终于拿到内测!豆包-PixelDance真是字节视频生成大杀器
来源:机器之心
时间:2024-10-14 16:46:09 498浏览 收藏
学习科技周边要努力,但是不要急!今天的这篇文章《终于拿到内测!豆包-PixelDance真是字节视频生成大杀器》将会介绍到等等知识点,如果你想深入学习科技周边,可以关注我!我会持续更新相关文章的,希望对大家都能有所帮助!
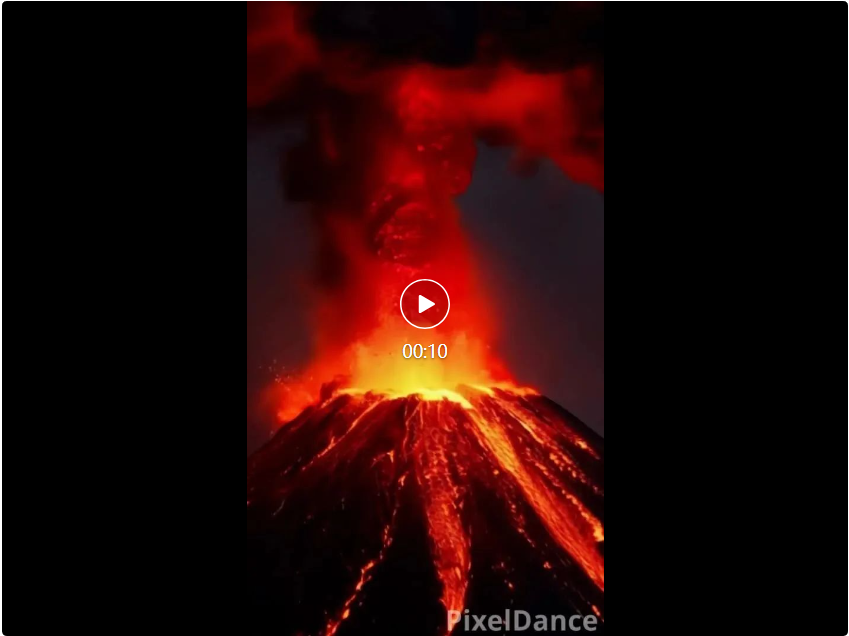
提示词:火山喷发,升起巨大蘑菇云,岩浆顺着山体往下流,镜头拉近,岩浆正在火山口跳动冒出。
这段 10 秒的视频是豆包视频生成模型基于以上提示词想象创造的。可以说这段视频的拟真度非常高,并且有着娴熟的运镜,足以放入任何影视作品中。
有着剪映、即梦等视频创作工具的字节跳动,正式宣告进军 AI 视频生成领域。那是在本周二,「2024 火山引擎 AI 创新巡展」来到了深圳。这一巡展上,字节跳动如火山爆发,一连发布了三个面向不同细分领域(视频生成、音乐和同声传译)的多模态大模型,同时给之前已有的通用语言模型、文生图模型、语音模型来了一波大升级。这些模型共同构建起了火山引擎的「豆包全模态大模型家族」。
家族新秀:豆包视频生成模型 PixelDance 和 Seaweed
惊艳、惊喜、目眩神迷……
在深圳站城市巡展上,火山引擎为豆包全模态大模型家族带来了两员新秀:PixelDance(像素跳动)和 Seaweed(海草)。
对于 PixelDance,记忆好的读者可能依然记得这个名词。是的,去年 11 月份,PixelDance 就已经凭借高动态视频生成能力在 AI 社区刷了一波存在感,感兴趣的读者可访问《视频生成新突破:PixelDance,轻松呈现复杂动作与炫酷特效》。
今年 5 月份,豆包视频生成模型的早期版本开始在即梦 AI 上应用,收获了不少好评。现在又过去了几个月时间,豆包视频生成模型已经完成迭代升级,能力更是大幅提升,本站也测试体验了其最新版本。
实测下来,PixelDance 和 Seaweed 这两个豆包视频生成模型的效果确实超乎了我们的想象。在此之前,大多数视频生成模型给出的结果都像是 PPT 一样:场景通常变化不大,而变化较大的场景又常会出现不一致问题。
豆包视频生成模型不仅能生成连贯一致的视频,而且还支持在生成的视频中采用不同运镜方式、多镜头切换、变焦等技法。此外,豆包视频生成模型还支持多种不同的风格以及各种常见设备的高宽比,适用于各种平台和场景。
提示词:一位老人正眺望远方的大海,镜头缓慢拉远,一艘白色的轮船从画面右侧驶来,天上飞着几只海鸥。
具体技术上,豆包视频生成模型基于 DiT(扩散 Transformer)架构。通过高效的 DiT 融合计算单元,让视频在大动态与运镜中自由切换,拥有变焦、环绕、平摇、缩放、目标跟随等多镜头语言能力。全新设计的扩散模型训练方法更是攻克了多镜头切换的一致性难题,在镜头切换时可同时保持主体、风格、氛围的一致性,这也是豆包视频生成模型独具特色的亮点。
前些天,豆包视频生成模型刚发布时,本站已经受邀进行了一波内测,那时候我们主要测试的模型是豆包-Seaweed,参阅本站报道《字节版 Sora 终于来了!一口气两款视频模型,带来的震撼不只一点点》中带「即梦 AI」水印的视频。报道发出后,有读者评论表示这比仍处于 PPT 阶段的 Sora 强多了。
这一次,我们又获得了另一个模型豆包-PixelDance 的内测机会。让我们用更多实例来验证一下豆包视频生成模型的各项能力,看它是否真像传说中那样,有着超越 Sora 的表现。
能力 1:支持更复杂的提示词和多动作多主体交互:想象一个充满活力的城市广场,人群熙攘,街头艺人表演,孩童嬉戏,情侣漫步。豆包视频生成模型能将这复杂场景栩栩如生地呈现出来,不再局限于单一动作或简单指令。它能精准捕捉多个主体之间微妙的互动,从眼神交流到肢体语言,都能完美诠释。这种高级理解能力可为创作者打开无限可能,让想象力在视频中自由翱翔。
提示词:80 年代风格,小男孩们在街头奔跑,汽车在街道上行驶。
能力 2:可在镜头切换时有效地保持镜头一致性:10 秒,足以让豆包视频生成模型讲述一个跌宕起伏的微电影。从温馨的家庭晚餐到激烈的街头追逐,再到感人的重逢场景,镜头切换行云流水,却始终保持主角特征、场景风格、情感氛围和叙事逻辑的完美统一。这种高超的一致性掌控,可为创作者的视频作品增添专业电影般的叙事魅力。
提示词:女生先是流下眼泪,然后开心地笑起来,并主动拥抱了男生。
能力 3:强大动态与酷炫运镜:生成的视频可同时存在主体的大动态与镜头的炫酷切换。支持变焦、环绕、平摇、缩放,目标跟随等超多镜头语言,实现对视角的灵活控制。无论是震撼的动作场面,还是细腻的情感表达,豆包视频生成模型都能以最佳视角呈现,带来超越想象的视觉盛宴。
提示词:特写,一个女生悲伤的面部,她缓缓转身,镜头拉远,看见了一个英俊的男子正注视着她。

提示词:油画风格,镜头拉远,一个穿着黑色西装的男人正走在这条路上。

心动了吗?你不仅能心动,而且不久之后就能真正开始体验豆包视频生成模型!据了解,豆包视频生成模型 PixelDance 和 Seaweed 已在火山引擎开启邀测,企业可通过火山引擎官网提交测试申请。
豆包视频生成模型邀测报名入口:https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?projectName=default&type=GenVideo
音频模态的破局者:豆包音乐及同声传译模型
除了视频生成,字节跳动也强势进军音频生成领域,发布了豆包音乐模型及同声传译模型。我们知道,声音的本质是空气中震荡的机械波,人类对此的物理理解已经相当深刻,但要让 AI 创作出动人心弦的和谐韵律,或在瞬息间跨越语言的鸿沟,却是两个截然不同的挑战。
火山引擎近日发布的豆包音乐模型和同声传译模型在各自的难点上都取得了质的突破,达到了可实际投入生产应用的水平。
豆包音乐模型:每个人都能有自己的歌
想象一下,仅凭一句话或一张图片,就能瞬间编织出动人心弦的旋律!
是的,不同于 Suno 等其它常见的音乐生成模型只能使用文本作为提示词或歌词信息,豆包的音乐生成模型还能使用图片作为灵感来源。这不仅能极大丰富用户的灵感来源,并且还能让用户根据视觉场景生成最适合场景的音乐。豆包音乐模型还支持音乐转换,只需 10 秒的语音或歌声录音,即可将其转换为不同风格的音乐。
不仅如此,这位 AI 作曲家还精通 10 多种音乐风格和情感色彩,让你可以随心所欲地探索民谣、流行、摇滚、国风、嘻哈等多种风格和情绪表现。
比如随手拍摄的小猫照片,它就能给你创作出一首非常好听的歌:
当然,你也可以让豆包音乐模型演唱你自己创作的歌词。我们以杜甫名篇《登高》做了测试:
豆包音乐模型现已向用户开放,企业和开发者可以通过火山方舟使用其 API,用户也可以直接通过豆包 App 和海绵音乐 App 创作音乐。
豆包同声传译模型:准确、实时、真正同声
相较于注重和谐韵律的音乐模型,同声传译模型的核心需求是准确和实时。
豆包同声传译模型采用了端到端的方式来实现同声传译。这不仅能避免分阶段处理(语音识别→机器翻译→语音合成)时错误的传递和积累问题,还能极大降低延迟。据了解,豆包同声传译模型的准确度在办公、法律、教育等场景中接近甚至超越人类同传水平,而延迟水平仅有半句话左右。
基础能力之上,豆包同声传译模型还具备音色克隆能力,可生成与说话人音色一致的外语声音,实现真正的「同声」传译。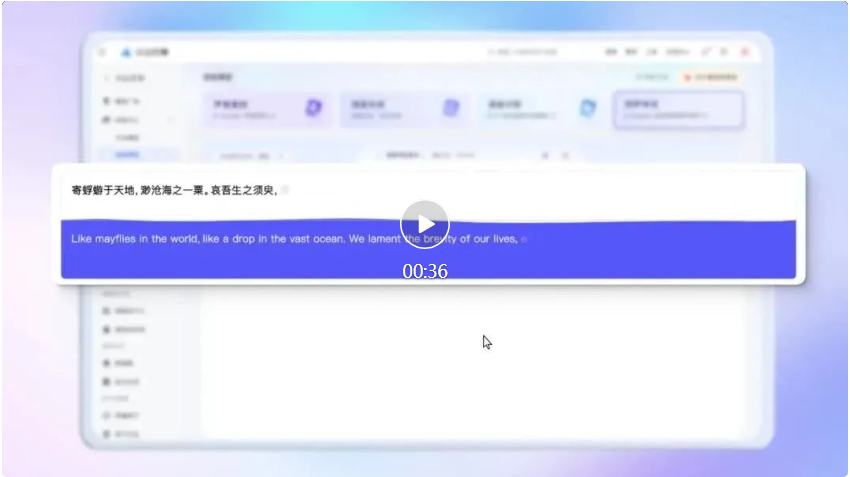
更多相关细节可参阅我们之前的报道《字节大模型同传智能体,一出手就是媲美人类的同声传译水平》。
已有模型大升级,效率大提升
除了新发布的视觉和音频模态模型,在火山引擎这一次还对已有的通用语言模型、文生图模型、语音模型来了一波大升级。
通用语言模型:增大上下文、提升综合能力
从 5 月到 9 月,豆包大模型的使用量实现了超过 10 倍的爆发式增长,顺着这股爆发式增长的势头,火山引擎宣布将旗舰级豆包大模型「豆包通用模型 Pro」迭代成了更强大的新版本,让模型的综合能力提升了 25%,在各个维度上都达到了国内领先水平,尤其是在数学和专业知识能力上。

这样的提升可让豆包更加轻松地应对更为复杂的工作和生活场景。
此外,豆包通用模型 Pro 的上下文窗口也从之前的 128k 倍增到了 256k,可一次性处理约 40 万汉字,相当于一口气读完《三体》的前两部。
文生图模型:推理效率和性能大幅提升
火山引擎也将豆包文生图模型迭代到了 2.0 版本。其采用了更高效的 DiT 架构。模型的推理效率和性能都获得了显著提升。除了继承之前已有的高美感等优势,这一次升级,火山引擎着重优化了文生图模型的物理感知能力,可让模型感知多主体、数量、大小、高矮、胖瘦和运动等复杂属性并实现对应的生成。
文生图模型 2.0 的想象力也获得了提升,可更好地呈现虚构和超现实画面。另外,文生图模型 2.0 还能以极高的美感呈现中国古代的各类绘画风格。如下例子所示,生成人物的头发、手指和妆造都堪称完美。

提示词:古装美人赏月图,长发飘飘,烛火荧荧
同时,文生图模型的出图速度也获得了提升 —— 最快可做到 3 秒出图。
文生图模型 2.0 已经上线即梦,用户可以即刻开始尝鲜了。
语音模型:超强混音,音色自由组合
火山引擎也为自家的语音合成模型带来了一轮升级,其中最具看点的新功能是通过混音来组合形成不同的音色,并由此打破了音色数量的限制。并且,这个功能不仅允许用户自由组合火山引擎提供的声音,还能将自己的声音复刻为混音音源。
这些通过混音生成的声音不仅在音色自然度上有了质的飞跃,其连贯性、音质和韵律也达到了与真人几乎无异的水平,难以分辨虚实,令人惊叹。
比如我们可以通过混合猴哥和港剧女声的音色比例来获得妙趣横生的新音色。
效率提升和成本降低:让大模型真正可用的基础
大模型服务要真正有用并能被用户使用,只是能力强大还不够,还需要强大的服务器提供硬件支持,同时还需要控制使用成本,让用户可以接受。
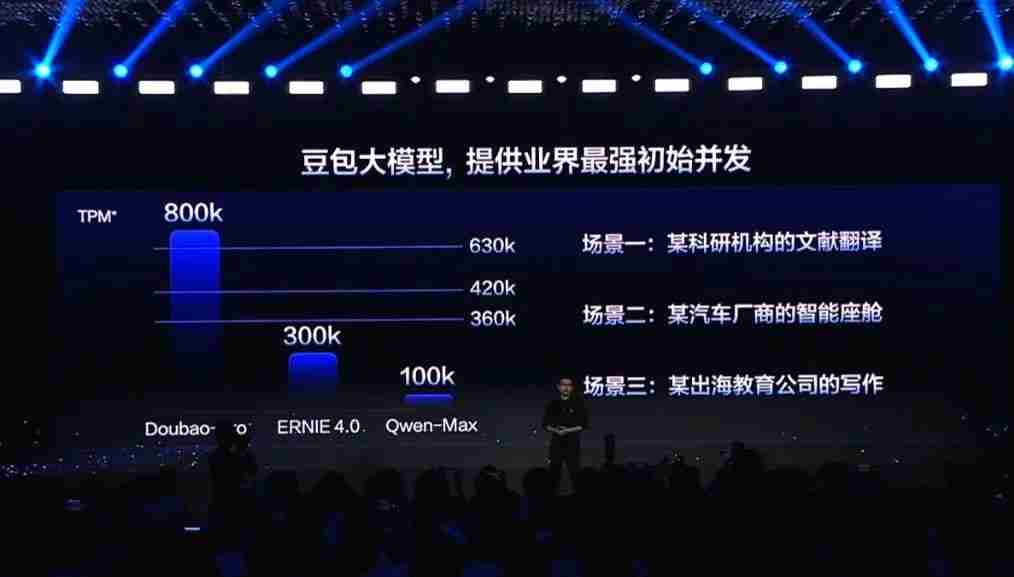
效率方面,火山引擎总裁谭待宣布,豆包 Pro 默认的初始 TPM(每分钟 token 数)为 800k,高于业界其它模型,并且还可根据企业具体需求进一步扩容。实际上,800k 的 TPM 足称业界最强,可以满足很多企业级的应用场景。
而在成本方面,火山引擎也做了很多创新和探索,并成功在今年 5 月将每千 token 的使用成本降到了 1 厘(0.001 元)以下,使字节跳动成为国内第一家能做到如此低成本的公司。可以说,token 的价格已经不再是阻碍 AI 应用创新的阻力。
另外,火山引擎还开发了全新的上下文缓存技术。这能让用户无需重复对话,就能保留上下文。由此可以降低多轮对话的延迟,改善用户体验。同时还能有效降低企业使用大模型的成本。
结语
在这场令人目眩神迷的 AI 盛宴中,火山引擎展示了其在视频、音频、文本等不同模态上的卓越能力。同时其也不断重申了对安全和隐私的重视。
火山引擎的全模态大模型战略正在逐步展现其全力以赴 AI 的决心。从文本到图像,从视频到音频,再到跨模态的融合应用,火山引擎正在构建一个全方位、多维度的 AI 生态系统,甚至能让用户「一个人就能成为想象的指挥家」,完成从创意加工到视频制作的全流程。这个生态系统不仅能为开发者和企业用户提供丰富的工具和接口,更为未来的智能应用描绘了一幅令人期待的前景。
以上就是《终于拿到内测!豆包-PixelDance真是字节视频生成大杀器》的详细内容,更多关于火山引擎,产业,豆包大模型的资料请关注golang学习网公众号!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
468 收藏
-
科技周边 · 人工智能 | 1天前 | 人工智能 · ai agent · AI应用 · 工具调用 · 权限边界 · 审计链路 · 人工智能 权限控制 AI Agent 工具调用 审批链路 审计回放 上线指标343 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计427 收藏
-
154 收藏
-
309 收藏
-
234 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream448 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 3星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习