新视角设计下一代时序基础模型,Salesforce推出Moirai-MoE
来源:机器之心
时间:2024-11-04 10:27:41 325浏览 收藏
科技周边不知道大家是否熟悉?今天我将给大家介绍《新视角设计下一代时序基础模型,Salesforce推出Moirai-MoE》,这篇文章主要会讲到等等知识点,如果你在看完本篇文章后,有更好的建议或者发现哪里有问题,希望大家都能积极评论指出,谢谢!希望我们能一起加油进步!

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文由 Salesforce、新加坡国立大学、香港科技大学(广州)共同完成。其中,第一作者柳旭是 Salesforce 亚洲研究院实习生、新加坡国立大学计算机学院四年级博士生。通讯作者刘成昊是 Salesforce 亚洲研究院高级科学家。该工作的短文版本已被 NeurIPS 2024 Workshop on Time Series in the Age of Large Models 接收。
时间序列预测是人类理解物理世界变化的重要一环。自去年底以来,时序预测领域正在经历重大转型,从传统的「单一数据集训练单一模型」的模式逐步转向「通用预测基础模型」。目前虽然有不少基础模型已经提出,但如何有效地在高度多样化的时序数据上训练基础模型仍是一个开放问题。
近期,来自 Salesforce、新加坡国立大学、香港科技大学(广州)的研究者以模型专家化这一全新视角作为抓手,设计并提出了下一代时序预测基础模型 Moirai-MoE。该模型将模型专业化设计在 token 这一细粒度运行,并且以完全自动的数据驱动模式对其赋能。模型性能方面,不同于仅在少量数据集上进行评估的已有时序基础模型,Moirai-MoE 在一共 39 个数据集上进行了广泛评估,充分验证了其优越性。

论文标题:Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts
论文地址:https://arxiv.org/abs/2410.10469
代码仓库:https://github.com/SalesforceAIResearch/uni2ts
研究动机
训练通用基础模型的一大挑战在于适应时间序列数据的高度异质性,这种时序数据的独特特性凸显了设计专业化模块的必要性。现有的解决方案主要分为两种。第一种是通过基于语言的提示来识别数据源,从而实现非常粗粒度的数据集级别模型专业化。第二种方案利用了时序数据的频率这一元特征实现了更细粒度的专业化:该方法为特定频率设计单独的输入 / 输出投影层,从而实现特定频率的模型专业化。
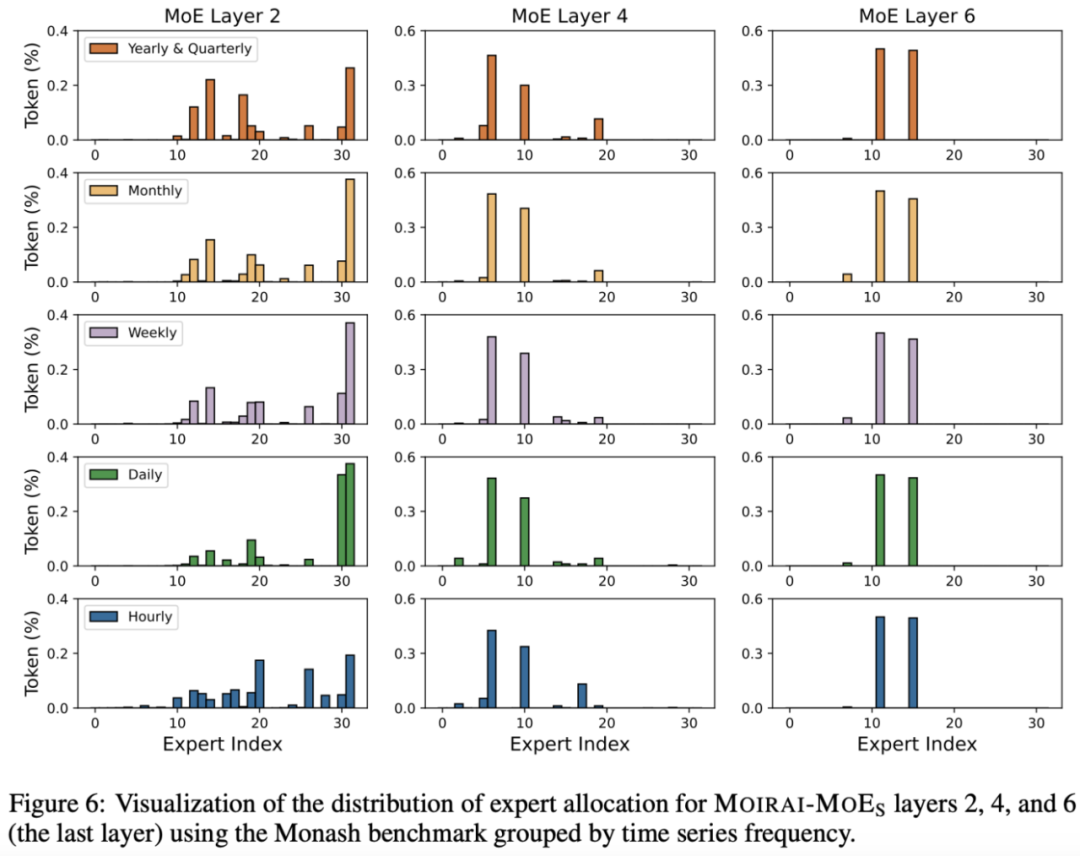
作者认为,这种人为强加的频率级专业化缺乏普适性,并引入了一些局限性。(1)频率并不总是一个可靠的指标,无法有效地捕捉时序数据的真实结构。如下图所示,具有不同频率的时间序列可以表现出相似的模式,而具有相同频率的时间序列可能显示出多样且不相关的模式。这种人为强加的频率和模式之间的不匹配削弱了模型专业化的有效性,从而导致性能下降。(2)现实世界的时间序列本质上是非平稳的,即使在单个时间序列的短窗口内也会显示出不同的分布。显然,频率级专业化的粒度无法捕捉这种程度的多样性,这凸显了对更细粒度的建模方法的需求。
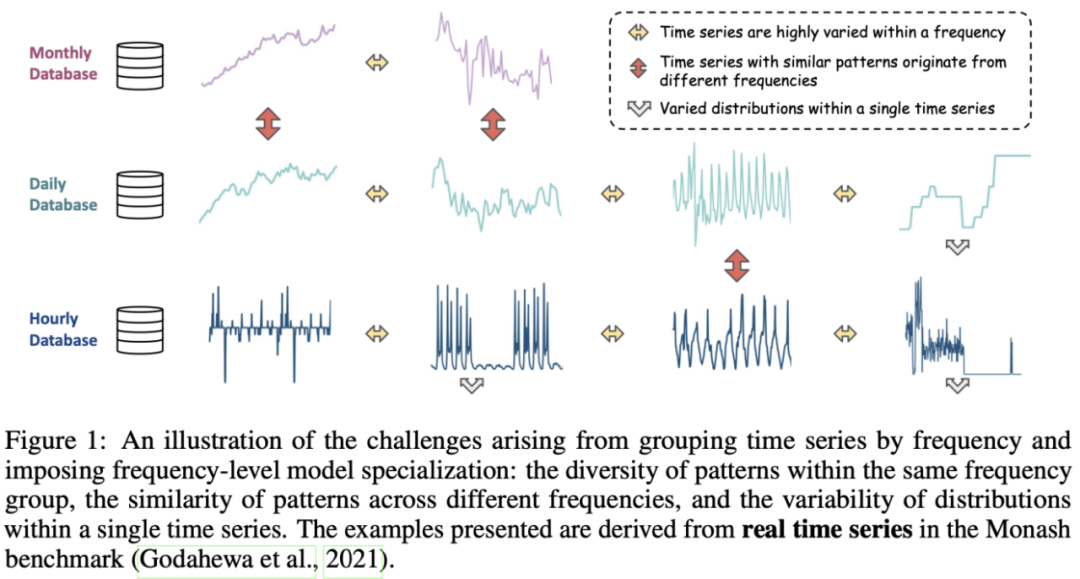
为了解决上述问题,作者提出了全新的时间序列统一训练解决方案 Moirai-MoE,其核心思想是利用单个输入 / 输出投影层,同时将各种时间序列模式的建模委托给 Transformer 层中的稀疏混合专家。通过这些设计,Moirai-MoE 的专业化以数据驱动的方式实现,并在 token 级别运行。
基于稀疏混合专家的时序基础模型
Moirai-MoE 构建在它的前序工作 Moirai 之上。虽然 Moirai-MoE 继承了 Moirai 的许多优点,但其主要改进在于:Moirai-MoE 不使用多个启发式定义的输入 / 输出投影层来对具有不同频率的时间序列进行建模,而是使用单个输入 / 输出投影层,同时将捕获不同时间序列模式的任务委托给 Transformer 中的稀疏混合专家。此外,Moirai-MoE 提出了一种新型的利用预训练模型中知识的门控函数,并采用自回归的训练目标来提高训练效率。下面简要介绍 Moirai-MoE 的模块。
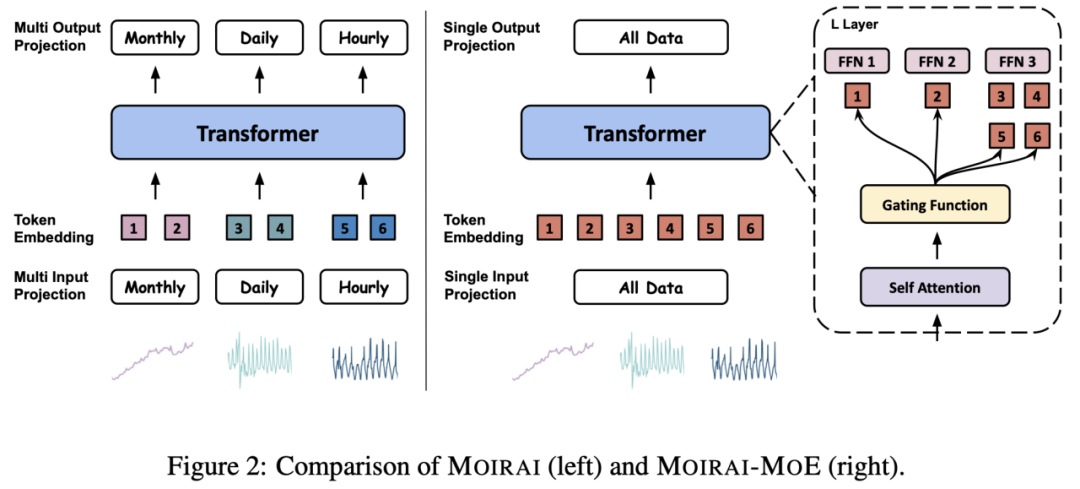
1. 时序 Token 构造
Moirai-MoE 采用切块(patching)技术将时间序列输入切成没有重叠的小块,而后对小块进行标准化来缓解分布迁移的问题。为了在自回归模型中获取准确、鲁棒的标准化统计值,作者引入掩蔽率 r 作为超参数,它指定整个序列中专门用于正则化器计算的部分,不对这些 patch 计算预测损失。最后,一个输入投影层来负责把 patch 投影到和 Transformer 一样的维度,生成时序 token。
2. 稀疏混合专家 Transformer
通过用 MoE 层替换 Transformer 的每个 FFN 来建立专家混合层。该 MoE 层由 M 个专家网络和一个门控函数 G 组成。每个 token 只激活一个专家子集,从而允许专家专注于不同模式的时间序列数据并确保计算效率。在 Moirai-MoE 中,作者探索了不同的门控函数。首先使用的是最流行的线性投影门控函数,它通过一个线性层来生成专家子集的分配结果。此外,作者提出了一种新的门控机制,利用从预训练模型的 token 表示中得出的聚类中心来指导专家分配。这一方法的动机是,与随机初始化的线性投影层相比,预训练 token 表示的聚类更接近数据的真实分布,可以更有效地实现模型专业化。
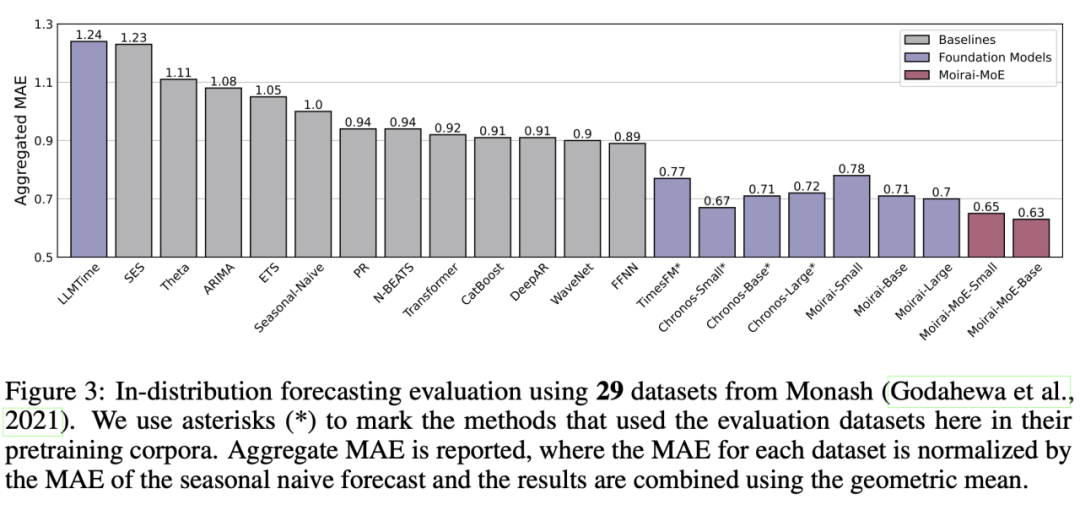
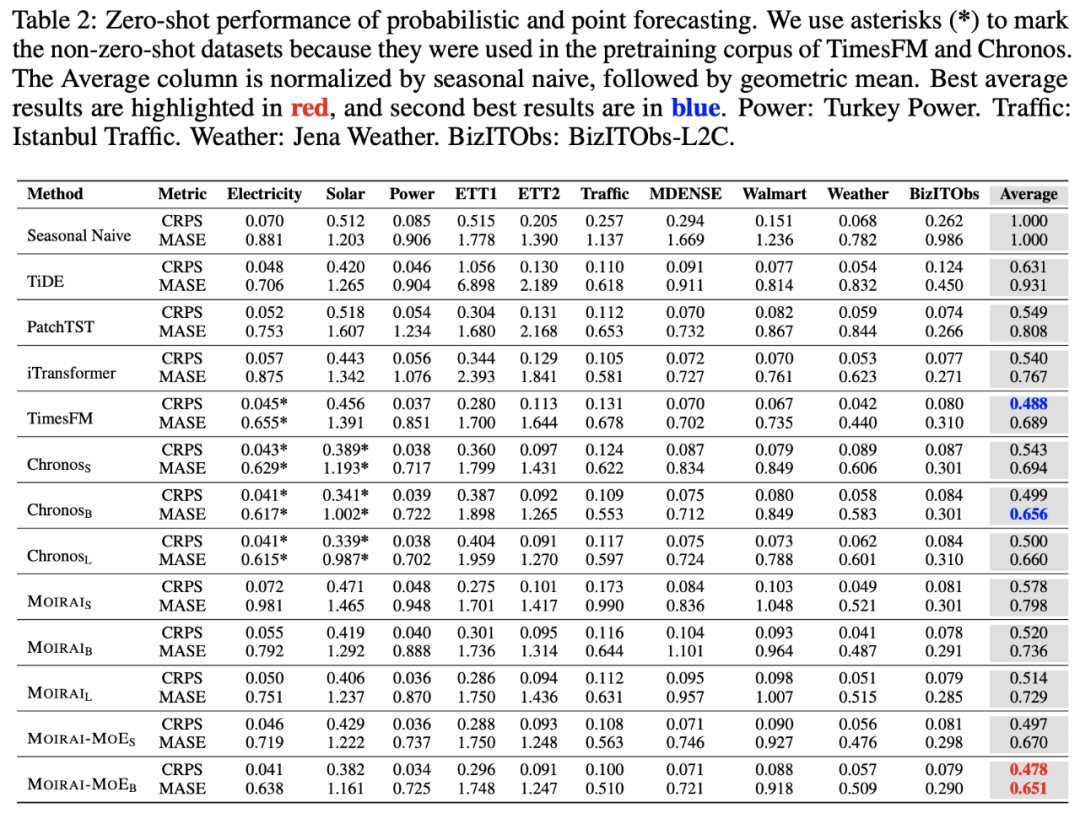
今天带大家了解了的相关知识,希望对你有所帮助;关于科技周边的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习