MIT韩松团队长上下文LLM推理高效框架DuoAttention:单GPU实现330万Token上下文推理
来源:机器之心
时间:2024-10-27 09:51:42 106浏览 收藏
对于一个科技周边开发者来说,牢固扎实的基础是十分重要的,golang学习网就来带大家一点点的掌握基础知识点。今天本篇文章带大家了解《MIT韩松团队长上下文LLM推理高效框架DuoAttention:单GPU实现330万Token上下文推理》,主要介绍了,希望对大家的知识积累有所帮助,快点收藏起来吧,否则需要时就找不到了!

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文第一作者肖光烜是麻省理工学院电子工程与计算机科学系(MIT EECS)的三年级博士生,师从韩松教授,研究方向为深度学习加速,尤其是大型语言模型(LLM)的加速算法设计。他在清华大学计算机科学与技术系获得本科学位。他的研究工作广受关注,GitHub上的项目累计获得超过9000颗星,并对业界产生了重要影响。他的主要贡献包括SmoothQuant和StreamingLLM,这些技术和理念已被广泛应用,集成到NVIDIA TensorRT-LLM、HuggingFace及Intel Neural Compressor等平台中。本文的指导老师为韩松教授(https://songhan.mit.edu/)

论文链接:https://arxiv.org/abs/2410.10819 项目主页及代码:https://github.com/mit-han-lab/duo-attention

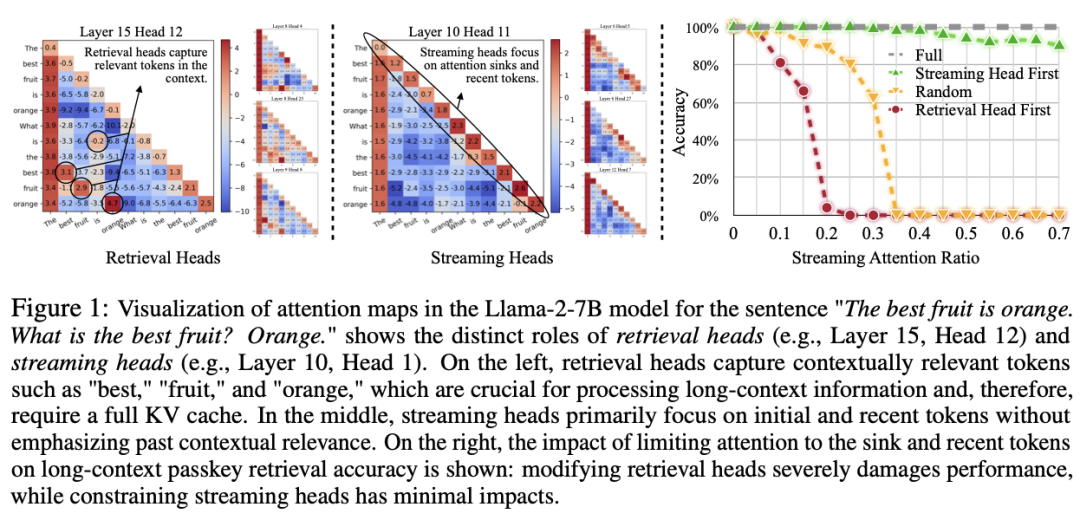
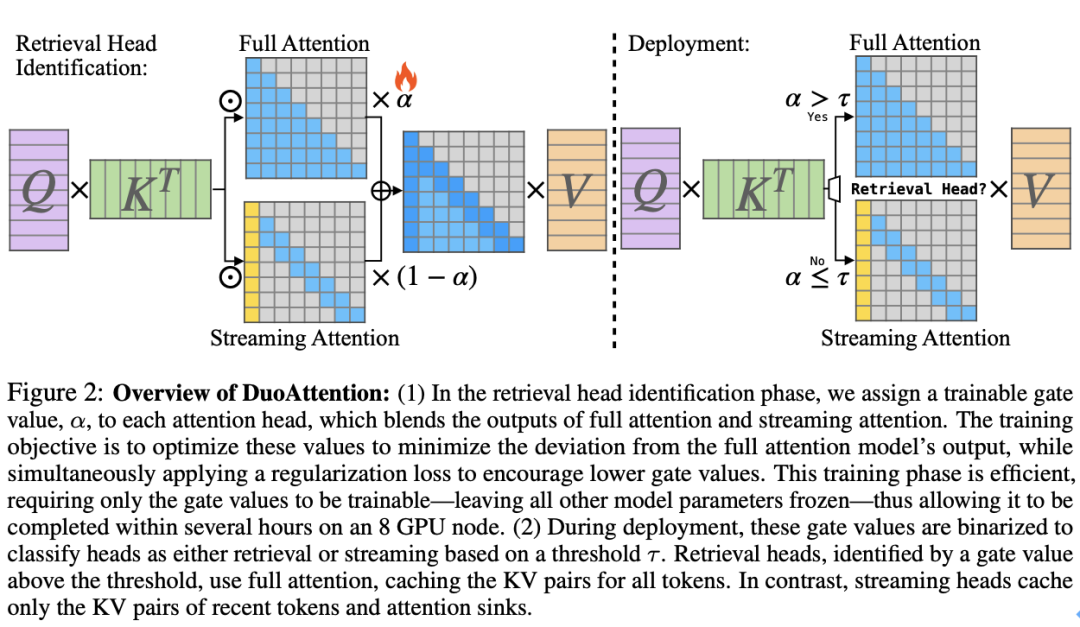
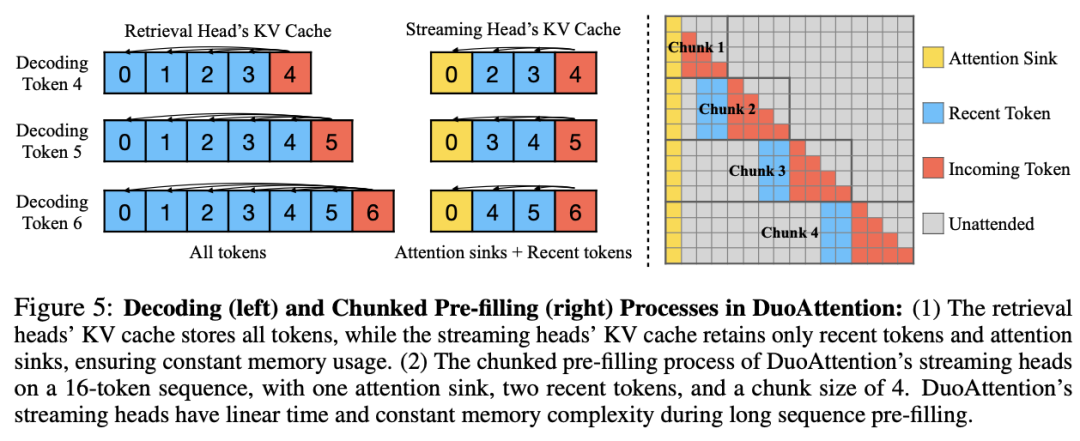
检索头的 KV 缓存优化:DuoAttention 为检索头保留完整的 KV 缓存,这些头对长距离依赖信息的捕捉至关重要。如果对这些头的 KV 缓存进行剪裁,将导致模型性能严重下降。因此,检索头需要对上下文中的所有 token 保持 “全注意力(Full Attention)”。 流式头的轻量化 KV 缓存:流式头则主要关注最近的 token 和注意力汇点。这意味着它们只需要一个固定长度的 KV 缓存(Constant-Length KV Cache),从而减少了 KV 缓存对内存的需求。通过这种方式,DuoAttention 能够以较低的计算和内存代价处理长序列,而不会影响模型的推理能力。
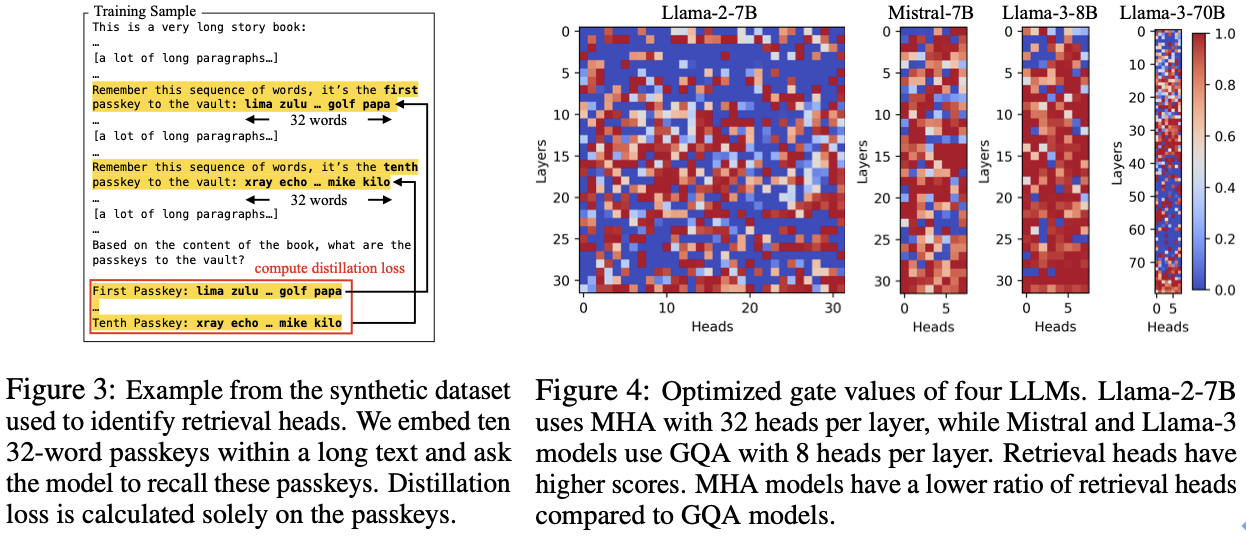
检索头的自动识别:为了准确区分哪些头是检索头,DuoAttention 提出了一种轻量化的优化算法,使用合成数据集来训练模型自动识别重要的检索头。这种优化策略通过密码召回任务(Passkey Retrieval),确定哪些注意力头在保留或丢弃 KV 缓存后对模型输出有显著影响。最终,DuoAttention 在推理时根据这一识别结果,为检索头和流式头分别分配不同的 KV 缓存策略。
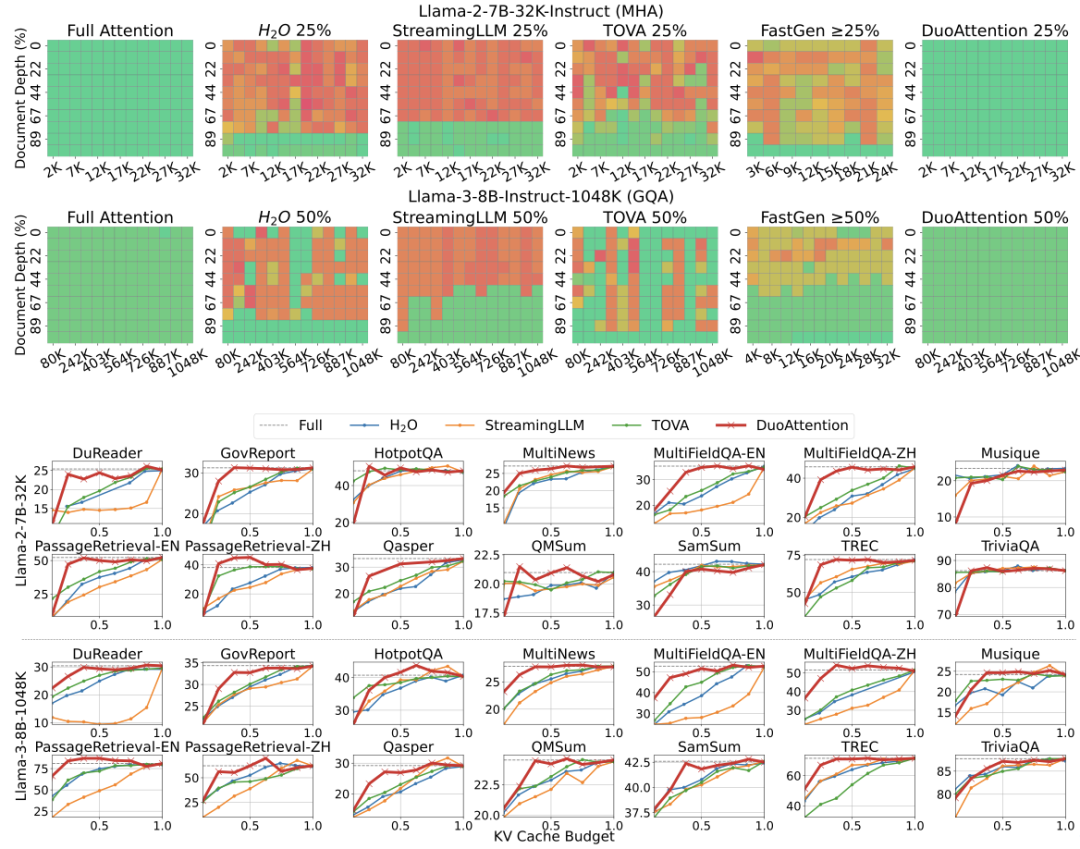
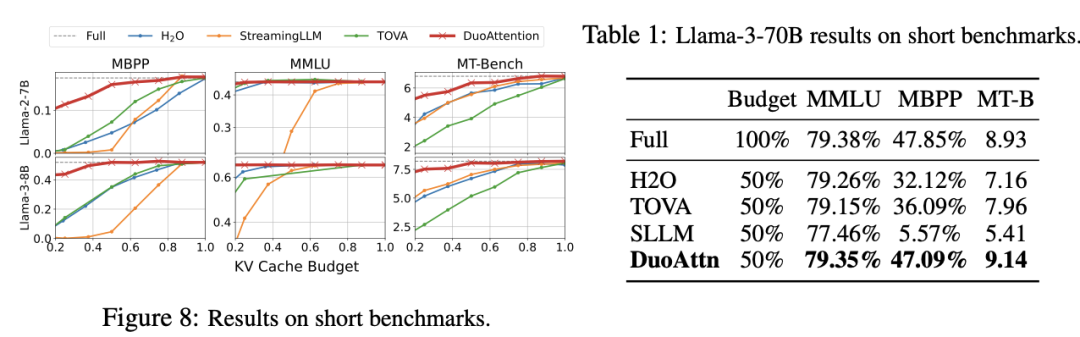
内存消耗显著降低:DuoAttention 在多头注意力模型(Multi-Head Attention,MHA)上将内存消耗减少了 2.55 倍,在分组查询注意力模型(Grouped-Query Attention,GQA)上减少了 1.67 倍。这是由于对流式头采用了轻量化的 KV 缓存策略,使得即使在处理百万级别的上下文时,模型的内存占用依然保持在较低水平。 解码(Decoding)和预填充(Pre-Filling)速度提升:DuoAttention 的解码速度在 MHA 模型中提升了 2.18 倍,在 GQA 模型中提升了 1.50 倍。在预填充方面,MHA 和 GQA 模型的速度分别加快了 1.73 倍和 1.63 倍,有效减少了长上下文处理中的预填充时间。
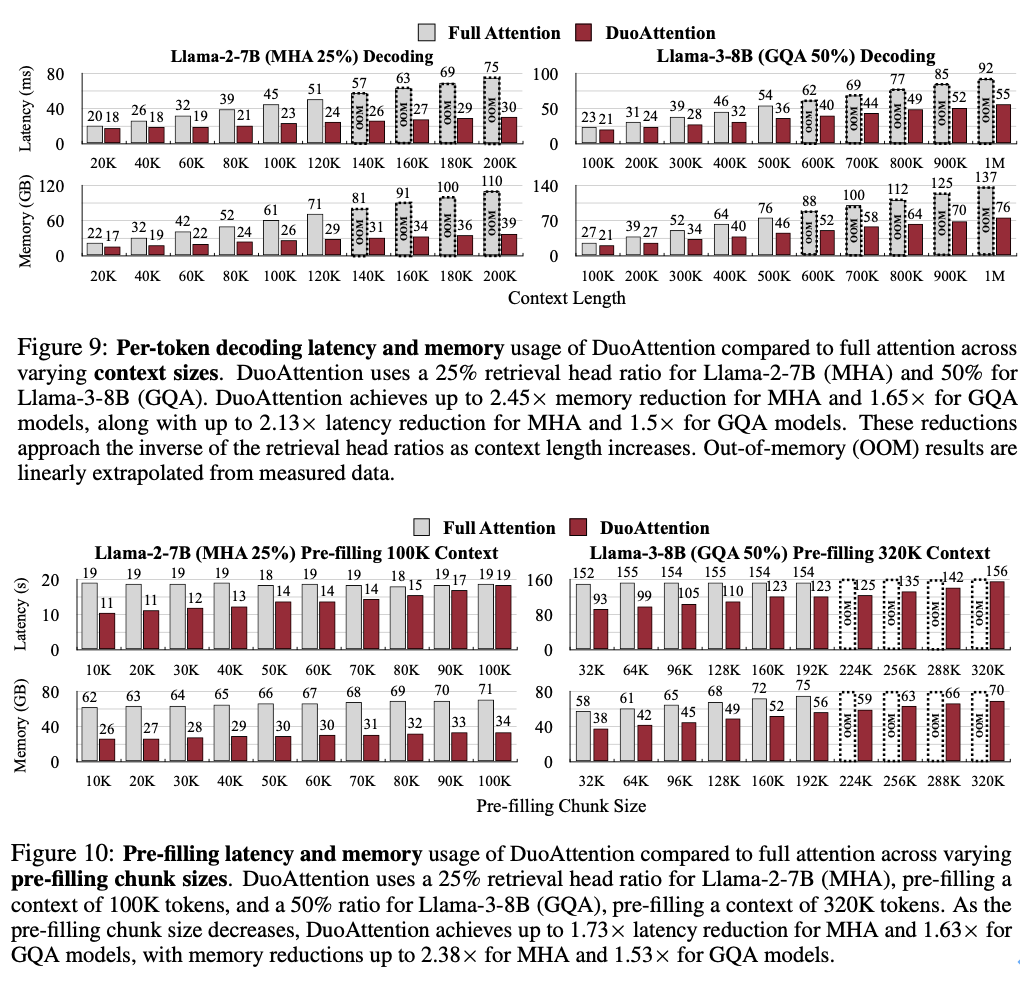
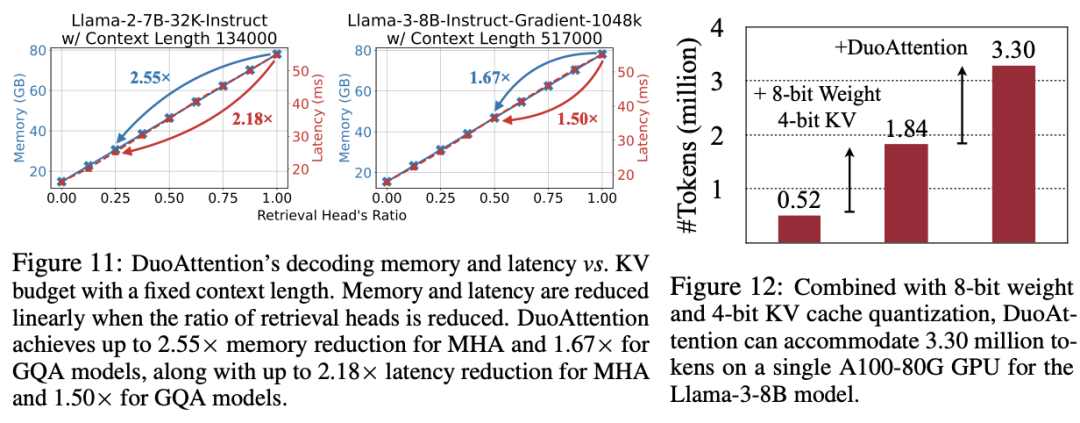
百万级 token 处理能力:结合 4 比特量化(Quantization)技术, DuoAttention 实现 Llama-3-8B 在单个 A100 GPU 上处理高达 330 万 token 的上下文,这一结果是标准全注意力机制的 6.4 倍。
多轮对话系统(Multi-Turn Dialogues):DuoAttention 使对话模型能够高效处理长时间对话记录,从而更好地理解用户上下文,提升交互体验。 长文档处理与摘要生成:在文档分析、法律文本处理、书籍摘要等任务中,DuoAttention 极大减少内存占用,同时保持高精度,使长文档处理更加可行。 视觉与视频理解:在涉及大量帧的上下文信息处理的视觉和视频任务中,DuoAttention 为视觉语言模型(Visual Language Models,VLMs)提供了高效推理方案,显著提升了处理速度。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于科技周边的相关知识,也可关注golang学习网公众号。
声明:本文转载于:机器之心 如有侵犯,请联系study_golang@163.com删除
相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
科技周边 · 人工智能 | 19小时前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream448 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-
475 收藏
-
科技周边 · 人工智能 | 2星期前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK292 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习