识别细胞也能用大模型了!清华系团队出品,已入选ICML 2024 | 开源
来源:51CTO.COM
时间:2024-05-16 14:15:15 483浏览 收藏
学习科技周边要努力,但是不要急!今天的这篇文章《识别细胞也能用大模型了!清华系团队出品,已入选ICML 2024 | 开源》将会介绍到等等知识点,如果你想深入学习科技周边,可以关注我!我会持续更新相关文章的,希望对大家都能有所帮助!
大模型带来的生命科学领域突破,刚刚再传新进展。
来自清华系,使用大模型实现了单细胞身份识别,同时模型LangCell也正式对外开源。
它不仅可以准确识别细胞身份,还具有很强的零样本分析能力,论文已被ICML 2024录⽤。

LangCell的数据集中包含2750万条数据,涵盖了细胞类型、发育阶段、组织器官、疾病筛选等8个维度的信息,称得上是“细胞的百科全书”。
实际测试中,LangCell也在多个细胞识别任务上超越了前SOTA,在研究人员专门设计的新任务上也表现突出。
然而,在不使用文本信息的情况下,单独使用其包含的细胞编码器模块,也能在各个任务上实现最优表现。
出品团队:清华系创业公司⽔⽊分⼦与清华⼤学AIR聂再清教授团队。
大模型,细胞识别的“新武器”
细胞,是探索⽣命奥秘的起点,细胞⾝份的识别,是⽣物科学领域的⼀⼤热点。
这不仅关于细胞的“户”调查,还关系到它们在组织中的“社交关系”,以及它们对“物信号”和“环境变化”的敏感反应,详细分析单细胞测序数据。
但单细胞测序数据分析,就像是⼀场科学界的“寻宝游戏”,可能需要⼀个⼏⼈到⼏⼗⼈不等的跨学科的团队,用⼏周到⼏个⽉,甚⾄更⻓时间来完成。
现在,LangCell模型成为了细胞⾝份识别的“新武器”。
LangCell是⾸个结合单细胞RNA测序数据与⾃然语⾔处理进⾏预训练的单细胞表征模型,不仅提⾼了识别的准确性,还减少了对⼤量标记数据的依赖。
传统的单细胞RNA测序数据分析,就像是在没有地图的情况下寻找宝藏,虽然能找到⼀些线索,但总有些⼒不从⼼。
⽽LangCell模型,通过构建单细胞数据和⾃然语⾔的统⼀表⽰,就像是给了模型⼀张“藏宝图”,让它能够更直接地找到与细胞⾝份相关的信息。
具体来说,LangCell主要由细胞编码器(Cell Encoder,CE)和文本编码器两部分组成。
其中细胞编码器使用预训练的Geneformer初始化。将排序后的基因表达序列输入转化为嵌入向量序列,在序列开始处添加[CLS]标记,其嵌入向量经过线性变换作为整个细胞的表征向量。
文本编码器又有单模态和多模态两种编码模式。
单模态时相当于一个BERT模型,用于将文本转换为嵌入向量;
多模态时在self-attention后添加cross-attention模块,融合细胞嵌入向量计算联合表征,并通过线性层预测细胞-文本匹配概率。
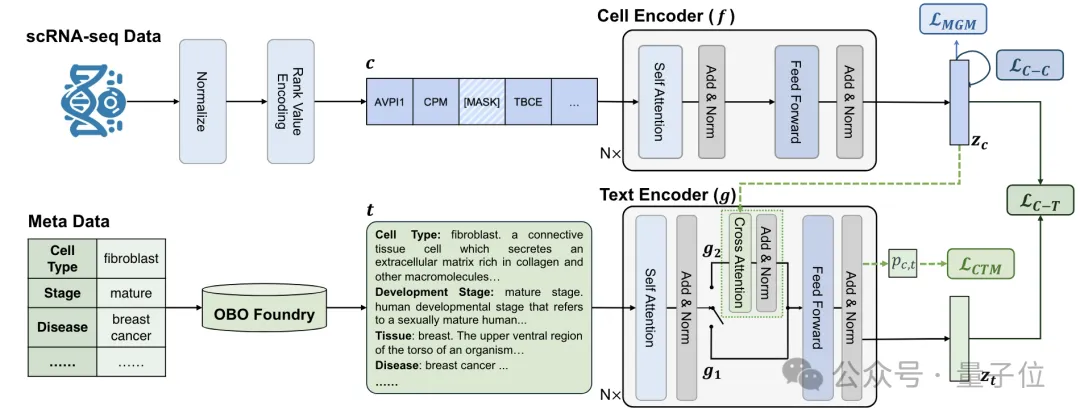
为训练LangCell,研究⼈员还构建了⼀个名为scLibrary的数据集,它包含了2750万条scRNA-seq数据及从OBO Foundry中获取的细胞⾝份的多视⻆⽂本描述,就像是细胞研究的“百科全书”。
这个数据集不仅包含了⼤量的原始数据,还包含了多视⻆的细胞⾝份⽂本描述,为模型提供了丰富的学习材料。
此外在零样本场景中,只需未知类型细胞的scRNA-seq数据输入到CE中,得到细胞嵌入向量表征,然后与候选类型的文本嵌入向量进行相似度计算,分数最高的类型即被预测为该未知细胞的类型。
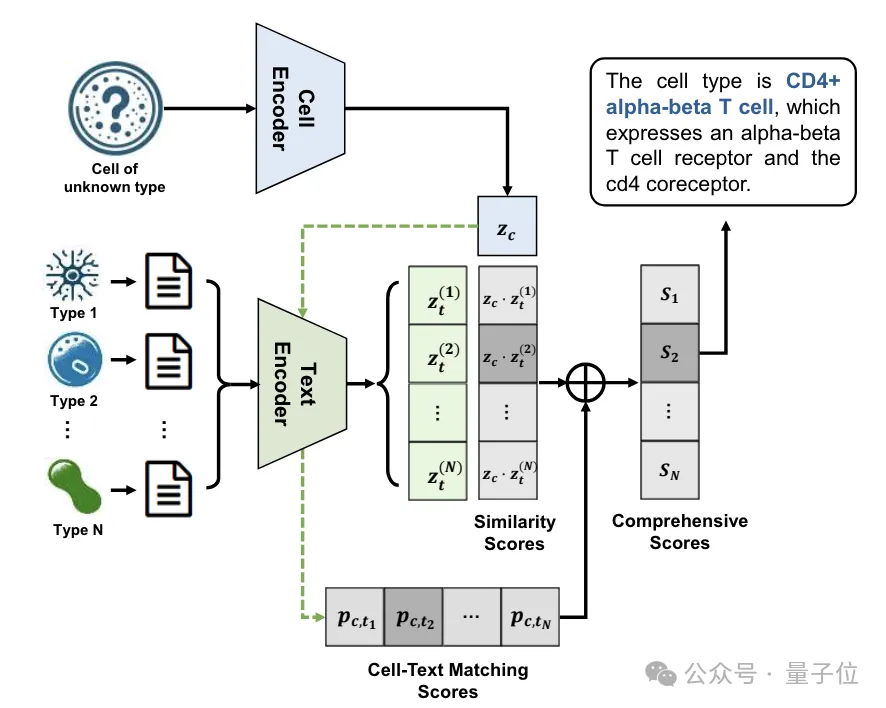
结果,LangCell模型在零样本细胞⾝份理解场景中表现出⾊,即使没有进⾏微调,也能直接对新的细胞类型进⾏注释。
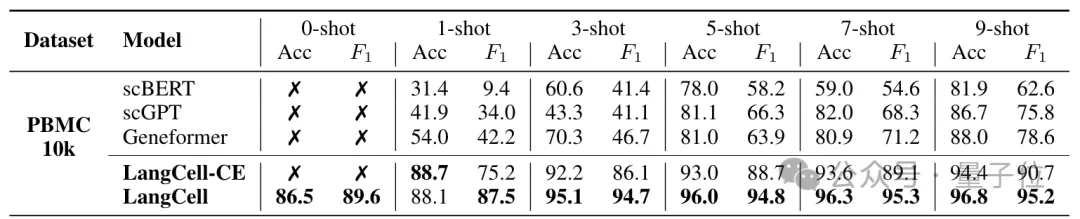
在PBMC数据集上,零样本的LangCell分类准确率就已达到86.5%,F1评分更是超过了前SOTA模型的9-shot表现。
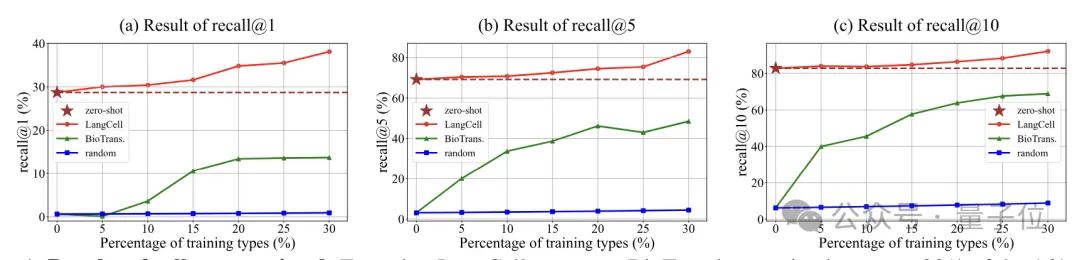
在更具挑战的跨数据集的细胞-文本检索任务中,LangCell的零样本召回率R@1、R@5和R@10结果都超过了用30%标注数据训练的BioTranslator模型。
此外,研究者还专门构建了“非小细胞肺癌亚型分类”和“细胞通路识别”两个具有重要生物学意义的新基准测试任务。
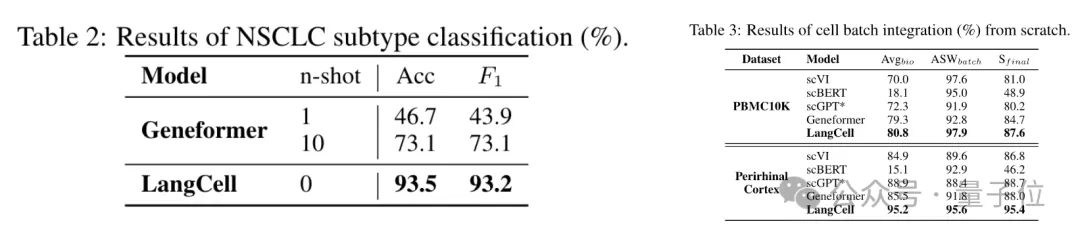
结果在非小细胞肺癌亚型分类任务中,LangCell的零样本分类准确率和F1分数分别达到93.5%和93.2%,比10-shot的Geneformer高出约20%。
而对于细胞批次整合任务,在PBMC10K和Perirhinal Cortex两个数据集上,LangCell的Avgbio、ASWbatch和Sfinal三个指标均达到了最优。
不仅LangCell的表现优异,即使在不使用文本信息的情况下,单独的CE模块也能在各个任务上实现最优表现。
在多个细胞类型注释任务的数据集上,CE模块的成绩都超过了前SOTA,在细胞通路识别上的表现也十分优异。

作者介绍,LangCell的这些能力,在新疾病或细胞亚型的研究中尤为重要,可以减少对⼤量标记数据的依赖,加速疾病机理的发现。
团队简介
⽔⽊分⼦由清华⼤学智能产业研究院(AIR)孵化,重点研究方向是⽣物医药⾏业基础⼤模型及新⼀代对话式⽣物医药研发助⼿。
水木分子和清华大学还有两项与北大和南大共同研发的成果一同入选了ICML 2024,分别在小分子3D表示学习和大分子蛋白质表示学习方面取得进展。
GitHub:https://github.com/PharMolix/OpenBioMed
论文地址https://arxiv.org/abs/2405.06708
本篇关于《识别细胞也能用大模型了!清华系团队出品,已入选ICML 2024 | 开源》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于科技周边的相关知识,请关注golang学习网公众号!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
科技周边 · 人工智能 | 3天前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计427 收藏
-
154 收藏
-
309 收藏
-
234 收藏
-
科技周边 · 人工智能 | 6天前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream448 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 2星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习