Scaling Law瓶颈,Cursor编程为什么这么强?团队参与新研究掏出秘密武器
来源:机器之心
时间:2024-09-17 13:30:56 272浏览 收藏
知识点掌握了,还需要不断练习才能熟练运用。下面golang学习网给大家带来一个科技周边开发实战,手把手教大家学习《Scaling Law瓶颈,Cursor编程为什么这么强?团队参与新研究掏出秘密武器》,在实现功能的过程中也带大家重新温习相关知识点,温故而知新,回头看看说不定又有不一样的感悟!
近段时间,AI 编程工具 Cursor 的风头可说是一时无两,其表现卓越、性能强大。近日,Cursor 一位重要研究者参与的一篇相关论文发布了,其中提出了一种方法,可通过搜索自然语言的规划来提升 Claude 3.5 Sonnet 等 LLM 的代码生成能力。
具体来说,他们提出的方法名为 PlanSearch(规划搜索)。主导团队是 Scale AI,本文一作为 Scale AI 研究者 Evan Wang。二作 Federico Cassano 现已加入如今炙手可热的 AI 编程工具公司 Cursor。他曾参与创立了 GammaTau AI 项目,该项目的目标是实现 AI 编程的民主化。此外,他也是 BigCode 项目的活跃贡献者,该项目负责开发用于 AI 编程的 StarCoder 系列大型语言模型。

论文标题:Planning In Natural Language Improves LLM Search For Code Generation
论文地址:https://arxiv.org/pdf/2409.03733
论文开篇,该团队提到强化学习教父 Sutton 的经典文章《The Bitter Lesson(苦涩的教训)》揭示的 Scaling Law 的两大核心原则:学习和搜索。随着大型语言模型的迅猛发展,人们对于「学习」是否有效的疑虑已基本消除。然而,在传统机器学习领域中表现出色的「搜索」策略,将如何拓展大模型的能力,还是个未知数。
目前阻碍模型应用「搜索」的主要难题是模型给出的答案过于雷同,缺乏多样性。这可能是由于在预训练的基础上,模型会在特定的数据集上进行进一步的训练,以适应特定的应用场景或任务所导致的。
经过大量实证研究证明,许多大语言模型往往会被优化,以产生一个正确的答案。比如下图中所示,DeepSeek-Coder-V2-Lite-Base 的表现不如其基础模型,但随着回答的多样性的减少,情况发生了逆转。多个模型都存在这种现象:经过特别指令调整的模型在只生成一个答案的情况下(pass@1)通常比基础模型表现得好很多,但当需要生成多个答案时,这种优势就不明显了 —— 在某些情况下,甚至完全相反。
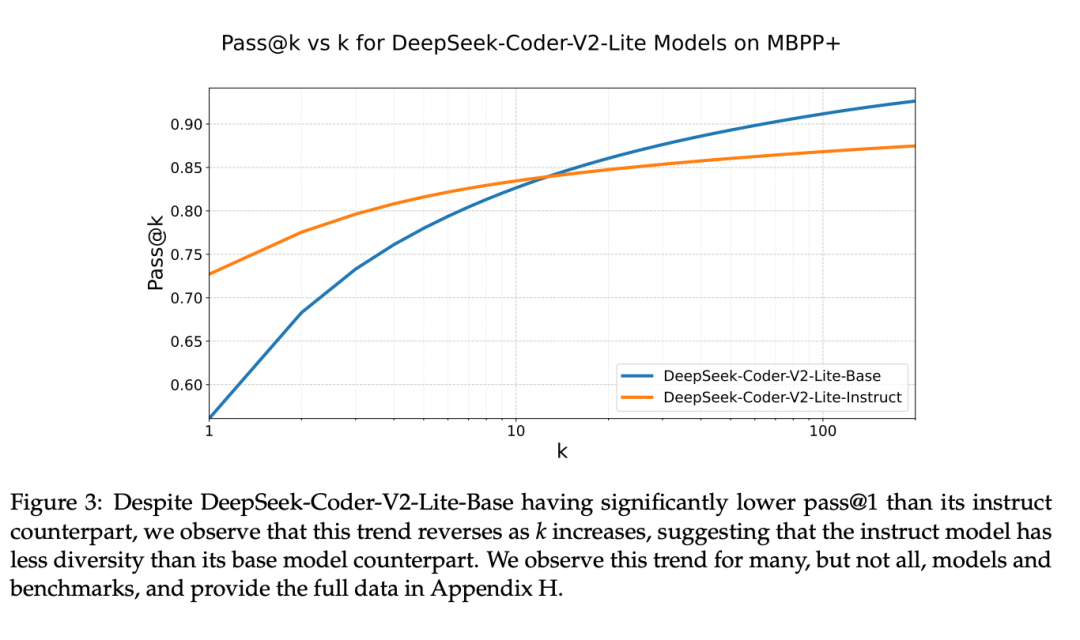
模型在生成答案时缺乏多样性,这对于搜索的效果非常不利。特别是在极端情况,比如采用「贪心解码」,模型给出的答案会非常相似,因为它们是从模型中重复抽取的。这种情况下,即使模型花费更多推理时间,也难以获得更好的搜索结果。
通行的大模型排行榜,例如例如 LMSYS Chatbot Arena、LiveCodeBench、OpenLLMLeaderboard,很难反应模型在回答多样性方面的不足。这些排行榜主要关注模型在单一样本上的通过率,没有考虑到模型在更广泛场景下的表现。由于模型需要很快地响应用户的需求,单一样本的回答质量是衡量一个聊天机器人的关键指标,但这一指标并不足以全面评估模型在允许更充裕推理时间时的综合性能。
针对以上问题,研究人员对如何在大语言模型推理过程中提高回答的多样性进行了探索。对此,他们提出了假设,想让模型输出的答案更加丰富,需要在自然语言的概念或想法的空间内进行搜索。
为了验证这个假设,研究人员进行了一系列实验。首先,研究人员发现,如果给模型一些简单的草图(这些草图是从已经能解决问题的代码中「回译」而来),模型就能根据这些草图写出正确的最终程序。其次,研究人员还发现,如果让模型在尝试解决问题之前,先在 LiveCodeBench 上想出一些点子(这个过程叫做 IdeaSearch / 思路搜索),然后看看模型能不能用这些点子解决问题。
结果发现,模型要么完全解决不了问题(准确度为 0%),要么就能完美解决问题(准确度为 100%)。这表明当模型尝试解决一个问题时,成功与否主要取决于它最初的那个想法(草图)对不对。
根据这两个实验的结果,研究人员认为一种提升 LLM 代码搜索能力的自然方法是:搜索正确的思路,然后实现它!
于是,规划搜索(PlanSearch)方法诞生了。
不同于之前的搜索方法(通常是搜索单个 token、代码行甚至整个程序)不一样,规划搜索是搜索解决当前问题的可能规划。这里,规划(plan)的定义是:有助于解决某个特定问题的高层级观察和草案的集合。
为了生成新规划,规划搜索会生成大量有关该问题的观察,然后再将这些观察组合成用于解决问题的候选规划。
这个操作需要对生成的观察的每个可能子集都执行,以最大化地鼓励在思路空间中进行探索,之后再将结果转译成最终的代码解决方案。
该团队的实验发现,在推理时有效使用计算方面,规划搜索方法优于标准的重复采样方法以及直接搜索思路的方法。
方法
在这项研究中,该团队探索了多种不同方法,包括重复采样(Repeated Sampling)、思路搜索(IdeaSearch)以及新提出的规划搜索(PlanSearch)。其中前两种方法顾名思义,比较直观,这里我们重点关注新提出的规划搜索。
该团队观察到,虽然重复采样和思路搜索能成功地提升基准评测的结果。但在很多案例中,多次提示(pass@k)(即使在温度设置很高)只会导致输出代码发生很小的变化,这些变化只会改变一些小方面,但无法改善思路中的缺陷。
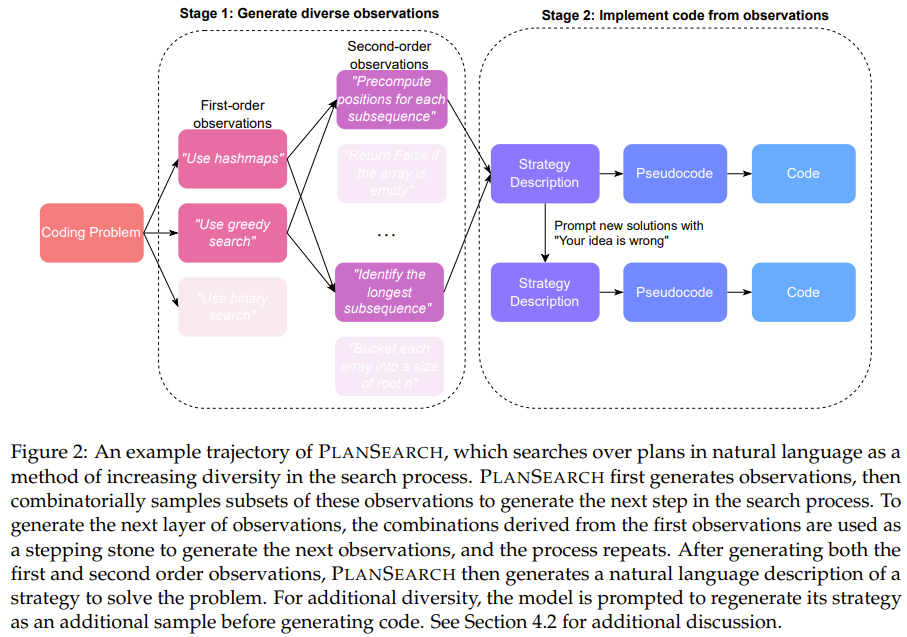
下面来看具体的规划搜索过程:
1. 通过提示来获取观察
首先假设有一个问题陈述 P,通过向 LLM 发送提示词来获取对该问题的「观察」/ 提示。这里将这些观察记为 O^1_i,其中 i ∈ {1, . . . , n_1};这是因为它们是一阶观察。通常而言,n_1 的数量级在 3 到 6 之间。具体数量取决于 LLM 输出。为了利用这些观察结果来启发未来的思路,该团队创建了 O^1_i 的集合 S^1 的且大小至多为 2 的所有子集。其中每个子集都是观察结果的一个组合。这里将每个子集记为 C^1_i,其中 i ∈ {1, . . . , l_1},而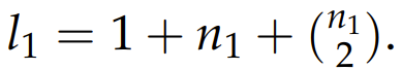
2. 推导新的观察
这样一来,所有观察结果的集合都可以定义为深度为 1 的有向树,其中根节点为 P,并且每个 C^1_i 都有一条从 P 指向 C^1_i 的边。
然后,在每个叶节点 C^1_i 上重复上一步流程,从而生成一个二阶观察集 S^2。为了得到二阶观察,该团队的做法是在给模型的提示词中包含原始问题 P 和 C^1_i 中包含的所有观察 —— 这些观察被构造为解决 P 所必需的原始观察。然后再提示 LLM,让其使用 / 合并在 C^1_i 中找到的观察来得出新的观察。
这个过程可以继续延伸,但由于计算限制,这里在深度为 2 时对该树进行了截断操作。
3. 将观察变成代码
在得到了观察之后,必须先将它们实现成具体思路,然后再将它们转译成代码。
具体来说,对于每个叶节点,将所有观察以及原始问题 P 放入提示词来调用 LLM,以便生成问题 P 的自然语言解决方案。为了提升多样性,对于每个生成的思路,该团队通过假设该思路是错误的来生成一个额外的思路,并要求 LLM 给出批评 / 反馈,从而将提议的思路翻倍了。
然后,再将这些自然语言解决方案转译成伪代码;再把这些伪代码转译成真正的 Python 代码。
实验
实验采用了三个评估基准:MBPP+、HumanEval+ 和 LiveCodeBench。参数设置等细节请参阅原论文。
至于结果,该团队报告了三种方法的结果,包括重复采样、思路搜索和规划搜索,见表 1、图 1 和图 5。
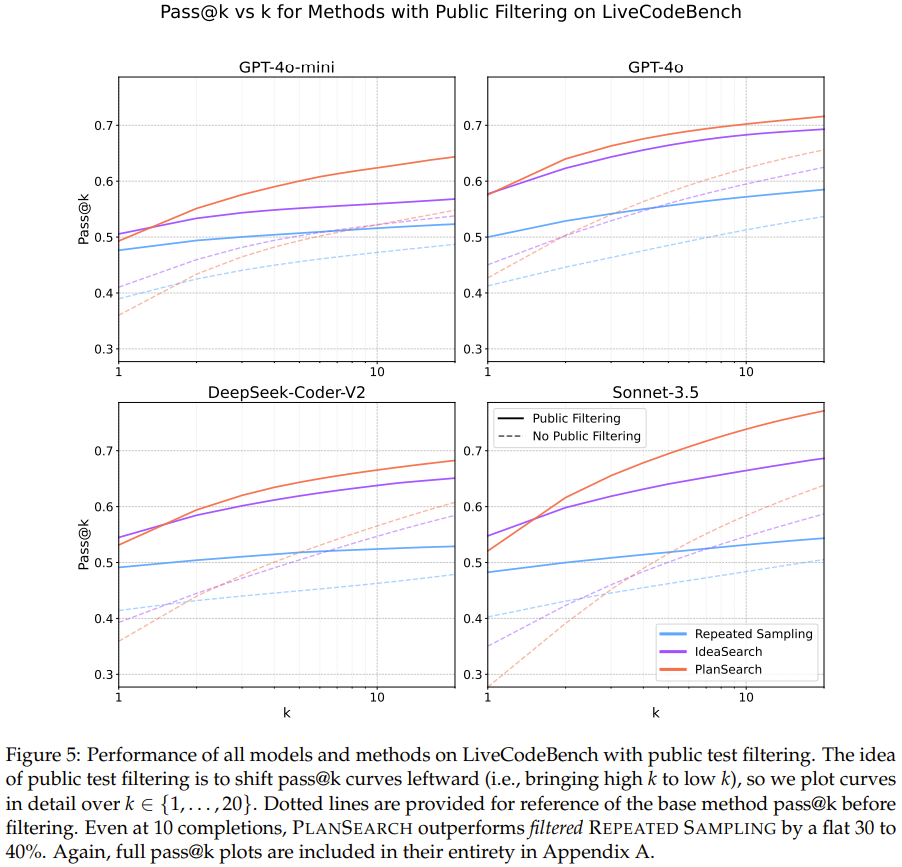
可以看到,规划搜索和思路搜索的表现明显优于基础的采样方法,其中规划搜索方法在所有实验方法和模型上都取得了最佳分数。
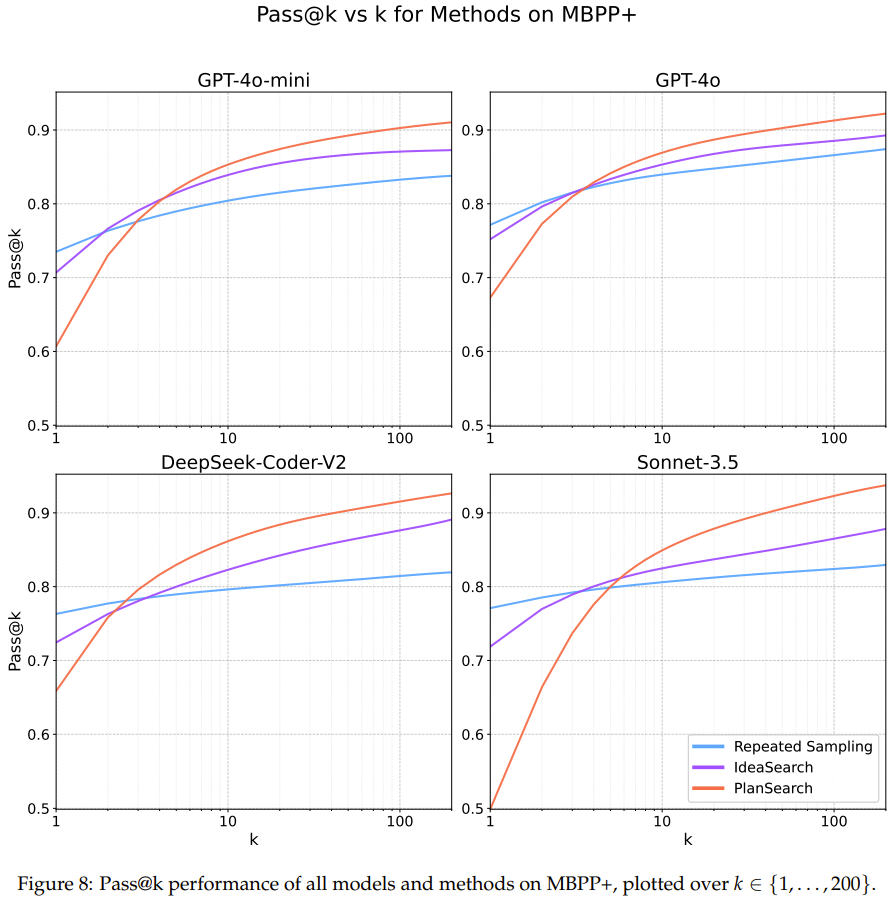
图 7、8、9 展示了在每个数据集上的详细 pass@k 结果。
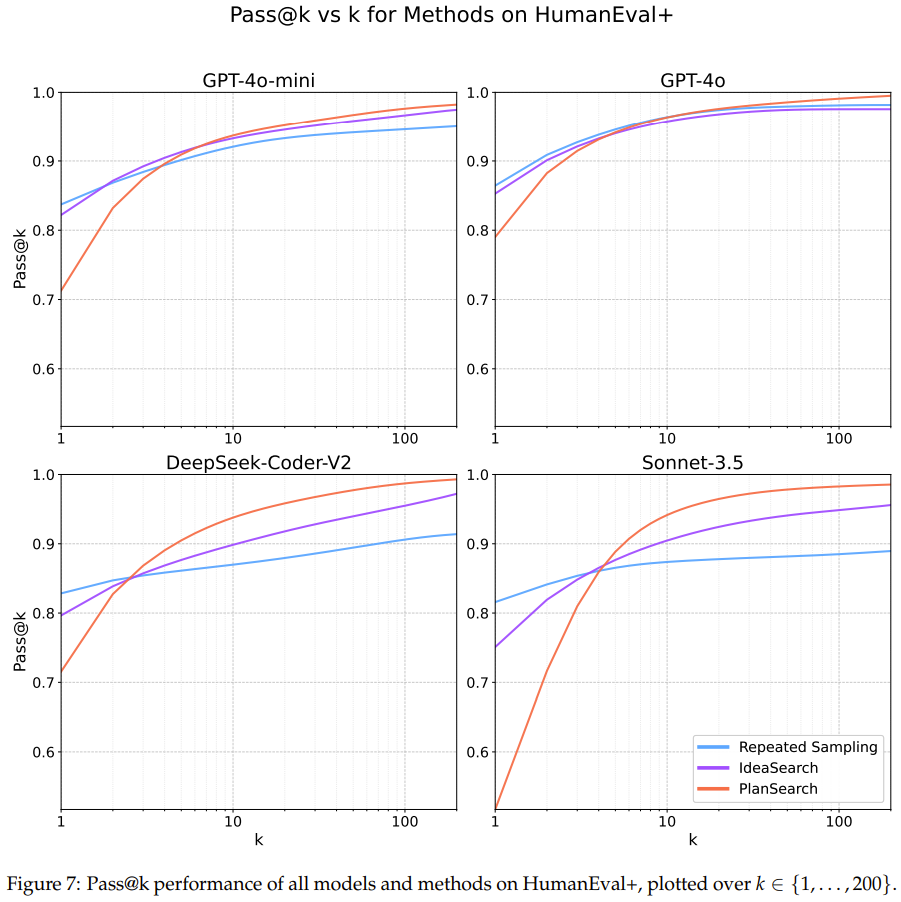
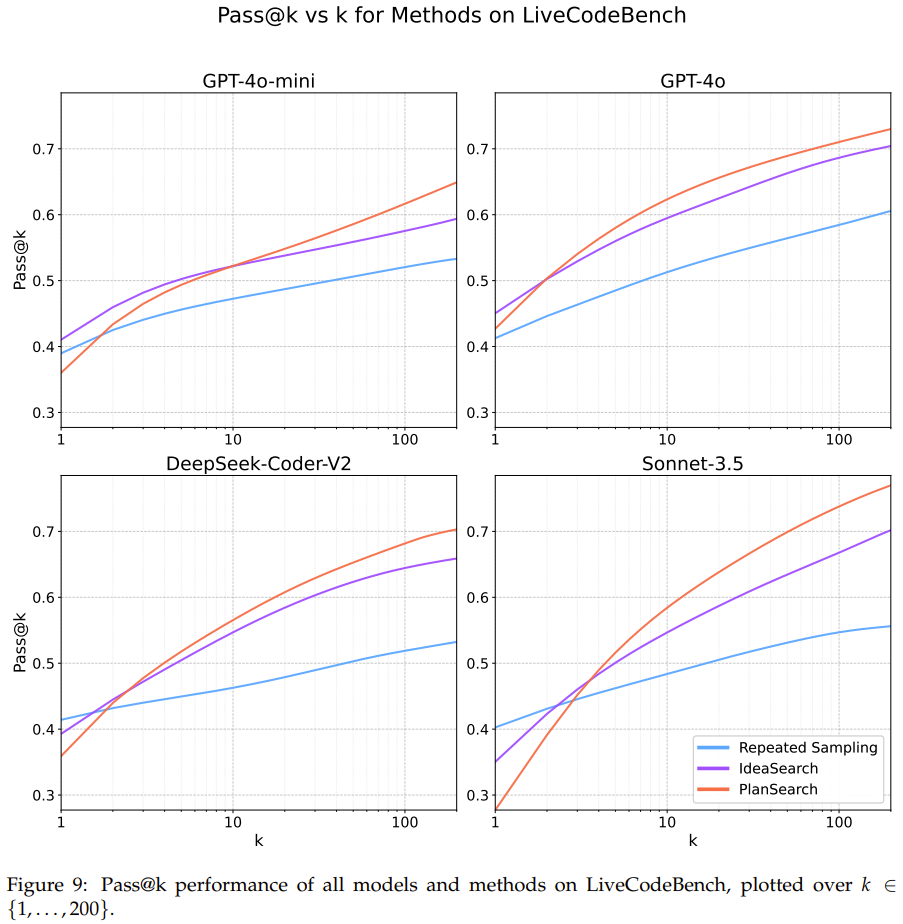
可以看到,在 Claude 3.5 Sonnet 上使用规划搜索方法时,在 LiveCodeBench 基准上得到了当前最佳的 pass@200 性能:77.0%。该表现优于不使用搜索时获得的最佳分数(pass@1 = 41.4%)以及标准的 best-of-n 采样方法的分数(pass@200 = 60.6%)。
此外,使用小型模型(GPT-4o-mini)执行规划搜索时,仅仅 4 次尝试后就能胜过未使用搜索增强的大型模型。这佐证了近期一些使用小模型进行搜索的有效性的研究成果。
在另外两个编程基准 HumanEval+ 和 MBPP+ 上,规划搜索也能带来类似的提升。
通过研究特定模型的差异,该团队注意到 pass@k 曲线所呈现的趋势在所有模型中并不统一;事实上,每条曲线看起都不一样。该团队猜想部分原因是思路多样性的变化。
该团队还得到了一个有趣的观察结果:规划搜索并不利于某些模型的 pass@1 指标,其中最明显的是 Sonnet 3.5 在 LiveCodeBench 上的表现 —— 这是实验中表现最好的组合。
该团队基于直觉给出了解释:提升思路多样性可能会降低生成任何特定思路的概率,同时增加在给定池中至少有一个正确思路的几率。因此,pass@1 可能会略低于平常,但也正是由于这个原因,pass@k 指标可能会优于缺乏多样性的思路池。
另外,表 1 和图 1 给出了在尝试 / 完成上经过归一化的主要结果。其中针对每个问题,每种搜索方法都可以尝试 k 次。
最后,该团队还发现,在思路空间中观察到的多样性可用于预测搜索性能,这可通过模型 / 方法的 pass@1 与其 pass@200 之间的相对改进计算得到,如图 6 所示。
虽然熵是最常见的多样性度量是,但由于种种原因,熵不足以精确衡量 LLM 的多样性。
因此,该团队测量多样性的做法是在所有生成的程序上使用简单的配对策略,将其置于思路空间中进行计算。具体算法请访问原论文。
好了,本文到此结束,带大家了解了《Scaling Law瓶颈,Cursor编程为什么这么强?团队参与新研究掏出秘密武器》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多科技周边知识!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
468 收藏
-
科技周边 · 人工智能 | 1天前 | 人工智能 · ai agent · AI应用 · 工具调用 · 权限边界 · 审计链路 · 人工智能 权限控制 AI Agent 工具调用 审批链路 审计回放 上线指标343 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计427 收藏
-
154 收藏
-
309 收藏
-
234 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream448 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 3星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习