本文模型的可扩展性允许纳入广泛的 functional token, 从而能够打造高度专业化的 AI 系统,适用于特定领域或场景。这种适应性使本文方法在医疗、金融、客户服务等行业尤为有价值,这些领域中 AI 驱动的解决方案可显著提升效率和用户体验。
在下面的所有 function 名称中,Octopus 仅输出 functional token 如 < nexa_0>,...,
发送邮件

发送短信

Google 搜索

亚马逊购物

智能回收

失物招领

室内设计

Instacart 购物

DoorDash 外卖

宠物护理

社会影响
在 Octopus v2 的基础上,更新后的模型纳入了文本和视觉信息,从其前身纯文本方法迈出了重要一步。这一显著进展实现了视觉和自然语言数据的同步处理,为更广泛的应用铺平了道路。Octopus v2 引入的 functional token 可适应多个领域,如医疗和汽车行业。随着视觉数据的加入,functional token 的潜力进一步扩展到自动驾驶、机器人等领域。此外,本文的多模态模型让树莓派等设备实际转化为 Rabbit R1 、Humane AI Pin 之类的智能硬件成为可能,它采用终端模型而非基于云的方案。
Functional token 目前已获得授权,研究者鼓励开发者参与本文框架,在遵守许可协议的前提下自由创新。在未来的研究中,研究者旨在开发一个能够容纳音频、视频等额外数据模态的训练框架。此外,研究者发现视觉输入可能带来相当大的延迟,目前正在优化推理速度。
今天关于《参数量不到10亿的OctopusV3,如何媲美GPT-4V和GPT-4?》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
299 收藏
-
科技周边 · 人工智能 | 21小时前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-
475 收藏
-
科技周边 · 人工智能 | 4天前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK292 收藏
-
379 收藏
-
394 收藏
-
101 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习