陈丹琦等人组织的COLM奖项公布:被ICLR拒稿的Mamba入选杰出论文
来源:机器之心
时间:2024-11-05 14:43:03 425浏览 收藏
学习科技周边要努力,但是不要急!今天的这篇文章《陈丹琦等人组织的COLM奖项公布:被ICLR拒稿的Mamba入选杰出论文》将会介绍到等等知识点,如果你想深入学习科技周边,可以关注我!我会持续更新相关文章的,希望对大家都能有所帮助!
会议组织者都是 NLP 头部科学家,在语言建模方面有着相当的成果。
随着 AI 领域的快速发展,大模型逐渐成为研究的核心,为了更好地探索这一领域,2023 年,一批知名的青年学者组织了一个名为 COLM(Conference on Language Modeling)的新会议。
该会议的组织者们都是 NLP 头部科学家,在语言建模方面有着相当的成果。他们其中既有来自业界的研究人员,也有来自学术界的研究人员。
在今年的组织者中,有我们熟悉的陈丹琦、Angela Fan 等华人学者。
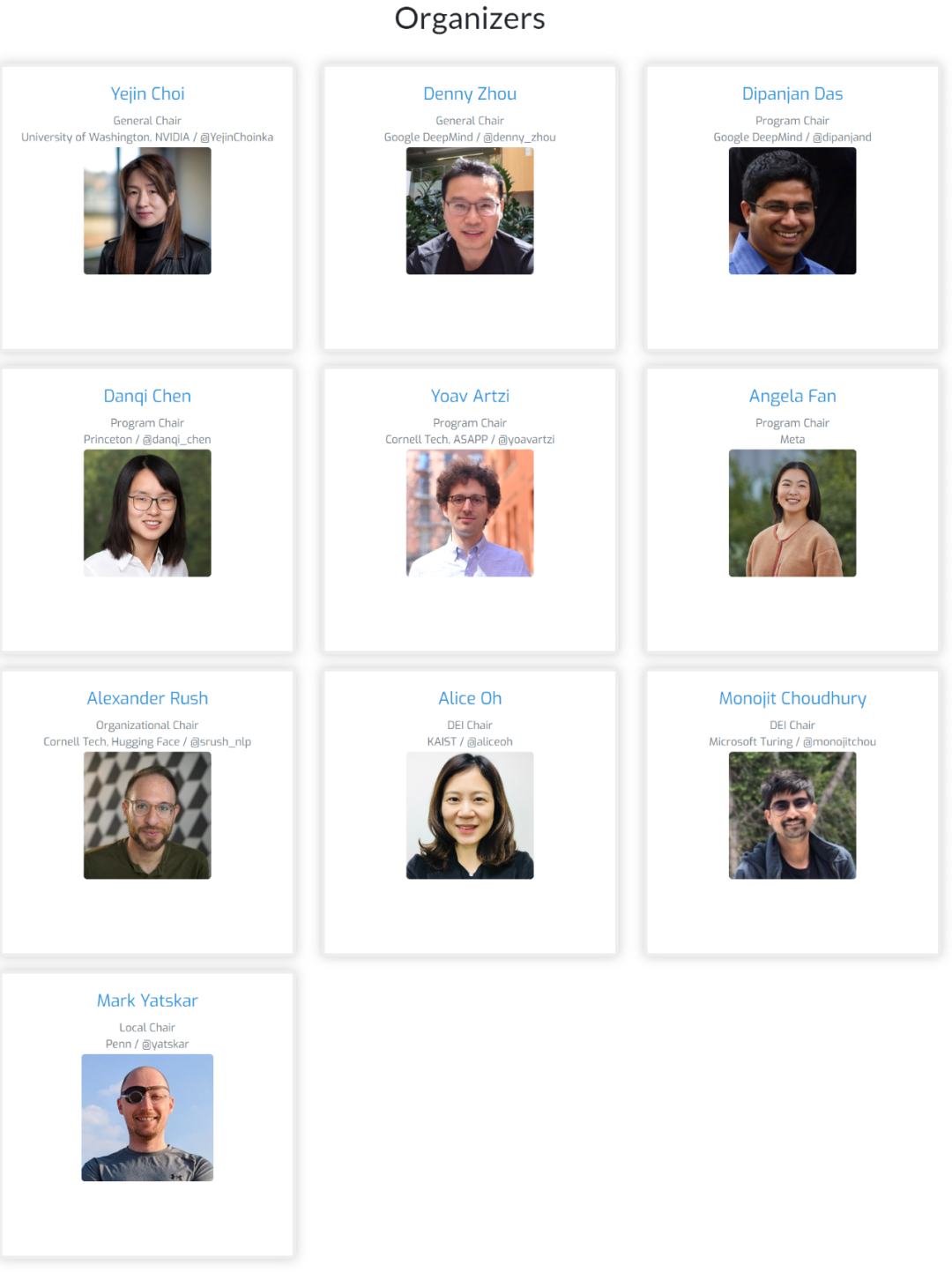
COLM 是一个专注于语言建模研究的学术场所,旨在创建一个具有不同科学专业知识的研究人员社区,专注于理解、改进和评论语言模型技术的发展。这不仅是学术界的一次创新尝试,也是搭起了语言模型交流互鉴的新桥梁,进一步促进其探索和合作。

接收论文链接:https://colmweb.org/AcceptedPapers.html
刚刚,大会公布了 2024 年杰出论文奖,共有 4 篇论文获奖。
值得一提的是,号称撼动 Transformer 统治地位的 Mamba 也在获奖论文中。
此前,Mamba 这项研究惨遭 ICLR 拒稿,引来学术界轩然大波。
不过,之后 Mamba 原班人马发布的 Mamba-2 顺利拿下了 ICML 2024。如今 Mamba 又获得了 COLM 杰出论文奖,很多网友都送来祝贺。
Mamba 作者之一、卡内基梅隆大学机器学习系助理教授 Albert Gu 用一张表情很好的表达了自己的感受,看来「COLM 是真香」。

杰出论文奖
论文 1:Dated Data: Tracing Knowledge Cutoffs in Large Language Models
机构:霍普金斯大学
作者:Jeffrey Cheng、Marc Marone、Orion Weller、Dawn Lawrie等
论文地址:https://openreview.net/pdf?id=wS7PxDjy6m

大型语言模型 (LLM) 通常有「知识截止日期」,即收集训练数据的时间。该信息对于需要 LLM 提供最新信息的应用场景至关重要。
然而,训练数据中所有子资源是否共享相同的「知识截止日期」?模型响应展示出的知识是否与数据截止值一致?

该论文定义了「有效截止」的概念,它与 LLM 报告的「知识截止日期」不同,并且训练数据子资源之间也有所不同。该研究提出了一种简单的方法,通过跨版本的数据探测来估计 LLM 在资源级别的有效截止点。至关重要的是,该方法不需要访问模型的预训练数据。
通过分析,该研究发现有效的截止值通常与报告的截止值有很大不同。为了了解这一观察结果的根本原因,该研究对开放的预训练数据集进行了大规模分析。
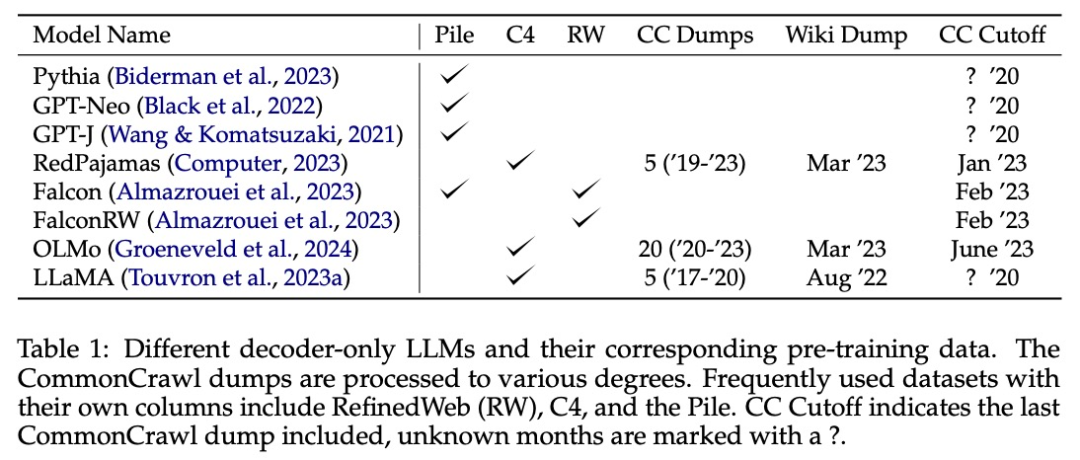
分析揭示了造成这些不一致的两个主要原因:
由于新 dump 中存在大量旧数据,导致 CommonCrawl 数据出现时间错位;
LLM 重复数据删除方案的复杂性涉及语义重复和词汇近似重复。
论文 2:Mamba: Linear-Time Sequence Modeling with Selective State Spaces
机构:卡内基梅隆大学、普林斯顿大学
作者:Albert Gu、Tri Dao
论文地址:https://arxiv.org/pdf/2312.00752

自 2017 年被提出以来,Transformer 已经成为 AI 大模型的主流架构,但随着模型规模扩大和处理序列变长,其计算效率问题凸显,特别是在长上下文中,计算量将呈平方级增长。
为解决这一问题,研究者们围绕注意力开发了多种变体,如线性注意力、门控卷积、循环模型、SSMs 等,但它们在语言等模态上的表现并不理想,无法进行基于内容的推理。
基于此,论文作者进行了几项改进。首先,让 SSM 参数成为输入的函数,解决了离散模态的弱点,使模型能根据当前 token 有选择地传播或遗忘信息。
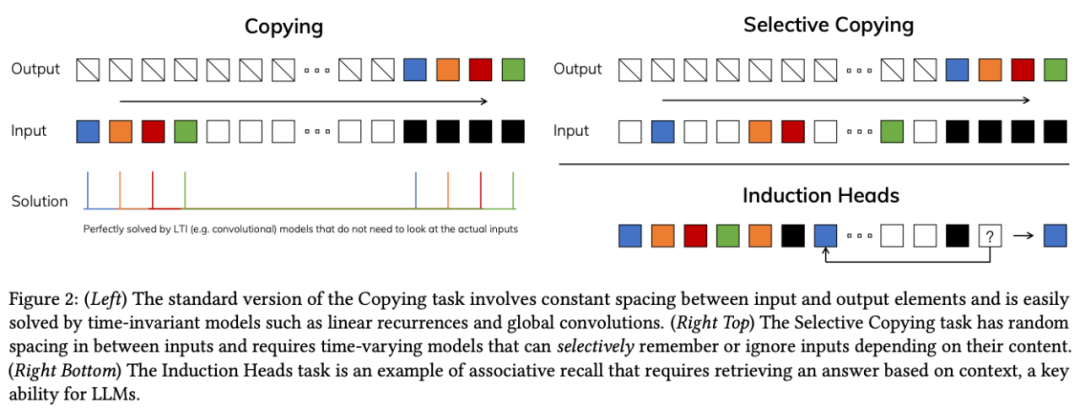
这种改动导致卷积效率降低,对模型的计算带来了挑战。论文作者设计了一种硬件感知算法,将先前的 SSM 架构设计与 Transformer 的 MLP 块合并为一个块,简化了深度序列模型架构,形成了一种包含选择性状态空间的简单、同质的架构设计(Mamba)。
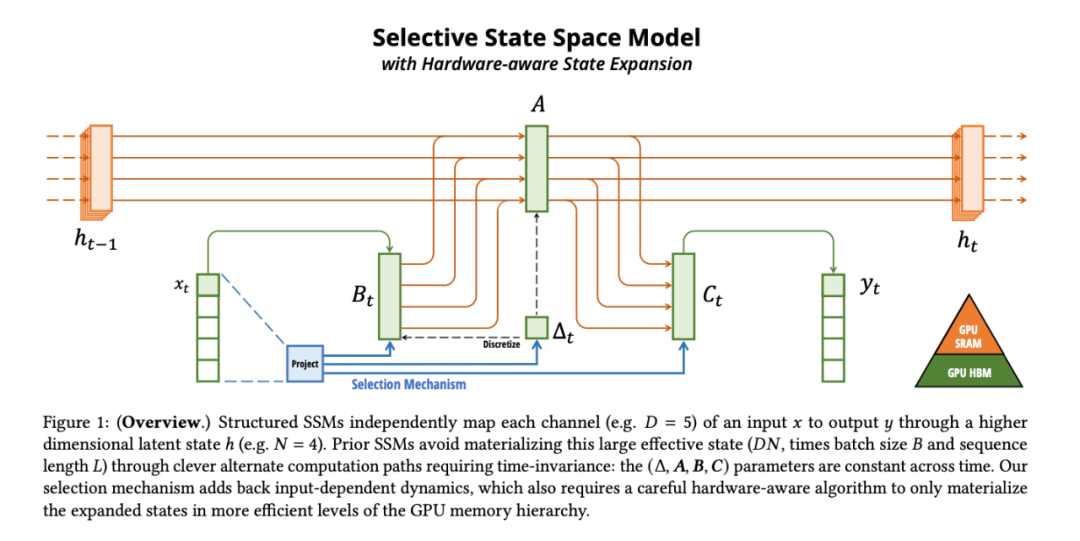
Mamba 可以随上下文长度的增加实现线性扩展,其性能在实际数据中可提高到百万 token 长度序列,并实现 5 倍的推理吞吐量提升。
作为通用序列模型的骨干,Mamba 在语言、音频和基因组学等多种模态中都达到了 SOTA 性能。在语言建模方面,无论是预训练还是下游评估,他们的 Mamba-3B 模型都优于同等规模的 Transformer 模型,并能与两倍于其规模的 Transformer 模型相媲美。
更多详情,可以参考本站之前的报道:五倍吞吐量,性能全面包围 Transformer:新架构 Mamba 引爆 AI 圈。
论文 3:AI-generated text boundary detection with RoFT
机构:俄罗斯 AI 基金会与算法实验室、英国伦敦玛丽女王大学、日本 Noeon 研究所、斯科尔科沃科学技术学院等
作者:Laida Kushnareva, Tatiana Gaintseva, Dmitry Abulkhanov等
论文地址:https://arxiv.org/pdf/2311.08349

随着大语言模型的发展,我们越来越频繁地遇到这样的情况:一篇文章起初可能出自人类之手,但随后可能被 AI 接手加以润色。如何从这种文本中检测出人类写作与机器生成的界限?这是一个具有挑战性的问题,但还尚未得到太多关注。
论文作者试图填补这一空白。他们对最先进的检测方法进行了测试。具体而言,他们采用「真假文本」测试集,测试了在极限情况下,这些方法的表现。「真假文本」测试集包含各种语言模型生成的多个主题的短文本。

他们发现,基于困惑度的边界检测方法,在处理特定领域的数据时,比对 RoBERTa 模型进行监督式的方法更加鲁棒。他们还发现了一些特定的文本特征。这些特征可能会干扰边界检测算法的判断,导致算法在处理跨领域的文本时,其性能会下降。
论文 4:Auxiliary task demands mask the capabilities of smaller language models
机构:哈佛大学、斯坦福大学
作者:Jennifer Hu、Michael Frank
论文地址:https://openreview.net/forum?id=U5BUzSn4tD#discussion

发展心理学家一直在争论语言理解或心理理论等认知能力何时出现。这些争论通常取决于「任务要求」的概念 —— 与执行特定评估相关的挑战。在衡量语言模型 (LM) 的能力时,任务的性能是模型基础知识的函数,再加上模型在给定可用资源的情况下解释和执行任务的能力。
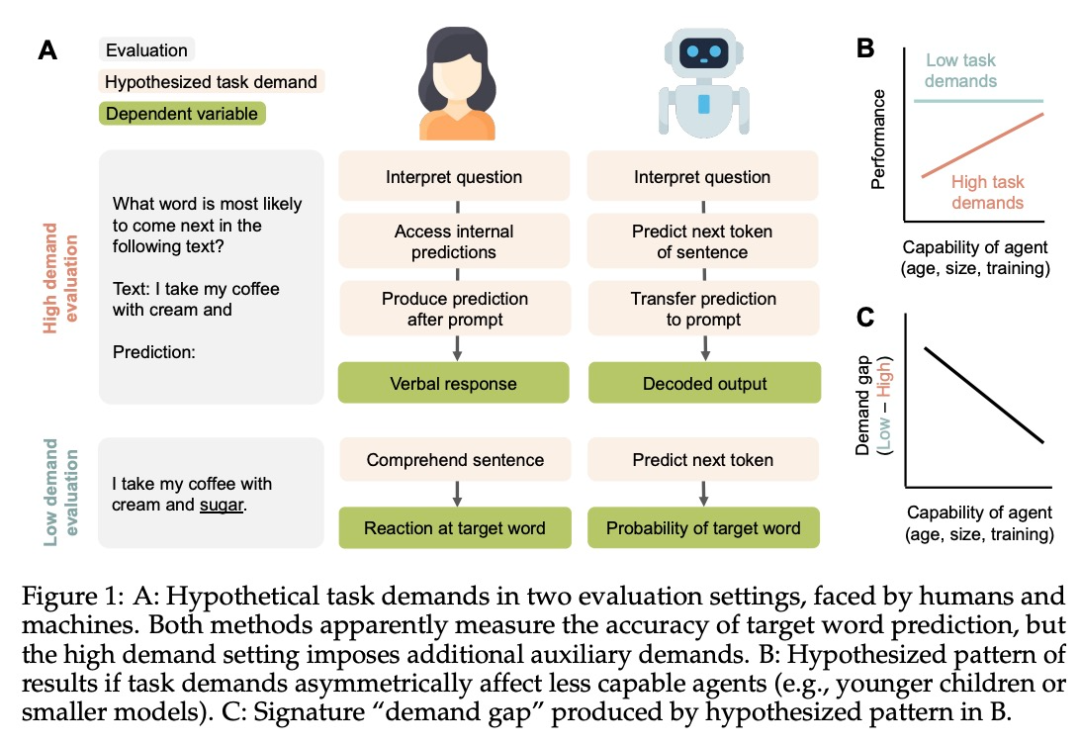
该研究表明,对于类比推理、反思推理、单词预测和语法判断,任务要求较高的评估方法比要求减少的评估方法产生的性能更低。对于参数较少和训练数据较少的模型,这种「需求差距」最为明显。实验结果表明,LM 的性能不应被解释为智能(或缺乏智能)的直接表现,而应被解释为通过研究人员设计选择的视角所看到的能力反映。
好了,本文到此结束,带大家了解了《陈丹琦等人组织的COLM奖项公布:被ICLR拒稿的Mamba入选杰出论文》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多科技周边知识!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
309 收藏
-
234 收藏
-
科技周边 · 人工智能 | 2天前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream448 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习