首个Mamba+Transformer混合架构多模态大模型来了,实现单卡千图推理
来源:机器之心
时间:2024-09-23 17:06:46 121浏览 收藏
“纵有疾风来,人生不言弃”,这句话送给正在学习科技周边的朋友们,也希望在阅读本文《首个Mamba+Transformer混合架构多模态大模型来了,实现单卡千图推理》后,能够真的帮助到大家。我也会在后续的文章中,陆续更新科技周边相关的技术文章,有好的建议欢迎大家在评论留言,非常感谢!
本文作者来自于香港中文大学深圳和深圳大数据研究院。其中第一作者为香港中文大学深圳博士生王熙栋和研究助理宋定杰,主要研究方向分别为医疗AGI和多模态学习;博士生陈舒年研究方向为多模态学习,博士生张辰研究方向为高效语言模型。通讯作者为香港中文大学深圳数据科学学院王本友教授。


论文地址:https://arxiv.org/abs/2409.02889 项目地址:https://github.com/FreedomIntelligence/LongLLaVA
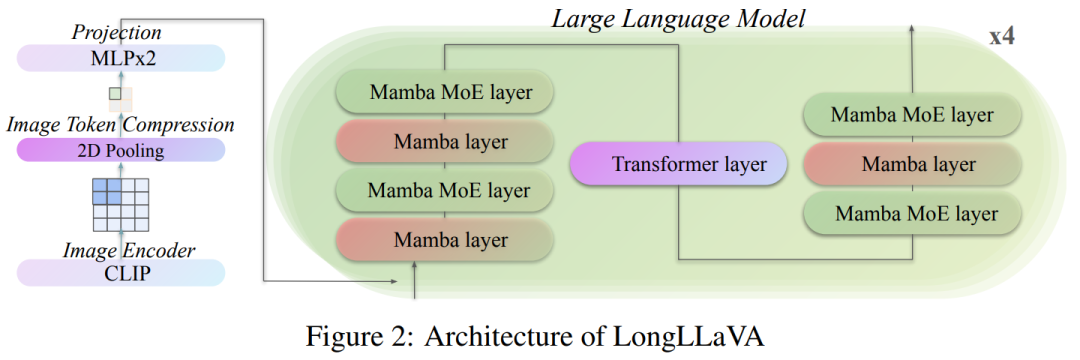
对于多模态架构,采用结合 Transformer 和 Mamba 的混合架构,并提出了一种高效图像表示方法,该方法对图像 Token 应用 2D 池化以降低计算成本同时保持性能。 对于数据构建,为不同的任务设计了独特的格式,使模型能够区分图像之间的时间和空间的依赖关系。 在训练策略方面,采用了一种三阶段的多模态自适应方法 —— 单图像对齐、单图像指令调整和多图像指令调整 —— 以逐步提升模型处理多模态长上下文的能力。

常规单图和多图输入:使用 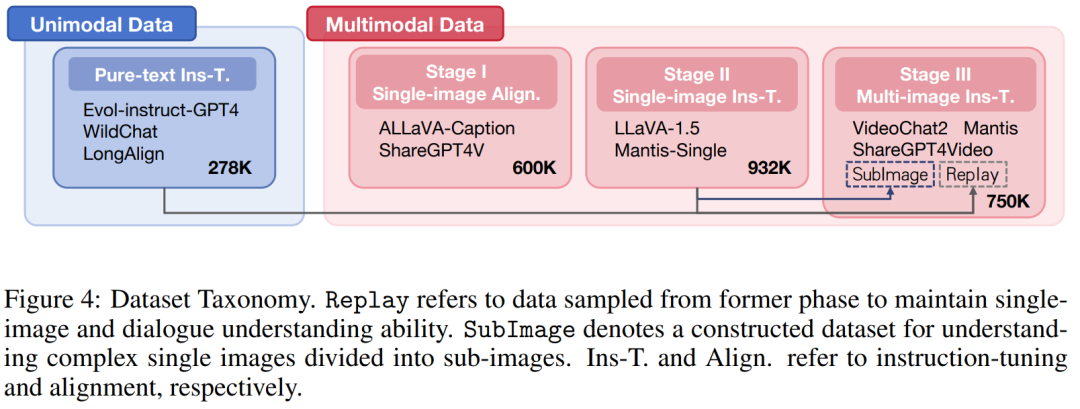
在多模态自适应方面,在 LLaVA 中 “单图像对齐” 和 “单图像指令微调” 阶段之后,团队引入了 “多图像指令微调” 阶段,逐步增强模型的多模态长上下文能力。采用渐进式训练不仅是为了更好地控制变量,也是为了增加模型的可重用性。具体的数据集使用情况如图 4 所示。 第一阶段:单图像对齐。这一阶段是为了将视觉模态特征与文本模态进行对齐。团队使用了 ALLaVA-Caption 和 ShareGPT4V 等数据集,这些数据集包含大约 600K 个高质量的图像 - 字幕对。在此阶段,仅训练映射器,同时冻结视觉编码器和 LLM 的参数。 第二阶段:单图像指令微调。这个阶段的目的是赋予模型多模态指令遵循能力。团队使用了 LLaVA-1.5 和 Manti-Single 等数据集,总共有约 932K 个高质量的问答对。在此过程中,只冻结了视觉编码器,而映射器和 LLM 部分进行训练。 第三阶段:多图像指令微调。在这一阶段,模型被训练以在多模态长文本场景中遵循指令。团队分别从 Mantis、VideoChat2 和 ShareGPT4Video 中采样 200K、200K 和 50K 数据项。为了保留模型的单图像理解和纯文本对话能力,团队将来自单图像指令微调和纯文本指令微调阶段的额外 200K 和 50K 数据项作为 Replay 部分。此外,为了提高模型解释复杂单图像(分割成多个子图像)的能力,团队从单图像指令微调阶段采样 50K 条数据,进行填充和分割,将原始图像分割成尺寸为 336x336 的子图像作为 SubImage 部分。 3. 评估结果 3.1 主要结果 如表 2 所示,LongLLaVA 在 MileBench 上表现出色,甚至超过了闭源模型Claude-3-Opus,尤其在检索任务方面表现出色。突显其在处理多图像任务方面的强大能力。 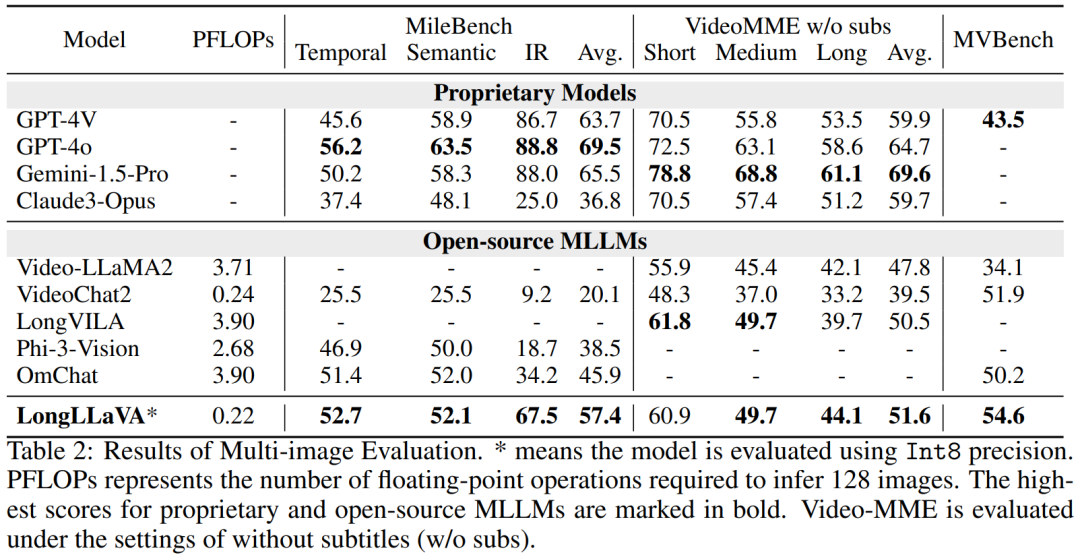
LongLLaVA 在涉及中等至长视频的任务中表现出色,超越了传统的视频模型,如 Video-LLaMA2 和 VideoChat2。在取得了这些令人印象深刻结果的同时,LongLLaVA 的 FLOPs 比其他模型少一个数量级。 3.2 长上下文大型语言模型的诊断评估 考虑到以前的评估不能充分捕捉 MLLM 在长语境下的能力,团队采用了一个新的诊断评估集 VNBench,以进一步分析模型在长语境下的原子能力。VNBench 是一个基于合成视频生成的长上下文诊断任务框架,包括检索、排序和计数等任务。 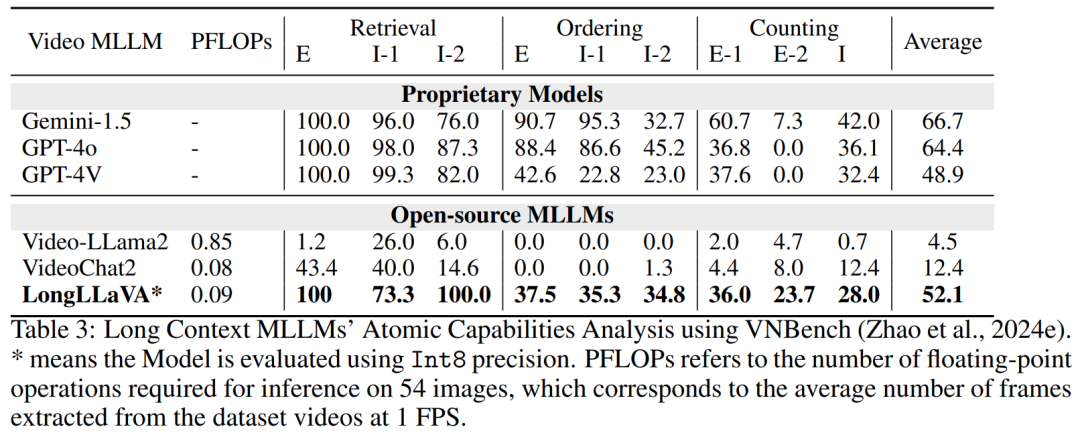
结果显示如表 3 所示,LongLLaVA 在跨语境检索、排序和技术能力等任务中的表现与领先的闭源模型相当,甚至在某些方面超过了 GPT-4V。在开源模型中,LongLLaVA 也展现出其卓越的性能。展示了 LongLLaVA 在管理和理解长上下文方面的先进能力。 3.3 消融实验 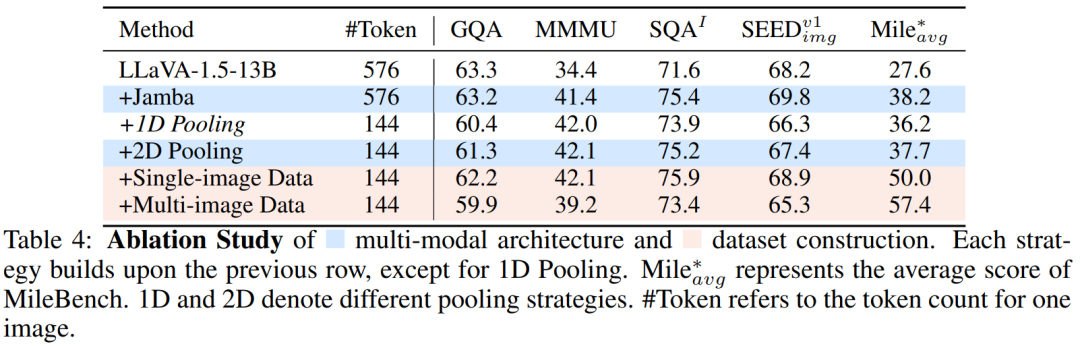
表 4 中显示,使用具有相同数据的混合 LLM 架构,在评估集中都观察到了显著的改进,证明了其在多模态场景中的潜力。对于 Token 压缩,选择了 2D 池化,这显著减少了计算负载,同时将性能下降控制在可接受范围内。与 1D 池化相比,2D 池化方法得到更好的结果。在数据构建方面,在训练团队的单图像数据后,模型在 SEEDBench 上的准确率提高了 1.5%,在 MileBench 上提高了 12.3%。随后的多图像训练使得 MileBench 上的准确率进一步提高了 7.4%,验证了数据集构建的有效性。 4. 更多分析 为了解 LongLLaVA 的内部工作原理和跨模态长文本处理能力,该团队进行了进一步分析。 4.1 关于混合架构的动机 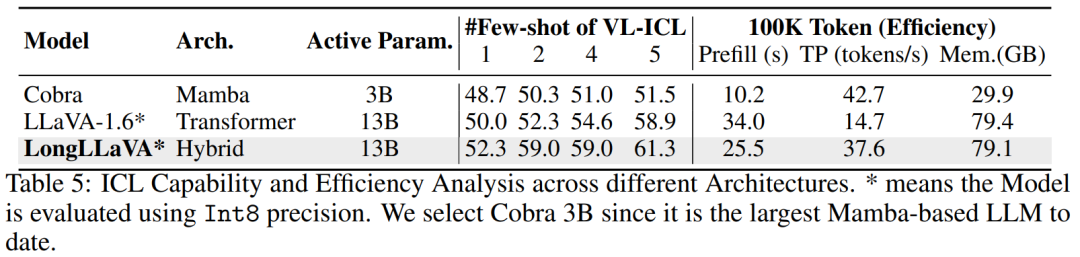
团队探讨了不同架构在 ICL 能力和推理效率方面的优缺点,强调了混合架构的平衡优势。 ICL 分析。团队评估了在 VL-ICL 基准测试中对多模态情境学习中匹配图像任务的性能。该任务的输入包含一个图像对,输出表示是否存在特定的关系。MLLM 需要从示例中学习关系。如表 5 所示,混合架构和 Transformer 架构随着示例数量的增加表现出快速的性能提升,而 Mamba 架构的提升较少,证实了其在情境学习方面的不足。 效率分析。团队关注三个方面:预填充时间(首次推理延迟)、吞吐量(每秒生成的下一个 Token 数)和内存使用。团队将输入文本长度控制在 100K,并测量生成 1 个 Token 和 1000 个 Token 的输出所需的时间和最大内存使用。吞吐量计算为 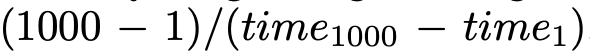 。为了更好地模拟实际应用场景,使用 vLLM 框架和 Int8 量化评估了 Transformer 和混合架构。如表 5 所示,Mamba 架构具有最快的预填充时间,最高的吞吐量。与具有相似推理参数的 Transformer 架构相比,混合架构实现了 2.5 倍的吞吐量,75% 的预填充时间,并减少了内存使用。
。为了更好地模拟实际应用场景,使用 vLLM 框架和 Int8 量化评估了 Transformer 和混合架构。如表 5 所示,Mamba 架构具有最快的预填充时间,最高的吞吐量。与具有相似推理参数的 Transformer 架构相比,混合架构实现了 2.5 倍的吞吐量,75% 的预填充时间,并减少了内存使用。4.2 图像数量的缩放定律 随着可处理图像数量的增加,模型能够支持更多图像块以进行高分辨率图像理解,以及使用更多视频帧进行视频理解。为了探索增加子图像和视频帧数量的影响,团队分别在 V* Bench 和 Video-MME 基准测试上评估了 LongLLaVA。 增加子图像数量。V* Bench 评估了一个模型在大型图像中定位小目标的能力。如图 5 所示,最初增加子图像的数量显著提高了模型性能,表明模型对图像细节的理解更好。然而,团队也发现,进一步增加子图像的数量略微降低了性能,这表明过多的子图像可能会干扰在此任务上的性能。 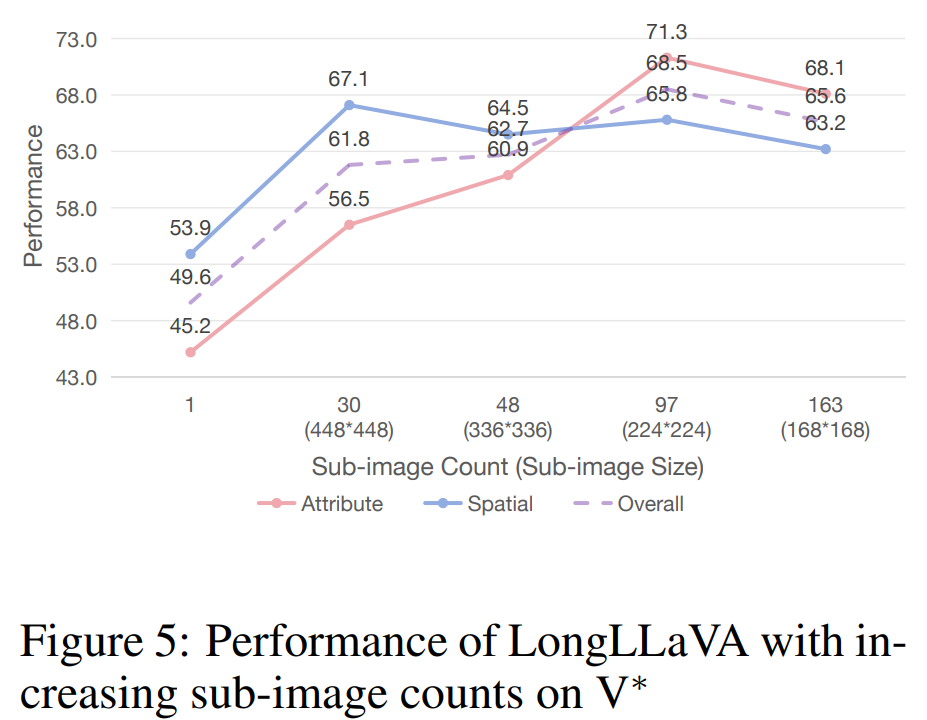
增加帧数规模。视频多模态编码器是一个测试模型从视频中提取信息能力的基准。从图 6 中可以看到,随着采样帧数的增加,模型在基准测试中的性能显著提高,当提取 256 帧时达到峰值。这表明模型能够有效地理解和利用额外采样帧中包含的信息,以提供更好的响应。 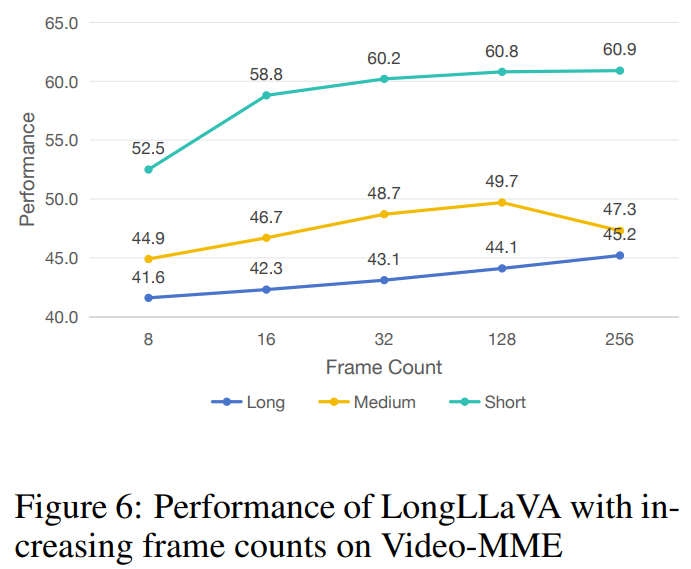
5. 进一步将图像数量扩大到 1000 利用 LongVA 中提出的 V-NIAH 评估框架,团队进行了 “大海捞针” 测试来评估模型性能。考虑到模型的训练序列长度限制为 40,960 个 token,采用 token 池化技术将原始 token 数量从 144 个减少到 36 个。这种调整能够高效地从大量数据集中检索相关信息。如图 7 所示,模型在 1000 张图像集上实现了近 100% 的检索准确率,而无需额外的训练。 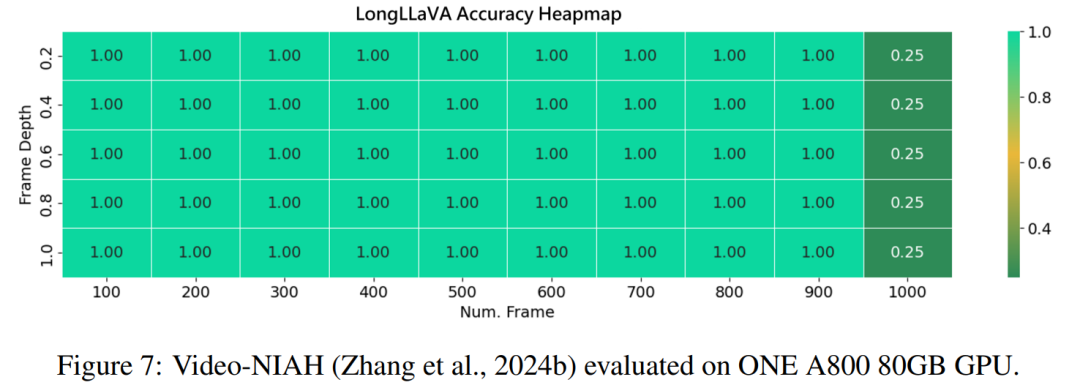
然而,当增加测试图像数量超过 1,000 张时,团队观察到检索准确率下降。这种性能下降可能是因为超出了模型的训练序列长度,这可能会影响其保持更多图像准确性的能力。在未来的工作中团队将延长训练序列长度至 140,000 Token,即 LongLLaVA 进行单卡推理的极限长度,以进一步释放模型潜力。 6. 结论 LongLLaVA(长上下文大型语言和视觉助手)这一创新性混合架构模型,在长上下文多模态理解方面表现出色。该模型集成了 Mamba 和 Transformer 模块,利用多个图像之间的时空依赖性构建数据,并采用渐进式训练策略。 LongLLaVA 在各种基准测试中表现出竞争性的性能,同时确保了效率,为长上下文多模态大型语言模型(MLLMs)设定了新的标准。 好了,本文到此结束,带大家了解了《首个Mamba+Transformer混合架构多模态大模型来了,实现单卡千图推理》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多科技周边知识!
声明:本文转载于:机器之心 如有侵犯,请联系study_golang@163.com删除

相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
199 收藏
-
412 收藏
-
149 收藏
-
274 收藏
-
436 收藏
-
258 收藏
-
494 收藏
-
187 收藏
-
414 收藏
-
159 收藏
-
430 收藏
-
223 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习