缓存替换策略及应用(以Redis、InnoDB为例)
来源:脚本之家
时间:2022-12-31 10:47:42 417浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《缓存替换策略及应用(以Redis、InnoDB为例)》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
1 概述
在操作系统的页面管理中,内存会维护一部分数据以备进程使用,但是由于内存的大小必然是远远小于硬盘的,当某些进程访问到内存中没有的数据时,必然需要从硬盘中读进内存,所以迫于内存容量的压力下迫使操作系统将一些页换出,或者说踢出,而决定将哪些(个)页面踢出就是内存替换策略。
我们考虑内存中的页实际上是整个系统页的子集,所以内存可以当成系统中虚拟内存的缓存(Cache),所以页面置换算法就是缓存替换的方法。
一般意义下,选取页面置换算法即选取一个缓存命中率更高的或者说缺页率更低的算法,但实际上有时候随着算法缓存命中率提升,算法复杂度也在上升,所以带来的系统开销也是在上升的,所以我们不得不在系统开销和算法复杂程度中间取一个折中,比如Redis中采取的类LRU缓存置换策略实际上在大多数情况下比起理想LRU缓存命中率是低的,但理想LRU实现起来会给系统带来更大的开销,得不偿失。
2 页面置换算法
下面介绍最常见的五种置换策略,其中最佳置换算法是理论上很难实现的,其余的FIFO、LRU、LFU,其算法复杂度、开销是递增的,但是缺页率也是越来越低,或者说越来越接近最佳置换策略的。最后一种时钟置换算法是一种近似的LRU算法,是保证了低系统开销下同时较低的缺页率的一种折中选择。
2.1 最佳(Optimal)置换算法
最佳置换算法,其所选择的被淘汰的页面将是以后永不使用的,或是在最长(未来)时间内不再被访问的页面。听名字定义很显然页面未来的使用情况它就不可预测,所以最佳置换算法只是理论上的最优方法,实际上在大多数情况下并没法完成,所以更多的是作为衡量其他置换算法的标准。
2.2 先进先出(FIFO)置换算法
许多早期的操作系统为了保证算法的简单,避免高复杂度的算法,尝试了最简单的置换策略,即FIFO置换策略,顾名思义就是维护一个页的队列,最先进入内存的页最先被淘汰,这样的算法复杂度低,系统开销也极低,但是显然命中率会下降。
另外考虑一种情况,增大缓存时,一般意义下缓存的命中率必然会上升,但是FIFO算法则在有的时候则会下降,这种现象叫做Belady现象。原因是FIFO算法没有考虑到程序的局部性原则,踢出的页面很可能是程序经常性访问的页面。
Belady现象的实例分析可以参考belady
2.3 最近最少使用(Least Recently Used,LRU)置换算法
为了解决Belady现象,同时也是基于程序的局部性原则(Locality of reference,指的是在计算机科学计算机科学领域中应用程序在访问内存的时候,倾向于访问内存中较为靠近的值。)就有了LRU置换策略,从程序代码的角度理解局部性原则就是,程序一般倾向于频繁的访问某些代码(比如循环)或者数据结构(比如循环访问的数组),因此我们应该使用历史访问数据来决定,哪些页应该被踢出,哪些页不应该被踢出,具体的就是,最近没有被访问的页优先被踢出。这个其实不难理解,通过一个访问顺序的队列,每次访问某个页,就将此页移到队首,当内存(缓存)满了时优先从队尾踢出相应的页。(下面给出一个例子,表来自操作系统导论第22章)
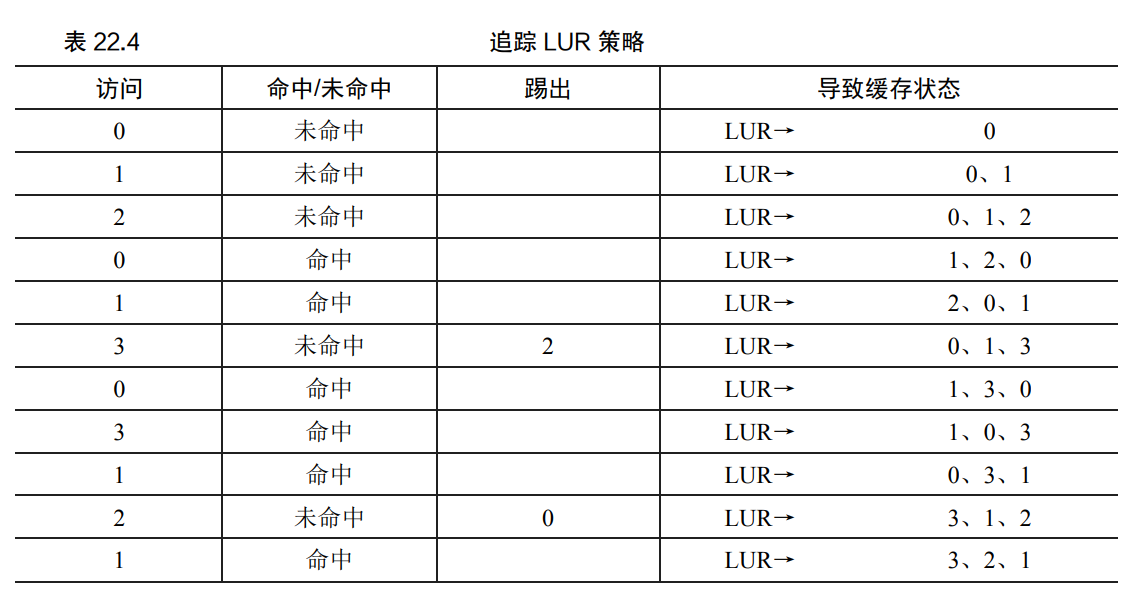
但是显然的是,LRU会带来更大的系统开销,因为我们需要频繁的将访问过的页置于访问序列的首部,这就需要对访问队列的内容进行频繁的增删,而FIFO只需要简单排列即可。
2.4 最不经常使用(Least Frequently Used,LFU)置换算法
如果说LRU是通过所有页面的最近使用情况或者说访问时间来看,那么LFU即通过访问频率来决定哪些页面需要被踢出,根据程序的局部性原则,显然LFU会带来更高的缓存命中率,但是考虑到需要记录频率并且频繁的调整队列,实际上带来的系统开销会比LRU更大。
下图描述了一个LFU的执行过程,大写字母为相应的页,圆圈中的数字代表访问频率,访问频率最低的在队列的最后,当需要踢出时,优先踢出队列末尾的页。
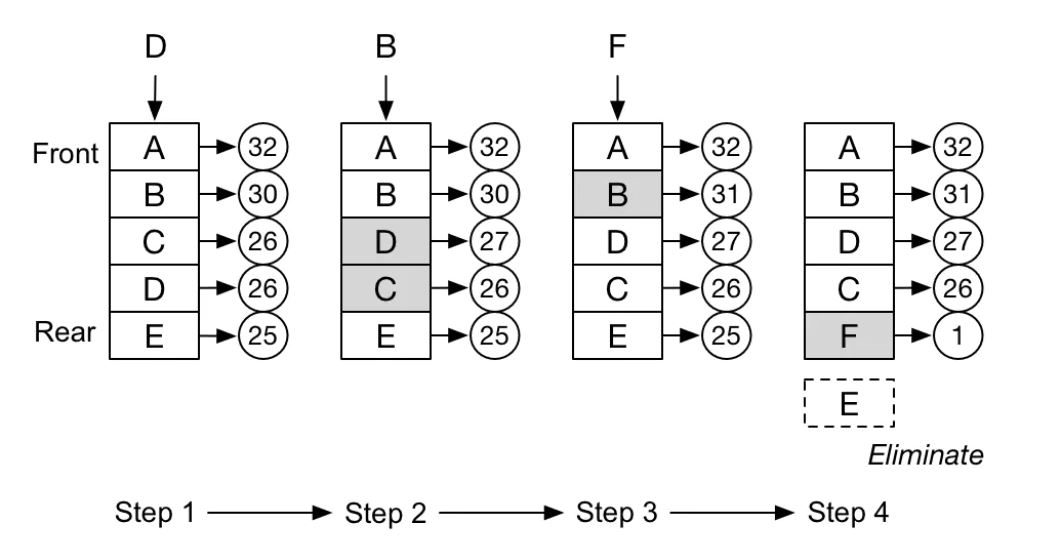
2.5 时钟(CLOCK)置换算法
上文谈到了LRU和LFU会带来更高的缓存命中率,但是计算开销显然会更大,给系统带来更高的时间开销,而一些类LRU算法就出现了,比如时钟算法。
系统中的所有页都放在一个循环列表中。时钟指针(clock hand)开始时指向某个特定的页(哪个页不重要)。当必须进行页替换时,操作系统检查当前指向的页P的使用位是1还是0。如果是1,则意味着页面P最近被使用, 因此不适合被替换。然后,P的使用位设置为0,时钟指针递增到下一页(P+1)。该算法一直持续到找到一个使用位为 0 的页,使用位为 0 意味着这个页最近没有被使用过(在最坏的情况下,所有的页都已经被使用了,那么就将所有页的使用位都设置为 0)。

3 朴素LRU的实现
以leetcode146. LRU 缓存机制为例,最直观朴素的LRU缓存机制可以使用哈希表以及双向链表实现,当然Java的集合LinkedHashMap即实现了一个哈希表+链表的组合,可以直接调用实现。
但为了更形象的理解LRU的机制,采用HashMap以及手写一个双向链表来实现。具体的结构如下图所示
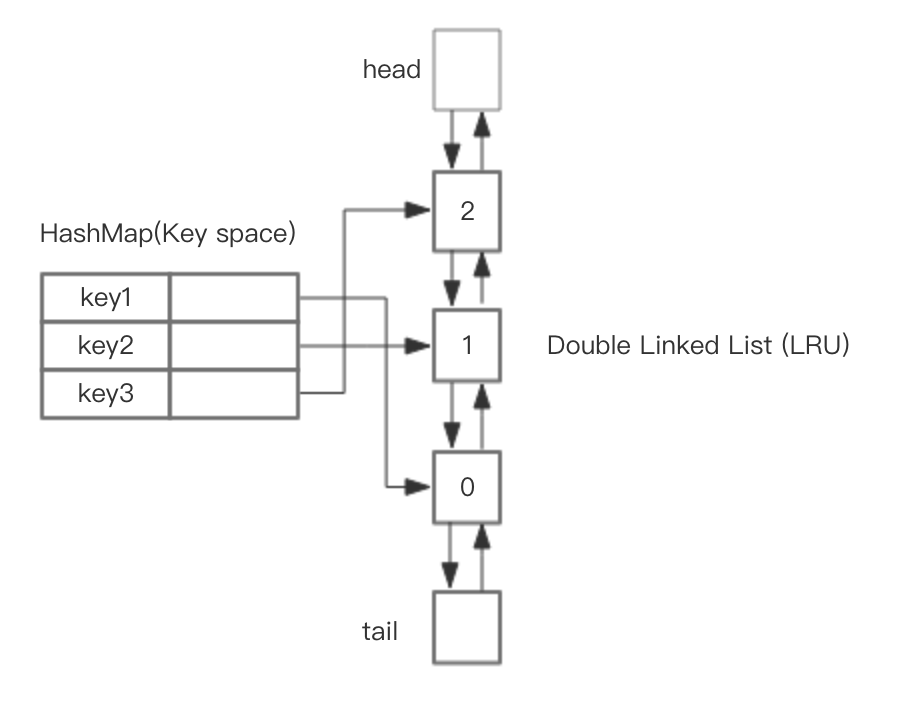
维护一个大小为缓存容量的map,key值为缓存数据的key,value存储指向相应节点的引用,数据链表使用双向链表便于增删,当访问到某条数据时,通过map以O(1)复杂度定位到数据的应用,然后
- 删除访问节点
- 添加访问节点到队首
当节点数量>缓存容量时,删除队尾元素,同时移除map中的数据,具体实现如下。
public class LRUCache {
class DLinkedNode {
int key, value;
DLinkedNode pre;
DLinkedNode next;
public DLinkedNode(){}
public DLinkedNode(int key, int value){this.key = key; this.value = value;}
}
private Map cache = new HashMap();
private int size;
private int cal;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
size = 0;
cal = capacity;
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.pre = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
DLinkedNode newNode = new DLinkedNode(key, value);
cache.put(key, newNode);
size++;
addToHead(newNode);
if (size > cal) {
DLinkedNode tail = removeTail();
cache.remove(tail.key);
size--;
}
} else {
node.value = value;
moveToHead(node);
}
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private void removeNode(DLinkedNode node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
private void addToHead(DLinkedNode node) {
node.pre = head;
node.next = head.next;
head.next.pre = node;
head.next = node;
}
private DLinkedNode removeTail() {
DLinkedNode realTail = tail.pre;
removeNode(realTail);
return realTail;
}
}
4 LRU的实际应用
4.1 以Redis为例
上面谈到要实现一个朴素的LRU算法,需要维护一个双向链表,存储前驱、后继指针,必然会在寸金寸土的缓存(内存)中带来不必要的开销。上述提到的时钟算法就是一种类LRU算法,用更少的系统开销带来了接近朴素LRU的命中率。而事实上,Redis中采取的LRU算法也是一种类LRU算法,它也带来了时钟算法类似的效果。具体的是Redis通过随机选取几个key值,淘汰时间戳最靠前的key,涉及到LRU的淘汰策略maxmemory_policy(这个字段可以选择不同的缓存淘汰策略,Redis一种提供了8种,本文只分析其中与LRU有关的)的赋值两种:
allkeys-lru: 对所有的键都采取LRU淘汰volatile-lru: 仅对设置了过期时间的键采取LRU淘汰
可以根据实际情况选择上述两种LRU淘汰策略,在一般情况下,程序都存在局部性,或者说幂次分布(二八法则),即少数数据比其他大多数数据访问的更多,所以通常使用allkeys-lru策略,而当有需求需要长期保留一部分数据在内存中时选取volatile-lru即只规定部分需要淘汰的数据。
下面看一下具体是如何设置的,Redis整体上是一个大的字典,key是一个string,而value都会保存为一个robj(Redis Object),对于robj的定义如下
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
其中LRU_BITS即Redis为每个键值对配备的一个记录时间戳的bit位,Redis的LFU替换策略中也使用这个空间,创建对象时会写入到lru_clock这个字段中,访问对象时会对其进行更新,具体的空间的大小被定义为一个常量
#define REDIS_LRU_BITS 24
大小为24,即使用一个额外的24bit的空间记录相对时间戳(即对unix time取模之后的结果),默认的时间戳分辨率是1秒,在这种情况下,24bits的空间如果溢出的话需要194天,而作为频繁更新的缓存而言,这个空间够用了。
上面提到了Redis会随机采样,比较其访问时间哪个更靠前,当需要替换时优先踢出采样结果最靠前的键值对,具体的采样个数在最开始是选取3个key,但是效果并不好,后来增加到N个key,但是默认是5个,即默认随机选取5个key,最先淘汰掉这5个中距离上次访问时间最久的,Redis3.0中又改善了算法的性能,即提供了一个采样池(pool),候选采样池默认大小为16,能够填充16个key,更新时从Redis键空间随机选择N个key,分别计算它们的空闲时间idle,key只会在pool不满或者空闲时间大于pool里最小的时,才会进入pool,然后从pool中选择空闲时间最大的key淘汰掉。
具体的这个候选集合结构体如下
struct evictionPoolEntry {
unsigned long long idle; // 用于淘汰排序,在不同算法中意义不同优先淘汰值大的,单位是ms
sds key; // 键的名字
// ...
};
所以关键在pool中的idle字段的计算,实际上只需要使用当前的时间戳减去lru_clock即可,但是所记录的时间戳都是取模之后的结果,所以还需要比较当前计算出来的时间戳是否大于lru_clock,如果不是,则需要将当前
时间戳+194天(模数)再减去lru_clock。具体的计算过程如下
// 以秒为精度计算对象距离上一次访问的间隔时间,然后转化成毫秒返回
unsigned long long estimateObjectIdleTime(robj *o) {
unsigned long long lruclock = LRU_CLOCK();
if (lruclock >= o->lru) {
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
} else {
return (lruclock + (LRU_CLOCK_MAX - o->lru)) *
LRU_CLOCK_RESOLUTION;
}
}
另外Redis官方文档里有对于候选数为5、10在redis2.8无侯选池,以及3.0加侯选池的对比。

四张图依次是,理论LRU的使用情况、有pool采样数为10的候选情况、无pool采样数为5的情况、有pool采样数为10的情况。其中
- 绿色部分是新添加的key
- 灰色部分是最近使用的key浅
- 灰色部分是替换的key
可以看出采取Redis3.0的采取维护一个候选淘汰池的方法已经能够接近全局比较情况下也即朴素LRU的结果。
详细的分析可以参考https://redis.io/topics/lru-cache
4.2 以MySQL的InnoDB引擎为例
此处InnoDB的缓存概念不做过多赘述,只简单介绍其中LRU的应用,InnoDB会把cpu频繁使用的数据存储在主存的缓冲池(Buffer Pool)中,鉴于MySQL在使用过程中存在着经常性的全表扫描,所以如果使用朴素LRU必然会频繁的大面积替换,造成极低的缓存命中率。
所以InnoDB采取了一种冷热分离的思路,即将整个缓冲池分为冷区和热区或者说年轻区(New Sublist)和老区(Old Sublist)
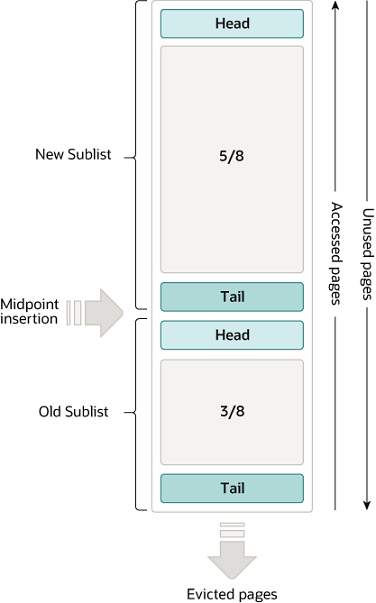
默认情况下距离链表尾3/8以上的位置称为新子列表(热点区域),以下的位置称为旧子列表(冷区域),某个页面初次加载到缓冲池时,放在old区域的头部。在对某个处于old区域的缓冲页进行第一次访问时,就在它对应的控制块中记录下这个访问时间,如果后续的访问时间和第一次访问的时间在某个时间间隔内(默认为1000ms),那么该页面就不会从老的区域移动到年轻区域的头部,否则将他移动到年轻区域的头部。
而当缓冲池满时需要淘汰数据就从old区域的尾部进行淘汰,这样数据起码需要两次(一次为加载到内存,第二次为大于间隔时间的读取)合理的操作才能移动到年轻区域,有效的预防了全表扫描带来的命中率降低问题。
更加详细具体的描述可以参见MySQL官方文档对InnoDB buffer poll的解释。
本篇关于《缓存替换策略及应用(以Redis、InnoDB为例)》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于数据库的相关知识,请关注golang学习网公众号!
-
487 收藏
-
120 收藏
-
257 收藏
-
224 收藏
-
162 收藏
-
数据库 · Redis | 1小时前 | Redis · go · Pipeline · 批处理 · 重试 · 幂等性 · 重试 go-redis 幂等键 批量写入 Redis Pipeline 逐条结果391 收藏
-
154 收藏
-
386 收藏
-
127 收藏
-
422 收藏
-
326 收藏
-
494 收藏
-
数据库 · Redis | 3天前 | Redis · 缓存 · 限流 · Redis 8.8 · INCREX · Redis 8.8 INCREX Redis窗口限流 Redis计数器 ENX UBOUND123 收藏
-
数据库 · Redis | 5天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT259 收藏
-
183 收藏
-
413 收藏
-
数据库 · Redis | 1星期前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计364 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 着急的小松鼠
- 这篇文章出现的刚刚好,很详细,很棒,收藏了,关注博主了!希望博主能多写数据库相关的文章。
- 2023-02-10 11:51:45
-
- 伶俐的香菇
- 这篇文章内容太及时了,很详细,感谢大佬分享,已加入收藏夹了,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-01-19 13:10:18
-
- 虚心的手套
- 这篇技术文章真是及时雨啊,太细致了,感谢大佬分享,收藏了,关注博主了!希望博主能多写数据库相关的文章。
- 2023-01-18 18:38:20
-
- 仁爱的猫咪
- 很棒,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,看完之后很有帮助,总算是懂了,感谢作者大大分享文章内容!
- 2023-01-15 13:32:50
-
- 内向的斑马
- 细节满满,已加入收藏夹了,感谢楼主的这篇技术文章,我会继续支持!
- 2023-01-02 14:07:36