ICML2024高分!魔改注意力,让小模型能打两倍大的模型
来源:51CTO.COM
时间:2024-06-03 14:21:39 478浏览 收藏
珍惜时间,勤奋学习!今天给大家带来《ICML2024高分!魔改注意力,让小模型能打两倍大的模型》,正文内容主要涉及到等等,如果你正在学习科技周边,或者是对科技周边有疑问,欢迎大家关注我!后面我会持续更新相关内容的,希望都能帮到正在学习的大家!
改进Transformer核心机制注意力,让小模型能打两倍大的模型!
ICML+2024高分论文,彩云科技团队构建DCFormer框架,替代Transformer核心组件注意力模块(MHA),提出可动态组合的多头注意力(DCMHA)。
DCMHA解除了MHA注意力头的查找选择回路和变换回路的固定绑定,让它们可以根据输入动态组合,从根本上提升了模型的表达能力。
原文意思是,每层都有固定的H个注意力头,现在用几乎理解为,原来每层都有固定的H个注意力头,现在用几乎相同的参数量和计算力,可以动态组合出多至HxH个注意力头。 微调后的内容可以更明确地表达原文的意思,如下: 原来的模型每层都包含固定数量的H个注意力头,现在我们可以利用
DCMHA即插即用,可在任何Transformer架构中替换MHA,得到通用、高效和可扩展的新架构DCFormer。
这项工作由来自北京邮电大学、AI创业公司彩云科技的研究人员共同完成。
研究人员用在DCFormer基础上打造的模型DCPythia-6.9B,在预训练困惑度和下游任务评估上都优于开源Pythia-12B。
DCFormer模型在性能上与那些计算量是其1.7-2倍的Transformer模型相当。

多头注意力模块有何局限?
大模型的scaling law告诉我们,随着算力的提升,模型更大、数据更多,模型效果会越来越好。虽然还没有人能明确说明这条路的天花板有多高,能否达到AGI,但这确实是目前大家最普遍的做法。
但除此以外,另一个问题同样值得思考:目前绝大多数大模型都基于Transformer,它们都是用一个一个Transformer块像搭积木一样搭起来的,那作为积木块的Transformer本身,还有多大的改进提升空间?
这是模型结构研究要回答的基本问题,也正是彩云科技和北京邮电大学联合完成的DCFormer这项工作的出发点。
在Transformer的多头注意力模块(MHA)中,各个注意力头彼此完全独立的工作。
这个设计因其简单易实现的优点已在实践中大获成功,但同时也带来注意力分数矩阵的低秩化削弱了表达能力、注意力头功能的重复冗余浪费了参数和计算资源等一些弊端。基于此,近年来有一些研究工作试图引入某种形式的注意力头间的交互。
根据Transformer回路理论,在MHA中 ,每个注意力头的行为由WQ、WK、WV、WO四个权重矩阵刻画(其中WO由MHA的输出投影矩阵切分得到)。
其中,WQWK叫做QK回路(或叫查找选择回路),决定从当前token关注上下文中的哪个(些)token,例如:

WOWV叫做OV回路(或叫投影变换回路),决定从关注到的token取回什么信息(或投影什么属性)写入当前位置的残差流,进而预测下一个token。例如:

研究人员注意到,查找(从哪拿)和变换(拿什么)本来是独立的两件事,理应可以分别指定并按需自由组合(就像在SQL查询中,WHERE后的选择条件和SELECT后的属性投影是分开写的一样),MHA硬把它们放到一个注意力头的QKOV里“捆绑销售”,限制了灵活性和表达能力。
例如,假设有个模型存在注意力头A、B、C其QK和OV回路能够完成上面的例子=,那换成:

需要交叉组合现有注意力头的QK和OV回路,模型就可能“转不过弯儿”了(经研究人员系统构造的合成测试集验证,<=6B的中小尺寸模型在这类看似简单的任务上确实表现不佳)。
动态组合多头注意力长啥样?
以此为出发点,本文研究团队在MHA中引入compose操作:
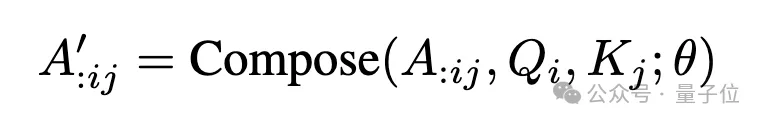
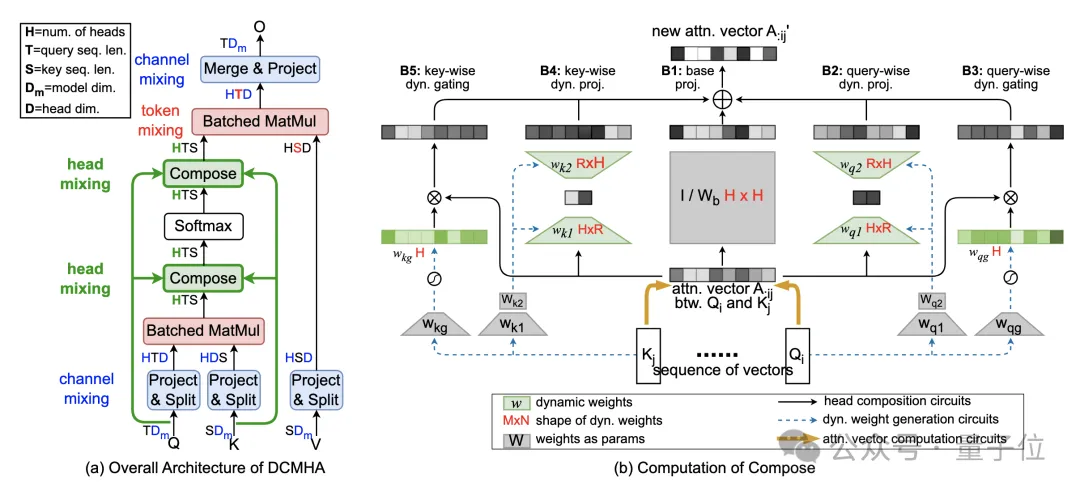
如下图所示,得到DCMHA:
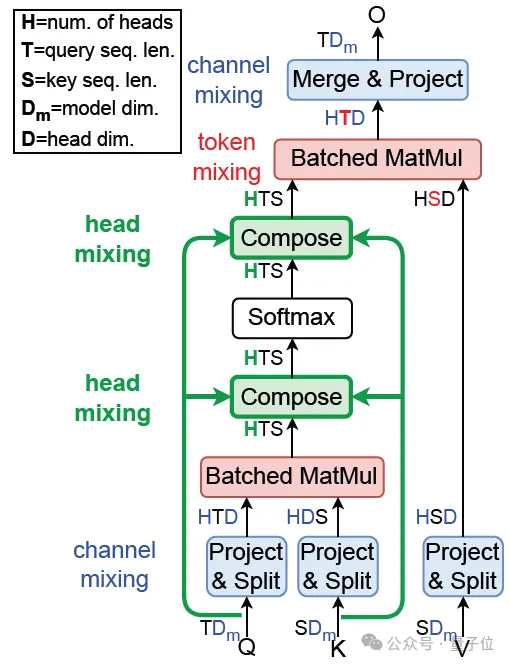
△图1. DCMHA总体结构
将QWQ和KWK算出的注意力分数矩阵AS和注意力权重矩阵AW,与VWV相乘之前,对其在num_heads维上做线性映射得到新的矩阵A’,通过不同的线性映射矩阵(composition map),以实现各种注意力头组合的效果。
例如图2(c)中将head 3和7的QK回路与head 1的OV回路组合在一起,形成一个“新的”注意力头。
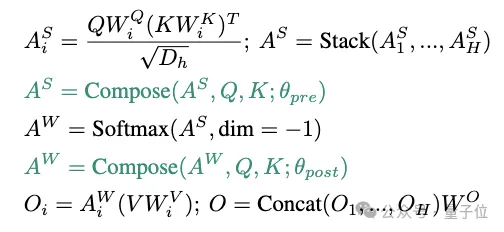
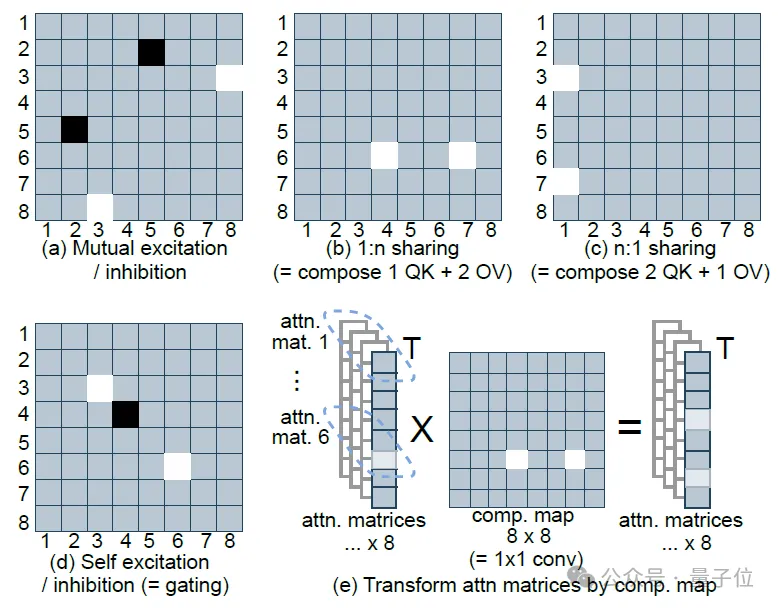
△图2. 8个注意力头的简化的典型composition map的功能,浅色表示大值
为了最大限度的增强表达能力,研究人员希望映射矩阵由输入动态生成,即动态决定注意力头怎样组合。
但他们要生成的映射矩阵不是一个,而是对序列中每对源位置的query Qi和目的位置的key Kj,都要生成这样一个矩阵,计算开销和显存占用都将难以接受。
为此,他们进一步将映射矩阵分解为一个输入无关的静态矩阵Wb、一个低秩矩阵w1w2和一个对角矩阵Diag(wg)之和,分别负责基础组合、注意力头间的有限方式(即秩R<=2)的动态组合和头自身的动态门控(见图2(d)和图3(b))。其中后两个矩阵由Q矩阵和K矩阵动态生成。
在不牺牲效果的前提下,将计算和参数复杂度降低到几乎可以忽略的程度(详见论文中复杂度分析)。再结合JAX和PyTorch实现层面的优化,让DCFormer可以高效训练和推理。
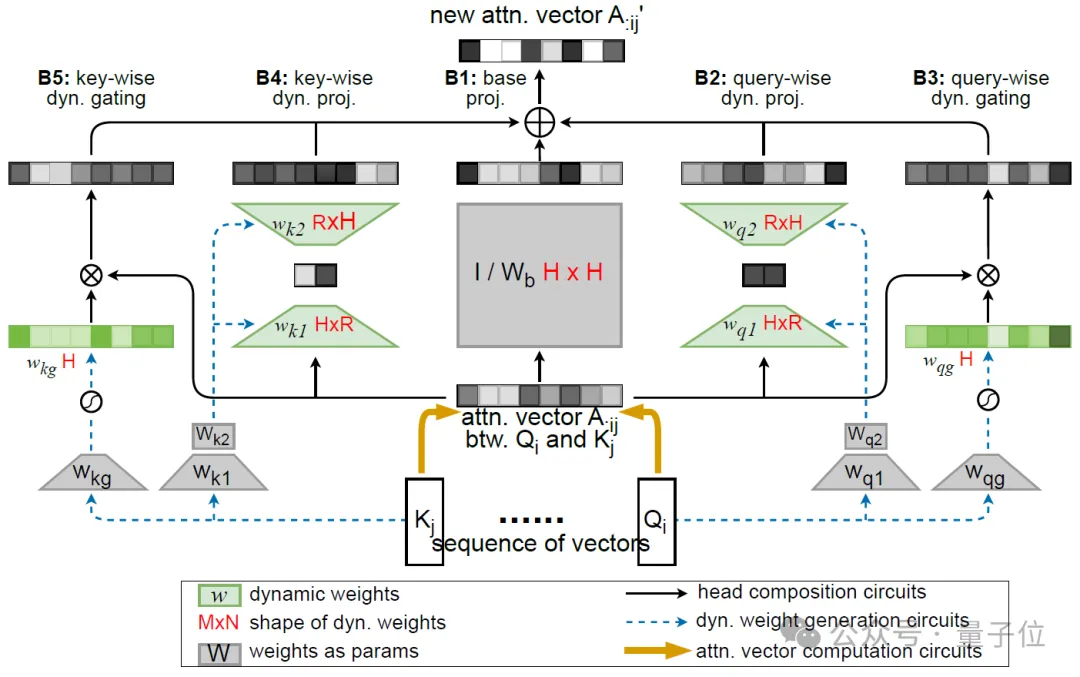
△图3. Compose的计算
效果如何?
规模扩展
评估一个架构的好坏,研究人员关注的最核心指标是算力转化为智能的效率(或叫性能算力比),即投入单位算力能带来的模型性能提升——花更少的算力,得到更好的模型。
从图4和图5的scaling law曲线(在对数坐标下,每个模型架构的损失随算力的变化可画出一条近似直线,损失越低,模型越好)可以看出,DCFormer可以达到1.7~2倍算力的Transformer模型的效果,即算力智能转化率提升了1.7~2倍。
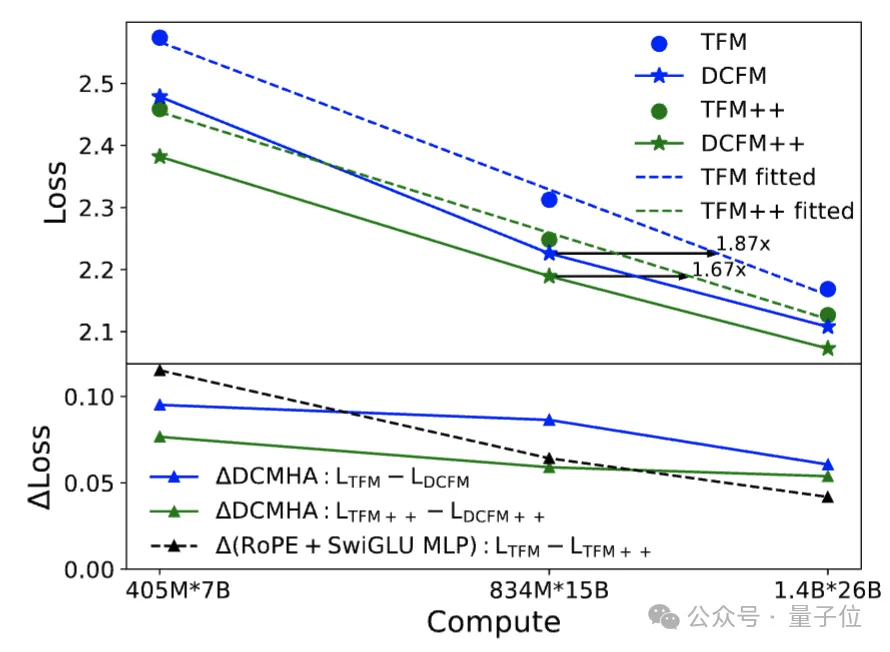
△图4. Transformer和DCFormer的规模扩展效果
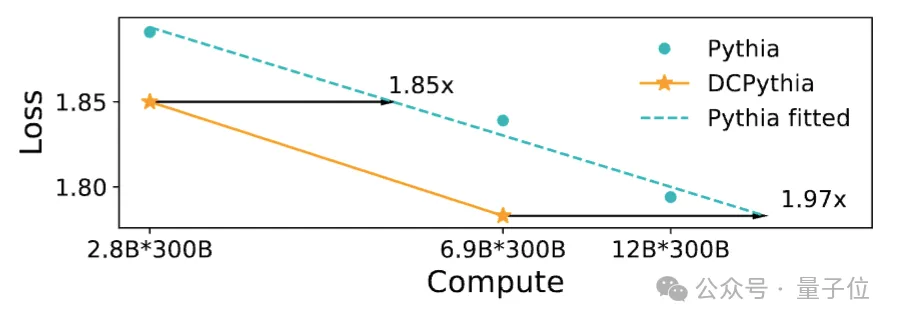
△图5. Pythia和DCPythia的规模扩展效果
怎么理解这个提升幅度呢?
自2017年Transformer诞生至今,从改进性能算力比的角度,GLU MLP和旋转位置编码RoPE是经大量实践验证普适有效且被广泛采用的为数不多的两项架构改进。
在原始Transformer中加入这两项改进的架构也叫Transformer++,Llama、Mistral等最强开源模型均采用该架构。无论Transformer还是Transformer++架构,都可通过DCMHA获得显著改进。
在1.4B模型规模下,DCMHA的改进幅度大于Transformer++的两项改进之和,且扩展性更好(图4下蓝绿线和黑线的对比,DCMHA的改进幅度随算力增加衰减的更慢,以及图4和图5的对比)。
可以说,DCFormer让Transformer的能力又跃上一个新台阶。
下游任务评测
研究团队训练了DCPythia-2.8B和DCPythia-6.9B两个模型在主流NLP下游任务上进行测评并和同规模的开源模型Pythia进行比较(训练采用和Pythia完全相同超参数设置)。
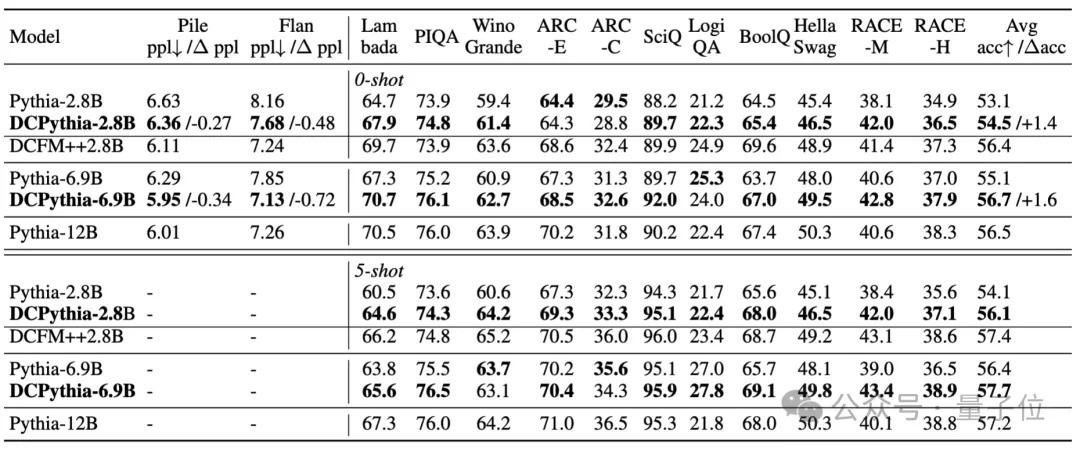
△表1. DCFormer 和 Pythia 在下游任务中的表现
从表1中可以看出,DCPythia-2.8B和6.9B不仅在Pile验证集上的ppl 更低,而且在大部分下游任务上都显著超过了Pythia,DCPythia6.9B在 ppl 和下游任务上的平均准确率甚至超过了Pythia-12B。
DCFormer++2.8B相对于DCPythia-2.8B有进一步的提升,验证了DCMHA和Lllama架构结合的有效性。
训练和推理速度
虽然引入DCMHA会带来额外的训练和推理开销,但是从表2中可以看出DCFormer++的训练速度是Transformer++的74.5%-89.2%,推理速度则是81.1%-89.7%,而且随着模型参数的增长,额外的计算开销会逐渐降低。
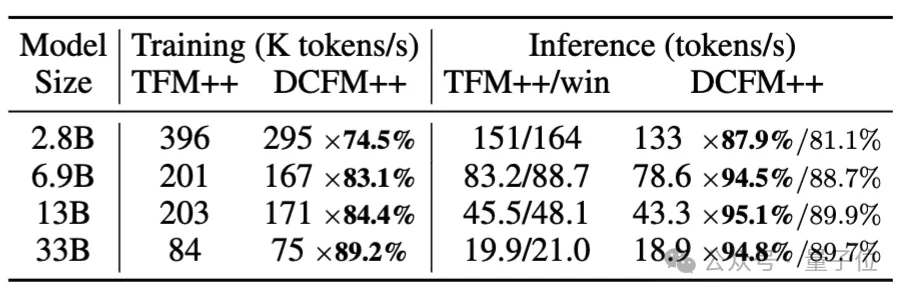
△表2. Transformer++和DCFormer++的训练和推理速度对比
训练速度是在TPU v3 pod,序列长度为2048,batch_size为1k的情况下对比得到的;推理速度是在A100 80G GPU上进行评测的,输入长度1024,生成长度128。
消融实验
结果如下:
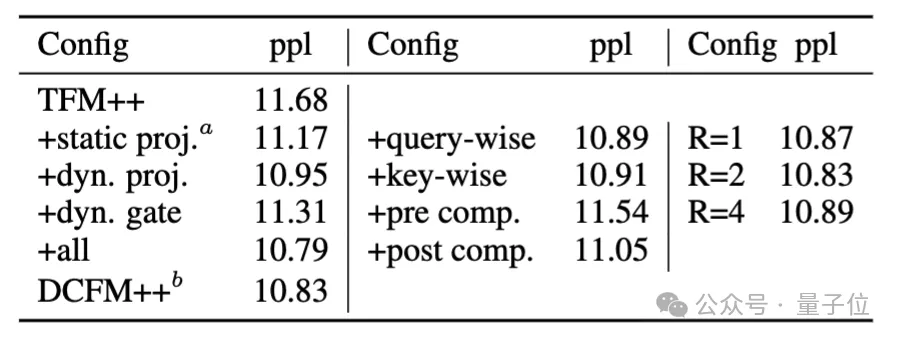
△表3. DCMHA的消融实验
从表3中可以看出以下几点:
- 虽然加入静态的组合权重就可以降低ppl,但引入动态的组合权重可以进一步降低ppl,说明了动态组合的必要性。
- 低秩动态组合比动态门控的效果更好。
- 只用query-wise或者key-wise的动态组合得到的ppl相当,与DCFormer++的差距很小。
- 在softmax后做注意力头组合比在softmax前做更有效,可能是因为softmax后的概率能更直接影响输出。
- 动态组合权重的秩无需设置过大,也说明了组合权重的低秩性。
此外,研究人员还通过增加局部注意力层的比例和只用query-wise动态组合的方式去进一步减少训练和推理开销,详见论文Table 10。
总的来说,研究团队有两点总结。
关于动态权重:近期Mamba,GLA,RWKV6,HGRN等SSM和线性注意力/RNN的工作,通过引入动态(input-dependent)权重的方式,追赶上了Transformer++,但DCFormer用动态组合注意力头的方式说明了在使用 softmax 注意力的情况下,通过引入动态权重也可以大幅提升Transformer++的效果。
关于模型架构创新:这项工作表明,如果存在一个具有极限算力智能转化效率的“理想模型架构”,当前的Transformer架构虽已非常强大,但距离这个理想架构很可能还存在很大的差距,仍有广阔的提升空间。因此,除了堆算力堆数据的大力出奇迹路线,模型架构创新同样大有可为。
研究团队还表示,彩云科技会率先在旗下产品彩云天气、彩云小译、彩云小梦上应用DCformer。
有关更多研究细节,可参阅原始论文。
ICML2024论文链接:https://icml.cc/virtual/2024/poster/34047。
Arxiv 论文链接:https://arxiv.org/abs/2405.08553。
代码链接:https://github.com/Caiyun-AI/DCFormer。
今天带大家了解了的相关知识,希望对你有所帮助;关于科技周边的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
299 收藏
-
科技周边 · 人工智能 | 1天前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-
475 收藏
-
科技周边 · 人工智能 | 5天前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK292 收藏
-
379 收藏
-
394 收藏
-
101 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习