ICML 2024 | 揭示非线形Transformer在上下文学习中学习和泛化的机制
来源:机器之心
时间:2024-06-28 16:49:01 441浏览 收藏
怎么入门科技周边编程?需要学习哪些知识点?这是新手们刚接触编程时常见的问题;下面golang学习网就来给大家整理分享一些知识点,希望能够给初学者一些帮助。本篇文章就来介绍《ICML 2024 | 揭示非线形Transformer在上下文学习中学习和泛化的机制》,涉及到,有需要的可以收藏一下

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者李宏康,美国伦斯勒理工大学电气、计算机与系统工程系在读博士生,本科毕业于中国科学技术大学。研究方向包括深度学习理论,大语言模型理论,统计机器学习等等。目前已在 ICLR/ICML/Neurips 等 AI 顶会发表多篇论文。
上下文学习 (in-context learning, 简写为 ICL) 已经在很多 LLM 有关的应用中展现了强大的能力,但是对其理论的分析仍然比较有限。人们依然试图理解为什么基于 Transformer 架构的 LLM 可以展现出 ICL 的能力。
近期,一个来自美国伦斯勒理工大学和 IBM 研究院的团队从优化和泛化理论的角度分析了带有非线性注意力模块 (attention) 和多层感知机 (MLP) 的 Transformer 的 ICL 能力。他们特别从理论端证明了单层 Transformer 首先在 attention 层根据 query 选择一些上下文示例,然后在 MLP 层根据标签嵌入进行预测的 ICL 机制。该文章已收录在 ICML 2024。

论文题目:How Do Nonlinear Transformers Learn and Generalize in In-Context Learning?
论文地址:https://arxiv.org/pdf/2402.15607
背景介绍
上下文学习 in context learning (ICL)
上下文学习 (ICL) 是一种新的学习范式,在大语言模型 (LLM) 中非常流行。它具体是指在测试查询 (testing query) 前添加 N 个测试样本 testing examples (上下文),即测试输入
前添加 N 个测试样本 testing examples (上下文),即测试输入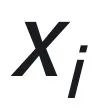 和测试输出
和测试输出 的组合,从而构成一个 testing prompt:
的组合,从而构成一个 testing prompt: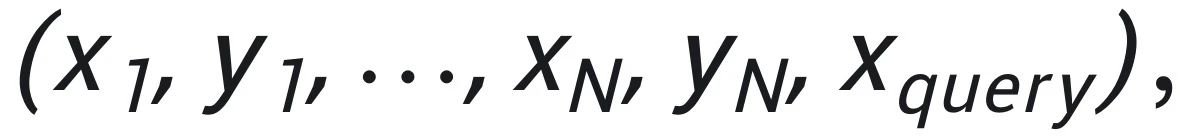 ,作为模型的输入以引导模型作出正确的推断。这种方式不同于经典的对预训练模型进行微调的方式,它不需要改变模型的权重,从而更加的高效。
,作为模型的输入以引导模型作出正确的推断。这种方式不同于经典的对预训练模型进行微调的方式,它不需要改变模型的权重,从而更加的高效。
ICL 理论工作的进展
近期的很多理论工作都是基于 [1] 所提出的研究框架,即人们可以直接使用 prompt 的格式来对 Transformer 进行训练 (这一步也可以理解为在模拟一种简化的 LLM 预训练模式),从而使得模型具有 ICL 能力。已有的理论工作聚焦于模型的表达能力 (expressive power) 的角度 [2]。他们发现,人们能够找到一个有着 “完美” 的参数的 Transformer 可以通过前向运算执行 ICL,甚至隐含地执行梯度下降等经典机器学习算法。但是这些工作无法回答为什么 Transformer 可以被训练成这样 “完美” 的,具有 ICL 能力的参数。因此,还有一些工作试图从 Transformer 的训练或泛化的角度理解 ICL 机制 [3,4]。不过,受制于分析 Transformer 结构的复杂性,这些工作目前止步于研究线性回归任务,而所考虑的模型通常会略去 Transformer 中的非线形部分。
本文从优化和泛化理论的角度分析了带有非线性 attention 和 MLP 的 Transformer 的 ICL 能力和机制:
基于一个简化的分类模型,本文具体量化了数据的特征如何影响了一层单头 Transformer 的域内 (in-domain) 和域外 (out-of-domain, OOD) 的 ICL 泛化能力。
本文进一步阐释了 ICL 是如何通过被训练的 Transformer 来实现了。
基于被训练的 Transformer 的特点,本文还分析了在 ICL 推断的时候使用基于幅值的模型剪枝 (magnitude-based pruning) 的可行性。
理论部分
问题描述
本文考虑一个二分类问题,即将 通过一个任务
通过一个任务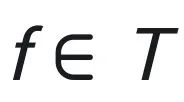 映射到
映射到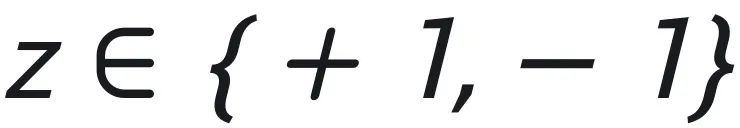 。为了解决这样的一个问题,本文构建了 prompt 来进行学习。这里的 prompt 被表示为:
。为了解决这样的一个问题,本文构建了 prompt 来进行学习。这里的 prompt 被表示为:
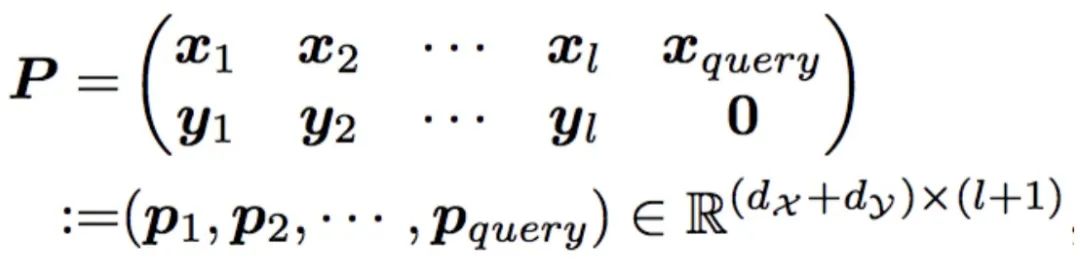
训练网络为一个单层单头 Transformer:
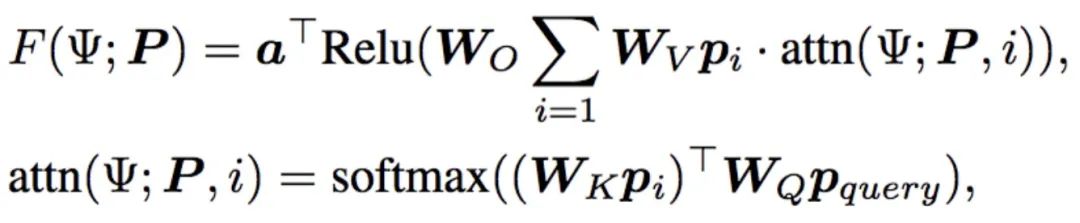
预训练过程是求解一个对所有训练任务的经验风险最小化 (empirical risk minimization)。损失函数使用的是适合二分类问题的 Hinge loss,训练算法是随机梯度下降。
本文定义了两种 ICL 泛化的情况。一个是 in-domain 的,即泛化的时候测试数据的分布和训练数据一样,注意这个情况里面测试任务不必和训练任务一样,即这里已经考虑了对未见任务 (unseen task) 的泛化。另一个是 out-of-domain 的,即测试、训练数据分布不一样。
本文还涉及了在 ICL 推断的时候进行 magnitude-based pruning 的分析,这里的剪枝方式是指对于训练得到的中的各个神经元,根据其幅值大小,进行从小到大的删除。
对数据和任务的构建
这一部分请参考原文的 Section 3.2,这里只做一个概述。本文的理论分析是基于最近比较火热的 feature learning 路线,即通常将数据假设为可分(通常是正交)的 pattern,从而推导出基于不同 pattern 的梯度变化。本文首先定义了一组 in-domain-relevant (IDR) pattern 用于决定 in-domain 任务的分类,和一组与任务无关的 in-domain-irrelevant (IDI) pattern,这些 pattern 之间互相正交。IDR pattern 有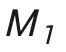 个,IDI pattern 有
个,IDI pattern 有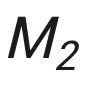 个。一个
个。一个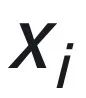 被表示为一个 IDR pattern 和一个 IDI pattern 的和。一个 in-domain 任务就被定义为基于某两个 IDR pattern 的分类问题。
被表示为一个 IDR pattern 和一个 IDI pattern 的和。一个 in-domain 任务就被定义为基于某两个 IDR pattern 的分类问题。
类似地,本文通过定义 out-of-domain-relevant (ODR) pattern 和 out-of-domain-irrelevant (ODI) pattern,可以刻画 OOD 泛化时候的数据和任务。
本文对 prompt 的表示可以用下图的例子来阐述,其中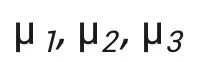 是 IDR pattern,
是 IDR pattern,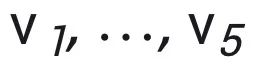 是 IDI pattern。这里在做的任务是基于 x 中的
是 IDI pattern。这里在做的任务是基于 x 中的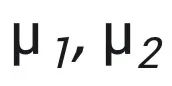 做分类,如果是
做分类,如果是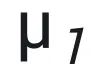 那么其标签为 + 1,对应于 +q,如果是
那么其标签为 + 1,对应于 +q,如果是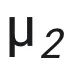 那么其标签为 - 1,对应于 -q。α,α' 分别被定义为训练和测试 prompt 中跟 query 的 IDR/ODR pattern 一样的上下文示例。下图中的例子里面,
那么其标签为 - 1,对应于 -q。α,α' 分别被定义为训练和测试 prompt 中跟 query 的 IDR/ODR pattern 一样的上下文示例。下图中的例子里面,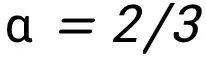 。
。

理论结果
首先,对于 in-domain 的情况,本文先给了一个 condition 3.2 来规定训练任务需要满足的条件,即训练任务需要覆盖所有的 IDR pattern 和标签。然后 in-domain 的结果如下:

这里表明:1,训练任务的数量只需要在全部任务中占比达到满足 condition 3.2 的小比例,我们就可以对 unseen task 实现很好的泛化;2,跟当前任务相关的 IDR pattern 在 prompt 中的比例越高,就可以以更少的训练数据,训练迭代次数,以及更短的 training/testing prompt 实现理想的泛化。
接下来是 out-of-domain 泛化的结果。

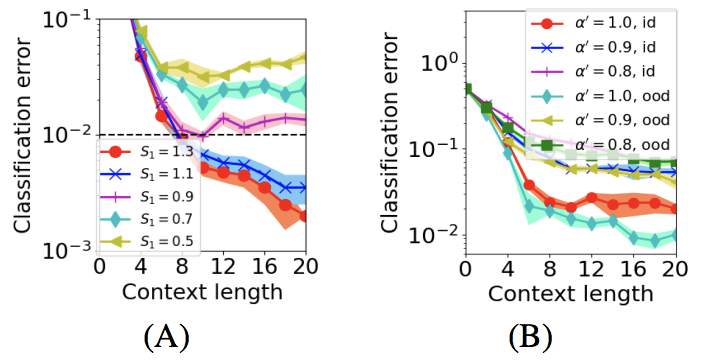
这里说明,如果 ODR pattern 是 IDR pattern 的线性组合且系数和大于 1,那么此时 OOD ICL 泛化可以达到理想的效果。这个结果给出了在 ICL 的框架下,好的 OOD 泛化所需要的训练和测试数据之间的内在联系。该定理也通过 GPT-2 的实验得到了验证。如下图所示,当 (12) 中的系数和 大于 1 的时候,OOD 分类可以达到理想的结果。与此同时,当
大于 1 的时候,OOD 分类可以达到理想的结果。与此同时,当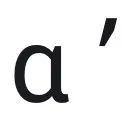 ,即 prompt 中和分类任务相关的 ODR/IDR pattern 比例越高的时候,所需要的 context 长度越小。
,即 prompt 中和分类任务相关的 ODR/IDR pattern 比例越高的时候,所需要的 context 长度越小。
然后,本文给出了带有 magnitude-based pruning 的 ICL 泛化结果。

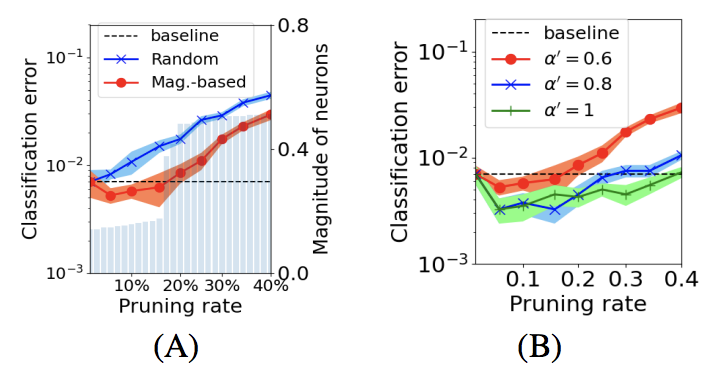
这个结果表明,首先,训练得到的 中有一部分(常数比例)神经元的幅值很小,而剩下的相对比较大(公式 14)。当我们只枝剪小神经元的时候,对泛化结果基本没有影响,而当枝剪比例增加到要剪大神经元的时候,泛化误差会随之显著变大(公式 15,16)。以下实验验证了定理 3.7。下图 A 中浅蓝色的竖线表示训练得到的
中有一部分(常数比例)神经元的幅值很小,而剩下的相对比较大(公式 14)。当我们只枝剪小神经元的时候,对泛化结果基本没有影响,而当枝剪比例增加到要剪大神经元的时候,泛化误差会随之显著变大(公式 15,16)。以下实验验证了定理 3.7。下图 A 中浅蓝色的竖线表示训练得到的 呈现出了公式 14 的结果。而对小神经元进行枝剪不会使泛化变差,这个结果符合理论。图 B 反映出当 prompt 中和任务相关的上下文越多的时候,我们可以允许更大的枝剪比例以达到相同的泛化性能。
呈现出了公式 14 的结果。而对小神经元进行枝剪不会使泛化变差,这个结果符合理论。图 B 反映出当 prompt 中和任务相关的上下文越多的时候,我们可以允许更大的枝剪比例以达到相同的泛化性能。
ICL 机制
通过对预训练过程的刻画,本文得到了单层单头非线性 Transformer 做 ICL 的内在机制,这一部分在原文的 Section 4。该过程可以用下图表示。
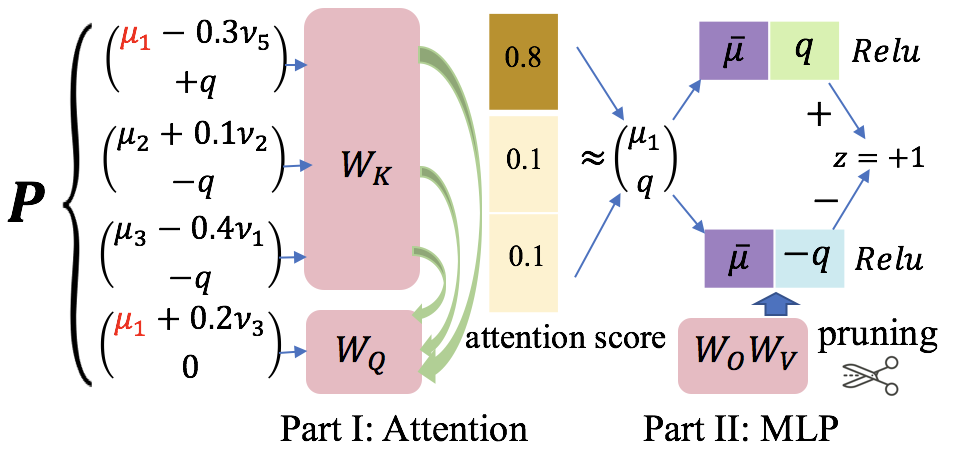
简而言之,attention 层会选择和 query 的 ODR/IDR pattern 一样的上下文,赋予它们几乎全部 attention 权重,然后 MLP 层会重点根据 attention 层输出中的标签嵌入来作出最后的分类。
总结
本文讲解了在 ICL 当中,非线性 Transformer 的训练机制,以及对于新任务和分布偏移数据的泛化能力。理论结果对于设计 prompt 选择算法和 LLM 剪枝算法有一定实际意义。
参考文献
[1] Garg, et al., Neurips 2022. "What can transformers learn in-context? a case study of simple function classes."
[2] Von Oswald et al., ICML 2023. "Transformers learn in-context by gradient descent."
[3] Zhang et al., JMLR 2024. "Trained transformers learn linear models in-context."
[4] Huang et al., ICML 2024. "In-context convergence of transformers."
好了,本文到此结束,带大家了解了《ICML 2024 | 揭示非线形Transformer在上下文学习中学习和泛化的机制》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多科技周边知识!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 6天前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-
475 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK292 收藏
-
379 收藏
-
394 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习