微调大模型,AMD MI300X就够了!跟着这篇博客微调Llama 3.1 405B,效果媲美H100
来源:机器之心
时间:2024-10-08 19:03:33 257浏览 收藏
IT行业相对于一般传统行业,发展更新速度更快,一旦停止了学习,很快就会被行业所淘汰。所以我们需要踏踏实实的不断学习,精进自己的技术,尤其是初学者。今天golang学习网给大家整理了《微调大模型,AMD MI300X就够了!跟着这篇博客微调Llama 3.1 405B,效果媲美H100》,聊聊,我们一起来看看吧!

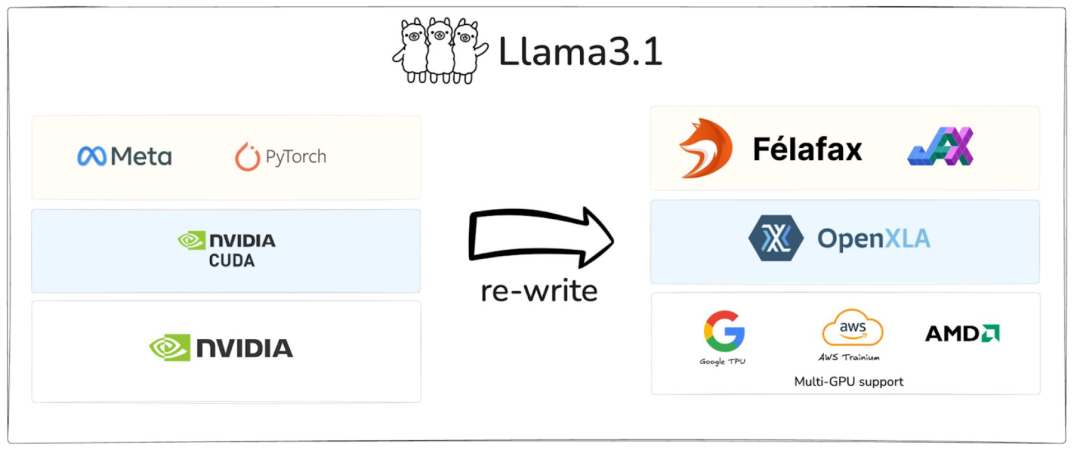
多硬件并行支持:JAX 采用 XLA(加速线性代数)编译器,将计算编译为硬件无关的中间表示(HLO),这意味着同样的 JAX 代码无需修改便可高效运行在不同硬件后端,包括 AMD GPU。 独立于底层硬件:XLA 编译器的优化策略是通用的,不针对某个特定的硬件平台。这使得任何支持 XLA 的硬件设备(如 CPU、GPU、TPU)都能受益于这些优化,获得更好的性能表现。 极高的适应性:从 NVIDIA 转移到 AMD(或其他硬件)时,JAX 只需做极少的代码改动。而相较之下,PyTorch 与英伟达的 CUDA 生态系统紧密耦合,迁移过程相对复杂。
docker pull rocm/jax:latest
# Pull the Docker Image:docker pull rocm/jax:latest # Start the Docker Container:docker run -it -w /workspace --device=/dev/kfd --device=/dev/dri --group-add video \--cap-add=SYS_PTRACE --security-opt seccomp=unconfined --shm-size 16G rocm/jax:latest# Verify the Installation: python3 -c 'import jax; print(jax.devices())'
python3 -c 'import jax; print (jax.devices ())'

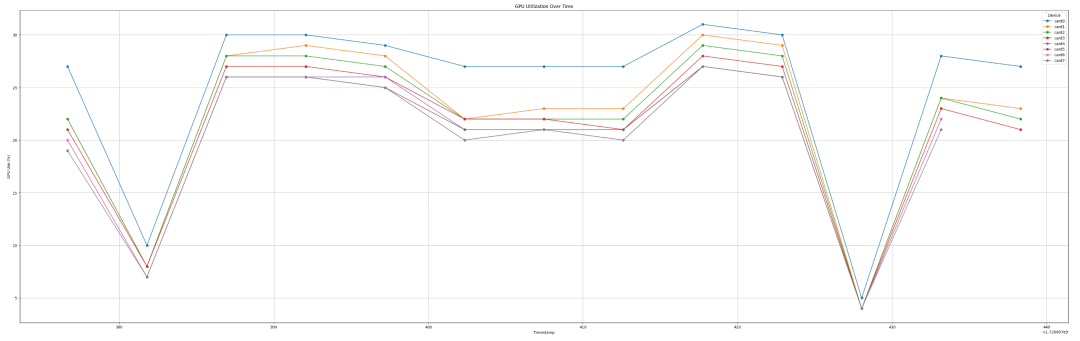
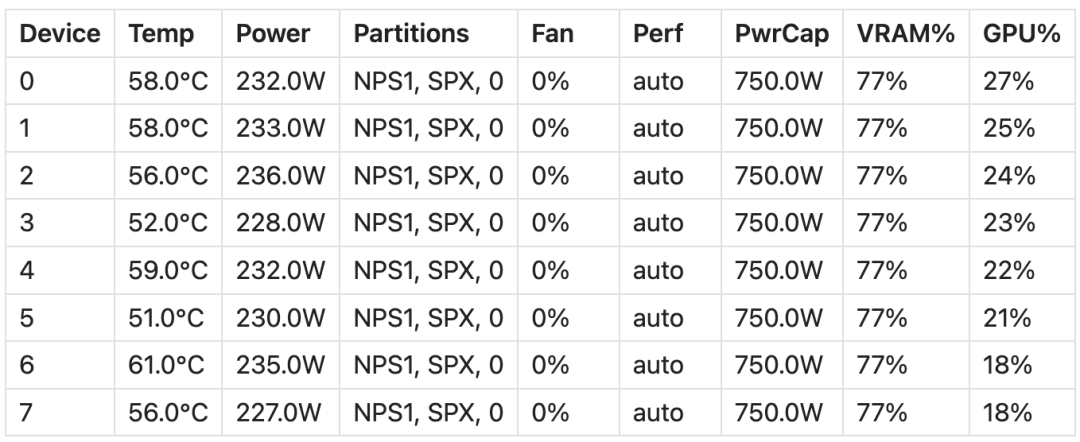
模型大小:LLaMA 模型的权重占用了约 800GB 的显存。 LoRA 权重 + 优化器状态:大约占用了 400GB 的显存。 显存总使用量:占总显存的 77%,约 1200GB。 限制:由于 405B 模型的规模过大,batch 大小和序列长度的空间有限,使用的 batch size 为 16,序列长度为 64。 JIT 编译:由于空间限制,无法运行 JIT 编译版本;它可能需要比急切模式稍多的空间。 训练速度:使用 JAX 急切模式,约为 35 tokens / 秒。 内存效率:稳定在约 70% 左右。 扩展性:在 8 张 GPU 上,使用 JAX 的扩展性接近线性。

方法演示:https://dub.sh/felafax-demo 代码仓库:https://github.com/felafax/felafax
DEVICES = jax.devices () DEVICE_COUNT = len (DEVICES) DEVICE_MESH = mesh_utils.create_device_mesh ((1, 8, 1)) MESH = Mesh (devices=DEVICE_MESH, axis_names=("dp", "fsdp", "mp"))jax.debug.visualize_array_sharding
参数如何分片:
Non-Replicated 参数:
def make_shard_and_gather_fns (partition_specs):def make_shard_fn (partition_spec):out_sharding = NamedSharding (mesh, partition_spec)def shard_fn (tensor):return jax.device_put (tensor, out_sharding).block_until_ready ()return shard_fnshard_fns = jax.tree_util.tree_map (make_shard_fn, partition_specs)return shard_fns# Create shard functions based on partitioning rulesshard_fns = make_shard_and_gather_fns (partitioning_rules)
train_batch = jax.device_put ( train_batch,NamedSharding (self.mesh, PS ("dp", "fsdp")))

将 LoRA 参数(lora_a 和 lora_b)与主模型参数分开。 使用 jax.lax.stop_gradient (kernel) 来防止对主模型权重的更新。 使用 lax.dot_general 进行快速、精确控制的矩阵运算。 LoRA 输出在添加到主输出之前会被缩放为 (self.lora_alpha/self.lora_rank)。
class LoRADense (nn.Module):features: intlora_rank: int = 8lora_alpha: float = 16.0@nn.compactdef __call__(self, inputs: Any) -> Any:# Original kernel parameter (frozen)kernel = self.param ('kernel', ...)y = lax.dot_general (inputs, jax.lax.stop_gradient (kernel), ...)# LoRA parameters (trainable)lora_a = self.variable ('lora_params', 'lora_a', ..., ...)lora_b = self.variable ('lora_params', 'lora_b', ..., ...)# Compute LoRA outputlora_output = lax.dot_general (inputs, lora_a.value, ...)lora_output = lax.dot_general (lora_output, lora_b.value, ...)# Combine original output with LoRA modificationsy += (self.lora_alpha/self.lora_rank) * lora_outputreturn y.astype (self.dtype)LoRA A matrices (lora_a)
分片规则:PS ("fsdp", "mp") 可视化结果:如下图所示,lora_a 参数被分片为 (8, 1),这意味着第一个轴在 8 个设备上进行分片("fsdp" 轴),而第二个轴未进行分片。

分片规则:PS ("mp", "fsdp") 可视化结果:如下图所示,lora_b 参数被分片为 (1, 8),这意味着第二个轴在 8 个设备上进行分片(fsdp 轴),而第一个轴未进行分片。

文中关于入门,Felafax的知识介绍,希望对你的学习有所帮助!若是受益匪浅,那就动动鼠标收藏这篇《微调大模型,AMD MI300X就够了!跟着这篇博客微调Llama 3.1 405B,效果媲美H100》文章吧,也可关注golang学习网公众号了解相关技术文章。
声明:本文转载于:机器之心 如有侵犯,请联系study_golang@163.com删除
相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
299 收藏
-
科技周边 · 人工智能 | 1天前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-
475 收藏
-
科技周边 · 人工智能 | 5天前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK292 收藏
-
379 收藏
-
394 收藏
-
101 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习