大模型合成数据机理分析,人大刘勇团队:信息增益影响泛化能力
来源:机器之心
时间:2024-11-18 18:39:41 126浏览 收藏
怎么入门科技周边编程?需要学习哪些知识点?这是新手们刚接触编程时常见的问题;下面golang学习网就来给大家整理分享一些知识点,希望能够给初学者一些帮助。本篇文章就来介绍《大模型合成数据机理分析,人大刘勇团队:信息增益影响泛化能力》,涉及到,有需要的可以收藏一下

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。在此基础上,本文证明了后训练模型的泛化能力关键取决于生成模型带来的信息增益,并从一个新的反向瓶颈视角进行了分析。此外,本文引入了互信息泛化增益(GGMI)的概念,阐明了泛化增益与信息增益之间的关系。我们希望为合成数据的应用提供理论基础,进而为合成数据生成技术的设计与后训练过程的优化提供新的理解。
It's not the form of data, but the information it brings that truly matters.
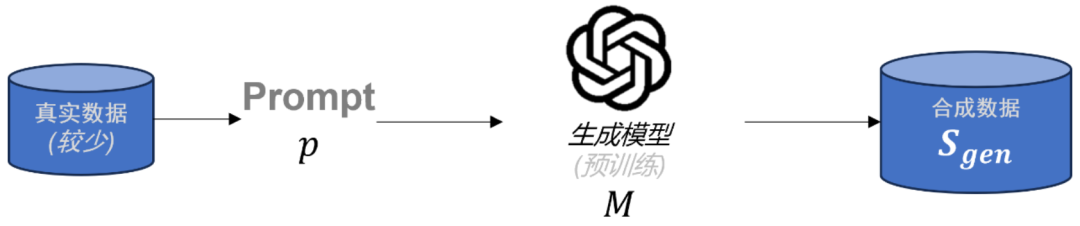
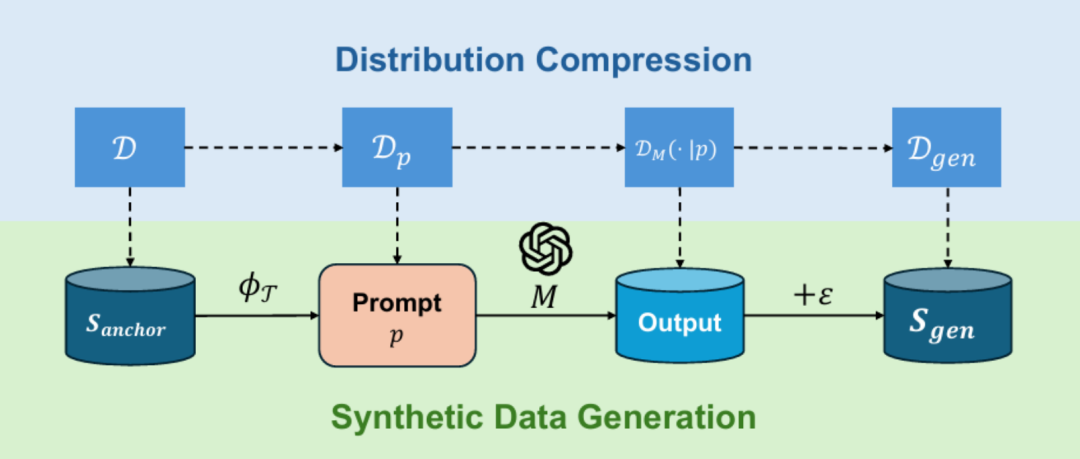
图表 1: 合成数据一般生成范式
正如著名的 Scaling laws 所说的那样,大语言模型(LLMs)的效能在很大程度上依赖于训练数据的规模和质量 [1]。然而,在 LLM 的后训练阶段,尤其是在微调和模型对齐的过程中,可用的高质量数据十分稀缺。
为解决这一问题,在真实数据匮乏的情况下合成数据在最近的研究中里逐渐成为增强模型训练的关键手段。截至 2024 年 9 月,在 Hugging Face 平台上标注为 “合成” 的数据集已超过 1000 个。许多前沿的大语言模型,如 LLaMA [2]、Falcon [3]、Qwen [4] 和 GPT-4 [5] 都在其技术报告中表面在后训练阶段广泛使用了合成数据。
近年来,研究人员提出了多种合成数据生成方法 [6-8],其中最为有效且常见的是通过一个在相关内容上进行过预训练的大语言模型生成合成数据。具体来说,生成过程通常是基于少量的真实数据,编写一组特定的 prompt,再经由生成模型生成具有针对性和高质量的合成数据,如图 1 所示。这种方法不仅能够缓解后训练过程中数据不足的问题,还能够为模型提供更丰富的任务相关信息,进而提升模型的泛化能力和对齐精度。这一范式已经在多个前沿的大语言模型中得到了广泛应用,显示出其在后训练任务中的巨大潜力。
然而,当前对合成数据的建模和理论分析仍然存在显著的不足,这在一定程度上限制了我们对其内在机制的深入理解 [9]。缺乏系统的理论框架使得我们难以准确预测合成数据在不同 LLM 应用中的有效性,也限制了生成模型在更具针对性的合成数据生成方面的优化 [10]。
因此,深入研究合成数据在模型训练过程中的作用成为提升模型性能和可靠性的重要方向。通过加强对合成数据与大语言模型在训练阶段如何相互作用的理解,我们有望开发出更加精准的合成数据集,有效填补训练数据中的特定空白,进而全面提升模型的表现和泛化能力。这不仅能为大语言模型在各类任务中的应用提供强有力的支持,还为未来的模型优化提供了理论依据。
合成数据为何能有效提升模型能力?这种提升又是基于什么关键因素?针对这些核心问题,我们将从对合成数据生成过程的建模开始,将其与模型的泛化能力建立联系,并试图探究这一框架下影响模型泛化能力的关键因素。

论文标题:Towards a Theoretical Understanding of Synthetic Data in LLM Post-Training: A Reverse-Bottleneck Perspective 论文链接:https://arxiv.org/abs/2410.01720
在此工作中,我们主要作出了如下贡献:
我们对合成数据生成过程的进行了更加详尽的数学建模,并从期望的角度揭示了这一过程的本质,即对生成模型输出的分布的压缩; 我们将合成数据的生成过程与后训练模型的泛化能力进行了连接,并提出了 “反信息瓶颈” 视角,解释了合成数据在训练过程中的作用机理; 我们基于上述分析,从信息论的角度为合成数据训练的模型提出了泛化误差上界,并揭示了用于合成数据生成的生成模型所带来的信息增益的重要地位。
模拟实验设置
如图 2 所示,在本研究中,我们使用混合高斯模型(GMM)来对合成数据的生成过程进行模拟。
简单来说,我们设置了一个包含 K+J 个子高斯分布的 GMM 作为 ground-truth(gt-GMM),并在此基础上引入 L 个额外的随机子高斯分布构成用于模拟生成模型的 M。我们从 gt-GMM 的前 K 个子高斯进行采样作为真实数据,从 M 中进行采样作为最终的合成数据,并将其用于后续的验证。
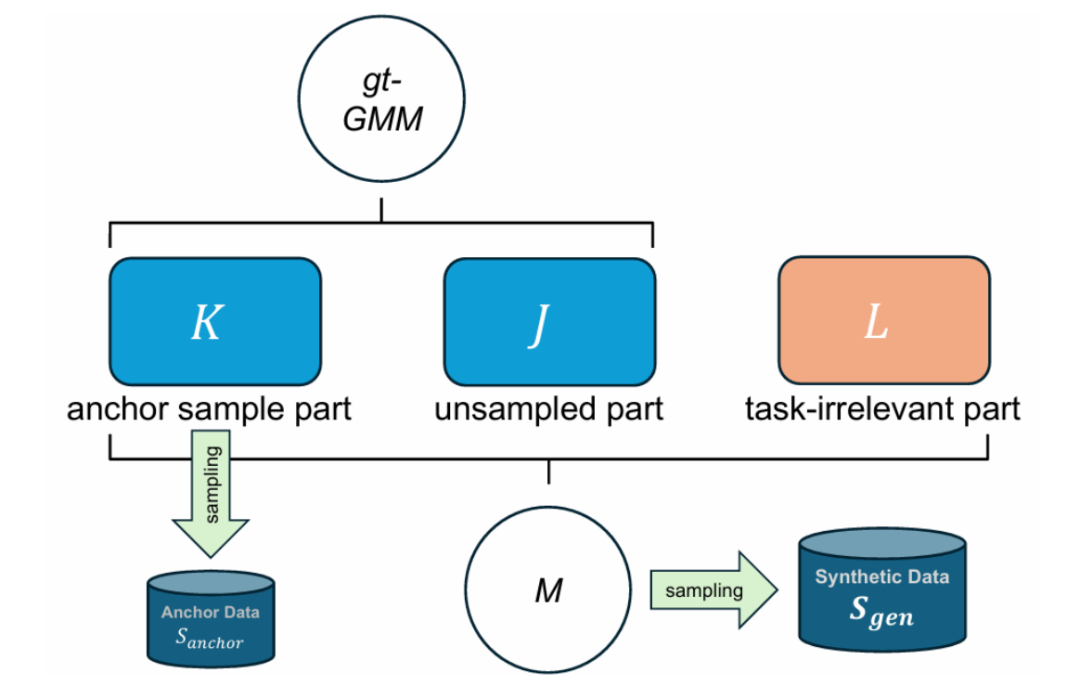
图表 2: 模拟实验设置
1 合成数据的生成过程是对生成模型输出分布的压缩
合成数据的生成可以形象化的表达为如下的过程 [11]。记用于产生 prompt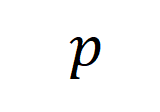 的少量真实数据为锚点
的少量真实数据为锚点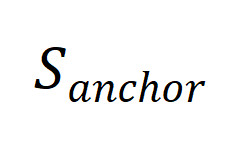 ,合成数据为
,合成数据为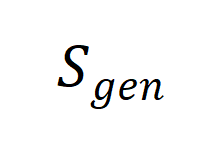 ,后训练的目标任务为
,后训练的目标任务为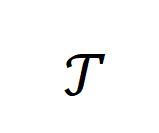 。对于这一过程,一种抽象化的数学表达如下所示:
。对于这一过程,一种抽象化的数学表达如下所示:
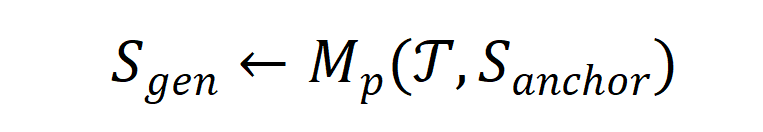
这一公式表示合成数据是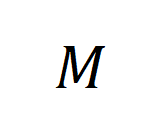 在
在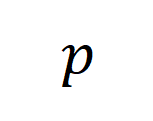 上限定的表达,并且主要与目标任务和锚点数据有关。
上限定的表达,并且主要与目标任务和锚点数据有关。
其中,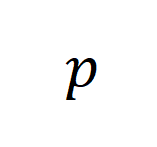 则主要与三种分别代表 “任务”
则主要与三种分别代表 “任务”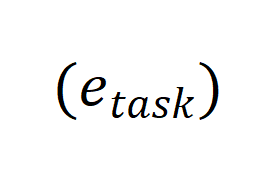 、“条件”
、“条件”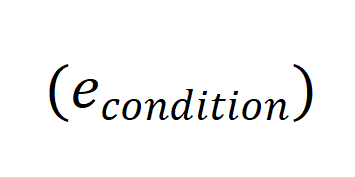 和 “锚点数据”
和 “锚点数据”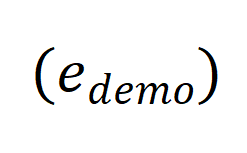 的元素相关:
的元素相关:
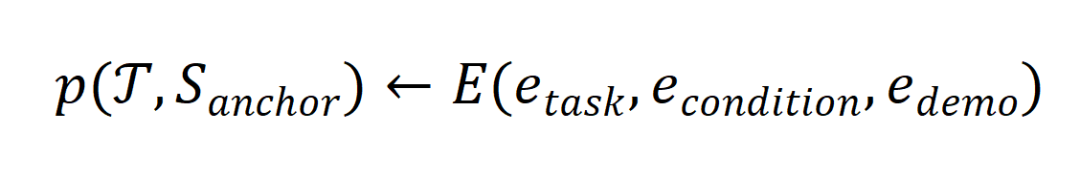
基于此观点,并结合实际应用中的生成步骤,我们进一步用等式的形式表达了合成数据的实际生成过程。
首先,合成数据可以看作是 在
在 上的直接输出与其他的调整两部分组成。
上的直接输出与其他的调整两部分组成。
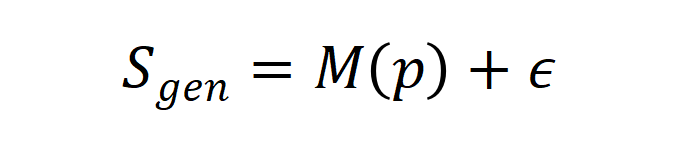
其中,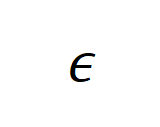 表示为了让得到的合成数据具有可用性的格式与内容调整,例如数据策展等。
表示为了让得到的合成数据具有可用性的格式与内容调整,例如数据策展等。
而更进一步,prompt 则可以表达为根据任务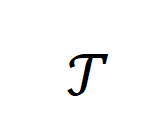 对锚点数据的转换:
对锚点数据的转换:
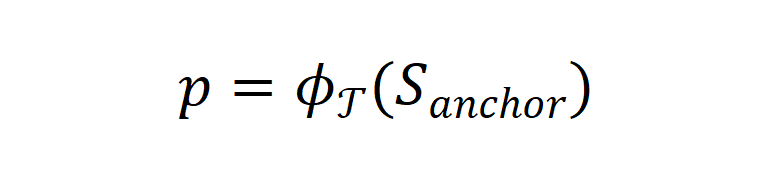
将这一过程中涉及到的变量视为随机变量,并写出它们对应的分布,我们可以得到数据生成过程和对应的分布变化过程,如图 3 所示。
图表 3: 合成数据生成与分布变化过程
假设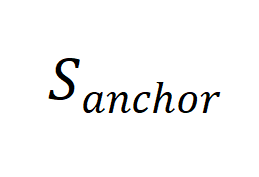 采样自后训练的目标任务分布
采样自后训练的目标任务分布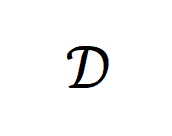 ,生成模型
,生成模型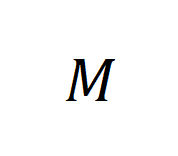 的输出服从分布
的输出服从分布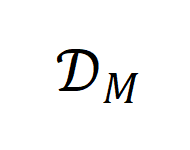 ,其在上受限的输出服从分布
,其在上受限的输出服从分布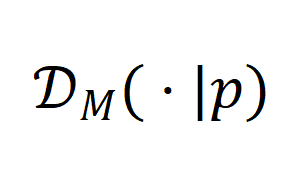 ,而最终的合成数据服从分布
,而最终的合成数据服从分布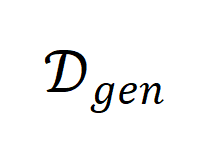 。
。
从数据合成过程来看,合成数据是在上的调整输出。
若将其视为 “Prompting” 和 “Data Curation” 两个步骤,数据合成的过程实质上是在对 向
向 进行压缩。如图 4 所示。其中,所有蓝色的部分表示
进行压缩。如图 4 所示。其中,所有蓝色的部分表示 ,而深蓝色的部分表示
,而深蓝色的部分表示 。
。
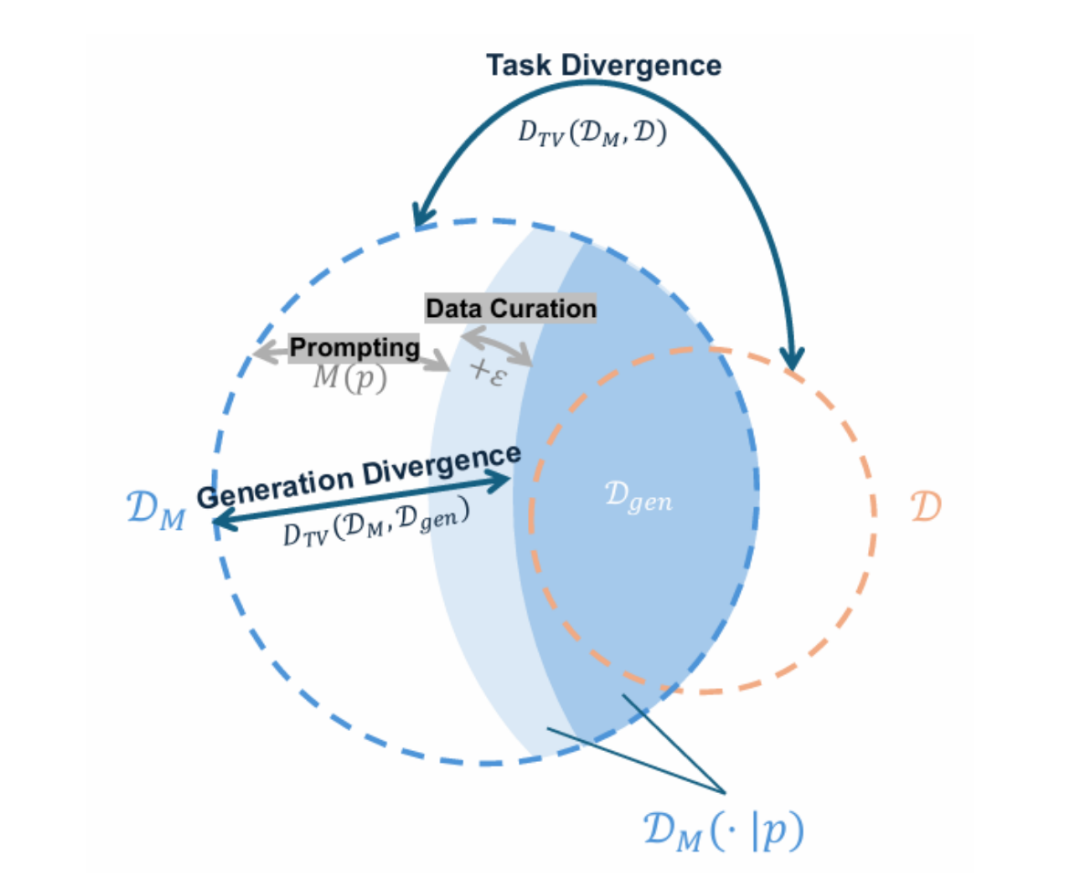
图表 4: 分布的压缩过程示意图
值得注意的是,由于压缩的不完全性, 最终不一定会完全覆盖,也有可能会产出不属于的输出,这一现象也为后续体现的信息增益提供了较为直观的解释。
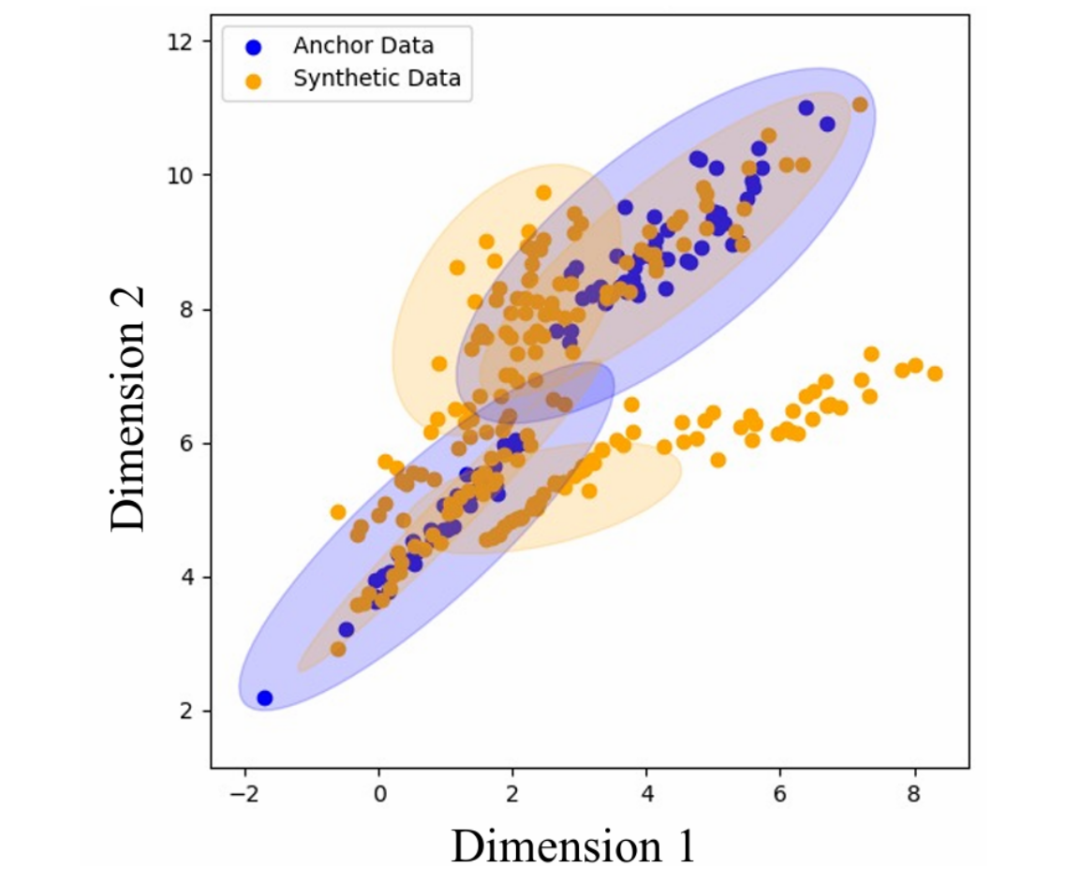
图表 5: GMM 模拟实验分布结果
我们使用一组混合高斯模型(GMM)对合成数据的生成进行了模拟,结果如图 5 所示。其中,蓝色的点为锚点数据,采样自用蓝色椭圆表示中心的分布中。黄色的点为合成数据,采样自黄色椭圆表示中心的分布中。
在实验的设置中,合成数据(黄色)的分布是对锚点数据(蓝色)观测的拟合和模拟,但由于 GMM 具体设置的差异,黄色椭圆最终无法完全覆盖蓝色椭圆,并且还覆盖了蓝色椭圆未覆盖的位置,这与之前的分析相符。
2 连接数据合成过程与模型的泛化能力
对合成数据的生成过程的建模从分布的角度刻画了其本质特征。
为了将这一特征与后训练模型的能力相结合,我们从模型的泛化能力切入并进行相应的分析。首先,我们将大模型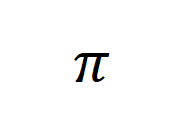 在合成数据
在合成数据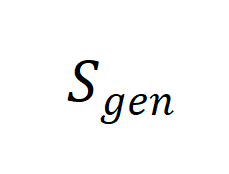 上进行训练后得到的后训练模型
上进行训练后得到的后训练模型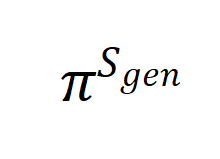 的泛化误差表示为:
的泛化误差表示为:
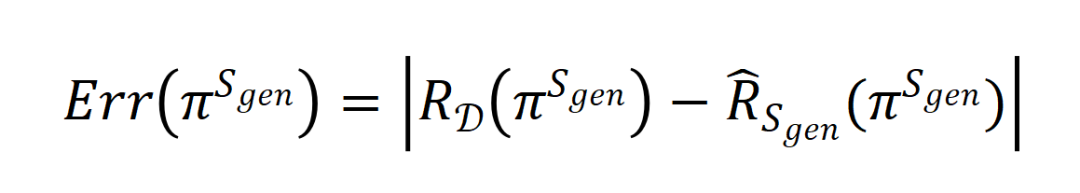
其中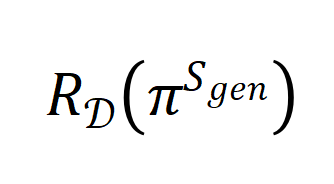 和
和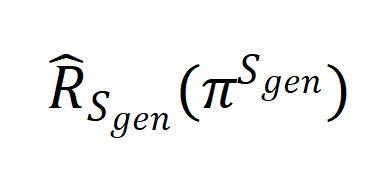 分别表示模型在分布上的真实误差和在数据
分别表示模型在分布上的真实误差和在数据 上的经验误差。
上的经验误差。
经过进一步的分析与推导(详见正文及附录),最终,模型的泛化误差具有如下引理中的上界:
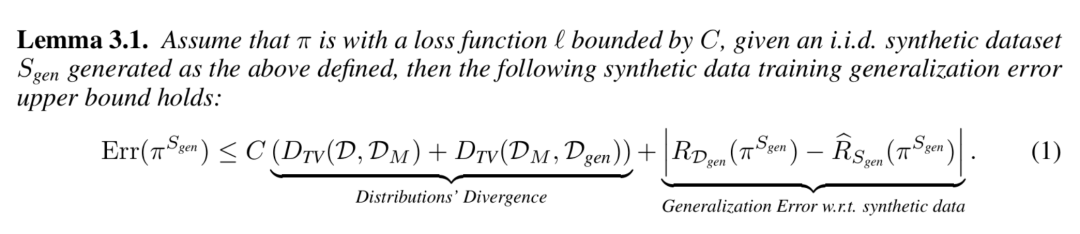
此引理将 的泛化误差上界分为了两个部分,分别是 “分布间的散度” 和 “与合成数据有关的泛化误差” 。
的泛化误差上界分为了两个部分,分别是 “分布间的散度” 和 “与合成数据有关的泛化误差” 。
对于前一部分,主要与数据合成中采用的生成模型和任务本身的性质有关,而后一部分将成为我们分析的重点。
3 “逆信息瓶颈” 视角下的泛化误差上界
3.1 “逆信息瓶颈”
注意到,合成数据的生成过程其实和一个典型的机器学习过程在形式上非常类似,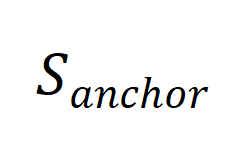 经由
经由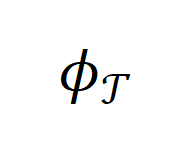 得到 prompt ,再经由得到,十分类似于一个经典的 enc-dec 结构的机器学习过程,如图 6 左侧所示。
得到 prompt ,再经由得到,十分类似于一个经典的 enc-dec 结构的机器学习过程,如图 6 左侧所示。
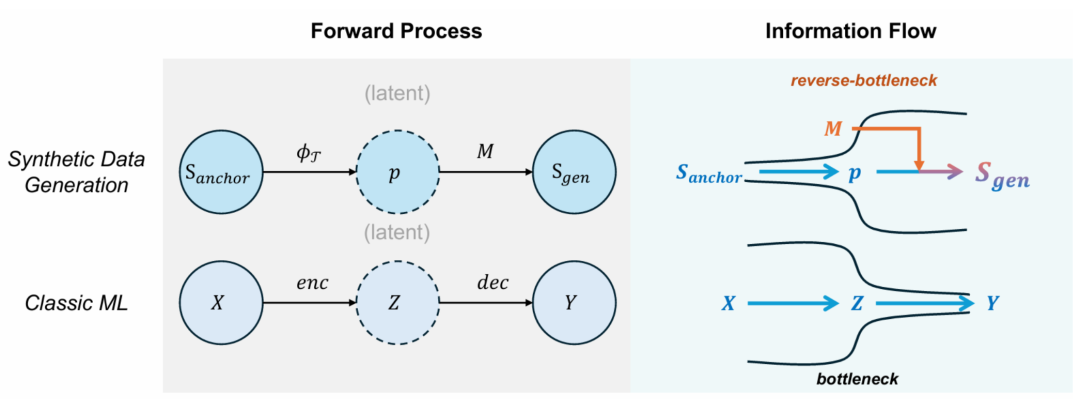
图表 6: 逆信息瓶颈示意图
然而,正因为大模型中合成数据与传统机器学习的关键不同之处:生成模型是事先预训练的,导致从信息流的视角下二者具有相反的性质。如图 6 右侧所示,在合成数据的生成过程中,信息量是一个被扩充的过程。
传统机器学习过程中信息是逐步被压缩的,因此存在信息瓶颈;而在生成的过程中,由于的存在,实质为这一过程扩充了额外的信息,从而形成了一种 “逆信息瓶颈”。
3.2 “逆信息瓶颈” 视角下的泛化误差分析
刻画这一 “逆信息瓶颈” 的关键就是刻画引入的信息增益。我们首先定义了合成因子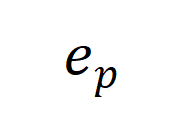 和
和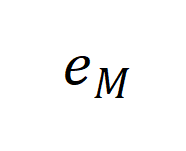 ,其中
,其中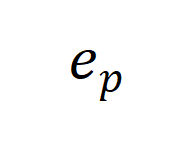 是和 prompt 有关的因子,
是和 prompt 有关的因子,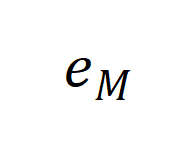 是和生成模型有关的因子。
是和生成模型有关的因子。

我们将信息增益记为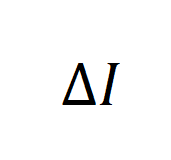 ,并从信息论的角度出发,定义如下:
,并从信息论的角度出发,定义如下:
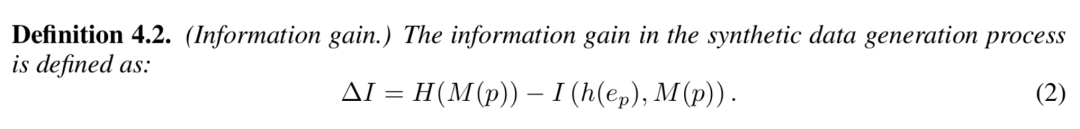
可以看出, 衡量了在数据生成的过程中,除开 prompt 的影响后,由生成模型所引入的信息量。
衡量了在数据生成的过程中,除开 prompt 的影响后,由生成模型所引入的信息量。
接着,我们考虑合成数据和后训练模型的参数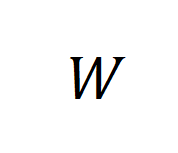 之间的互信息,并发现其存在可以由
之间的互信息,并发现其存在可以由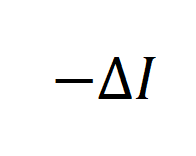 所约束的上界:
所约束的上界:
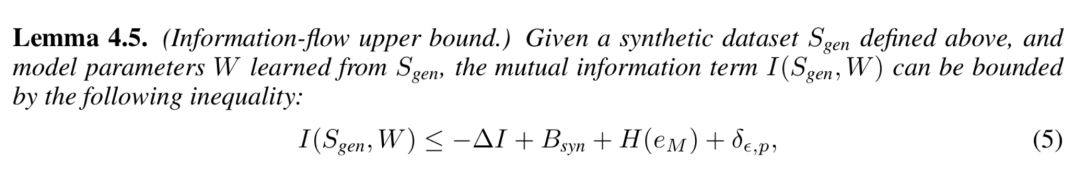
根据信息瓶颈理论已有的研究结果,经过一定的推导,并与之前的结论相结合,我们为的期望泛化误差寻找到了一个最终的上界:

这一上界的关键部分由 所控制。直观上可见,当更多的信息增益被引入时, 将具有更加紧凑的期望泛化误差上界,从而获得更好的泛化性能。
所控制。直观上可见,当更多的信息增益被引入时, 将具有更加紧凑的期望泛化误差上界,从而获得更好的泛化性能。
4 合成数据的泛化增益
之前的分析将后训练大模型的泛化能力与合成数据的生成过程联系在了一起,并引入了信息增益的概念,从而解释了合成数据能够提升模型性能的原因。基于此更进一步,我们将探究第二个问题,即合成数据的应用是从哪些方面带来泛化能力提升的。
首先,我们考虑仅在锚点数据上进行训练的模型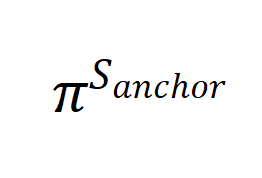 的期望泛化误差上界:
的期望泛化误差上界:
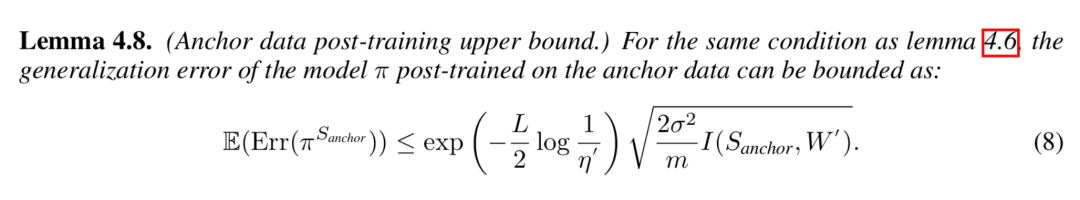
显然,合成数据带来的泛化能力的提升主要体现在数据的规模上,即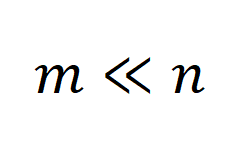 。
。
除了数据规模带来的提升外,合成数据中所引入的新信息是否也能带来泛化能力的提升呢?为此,我们从互信息项作为切入,定义了如下的衡量标准:GGMI。

直观上,更大的 GGMI 表示合成数据带来了更加紧凑的互信息项,从而降低了模型整体的泛化误差上界。
经过一定的推导从而消除不统一的参数项,GGMI 存在如下的上界:
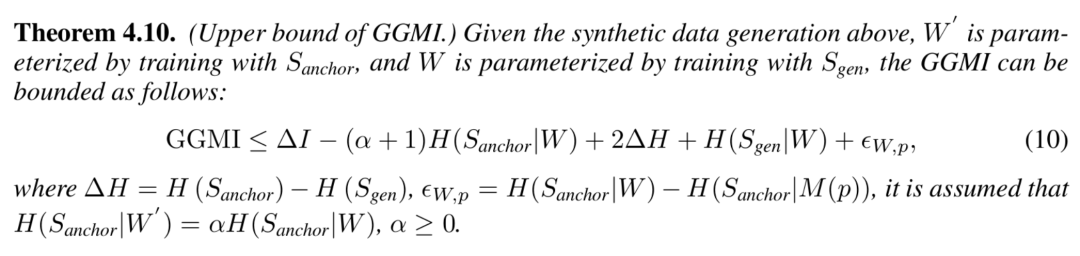
可以看出, 对于 GGMI 的增长也具有重要的作用。此外,降低熵等目标也有助于合成数据提供更好的泛化增益。
我们继续在 GMM 的设定上对这一结果进行模拟。按照上述合成数据的生成过程,我们分别得到了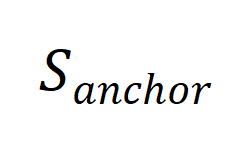 和,并用其分别训练得到了 GMM
和,并用其分别训练得到了 GMM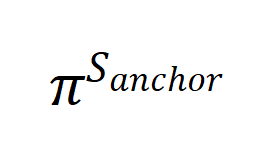 和,并设计了一个 ground-truth GMM
和,并设计了一个 ground-truth GMM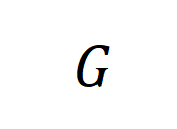 来表示真正的目标分布。为了衡量
来表示真正的目标分布。为了衡量 和的输出与
和的输出与 之间的差距的相对大小,我们基于 KL 散度定义了 KL Gap:
之间的差距的相对大小,我们基于 KL 散度定义了 KL Gap: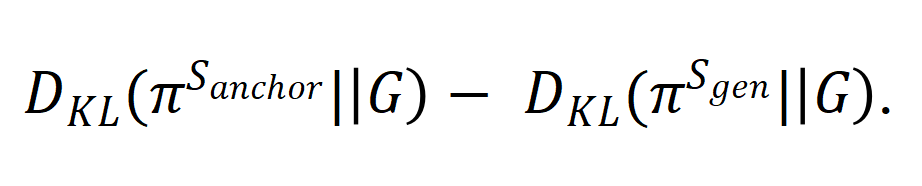 . 模拟实验的结果如下:(增大
. 模拟实验的结果如下:(增大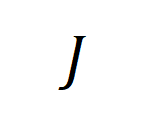 有助于增大
有助于增大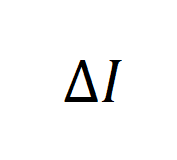 ,而增大
,而增大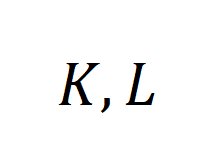 会分别影响 GGMI 上界中其他信息熵项
会分别影响 GGMI 上界中其他信息熵项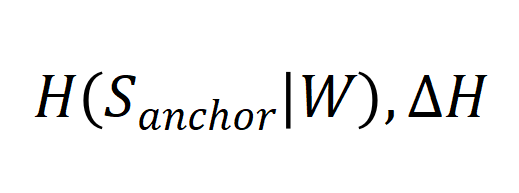 。
。
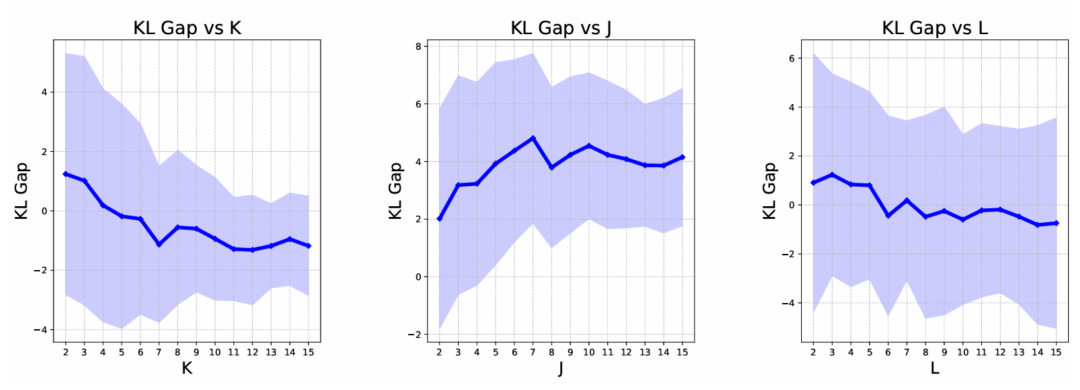
图表 7: GMM 泛化增益模拟实验结果
从图 7 中可以看出,更大的信息增益能有效提升 KL Gap,即提升了使用合成数据训练的模型相比于未使用合成数据的模型对 ground-truth 的拟合结果。此外,对其他变量的改变也相应的影响了 KL Gap 的结果,进一步验证了这一结论。
5 小结
我们从大模型中合成数据的生成过程出发,为常见的数据合成提供了数学上的建模,并将其与模型的泛化能力相结合,从而为合成数据的应用提供了理论基础。基于此,我们从独特的 “逆信息瓶颈” 视角切入,将模型的泛化能力归约在了生成模型所引入的信息增益上,并通过模拟实验的形式进行了验证。
在未来的工作中,一方面我们希望能为大模型合成数据的作用机理提供更加深入的解析,从而为数据合成的方法研究提供理论依据;另一方面,我们希望能解决生成模型与后训练任务间匹配的关系,通过动态的方式自适应的提升合成数据的质量。
作者介绍
刘勇,中国人民大学,长聘副教授,博士生导师,国家级高层次青年人才。长期从事机器学习基础理论研究,共发表论文 100 余篇,其中以第一作者 / 通讯作者发表顶级期刊和会议论文近 50 篇,涵盖机器学习领域顶级期刊 JMLR、IEEE TPAMI、Artificial Intelligence 和顶级会议 ICML、NeurIPS 等。获中国人民大学 “杰出学者”、中国科学院 “青年创新促进会” 成员、中国科学院信息工程研究所 “引进优青” 等称号。主持国家自然科学面上 / 基金青年、北京市面上项目、中科院基础前沿科学研究计划、腾讯犀牛鸟基金、CCF - 华为胡杨林基金等项目。
甘泽宇,中国人民大学高瓴人工智能学院博士研究生,本科及硕士研究生毕业于中国人民大学信息学院。当前主要研究方向包括大模型对齐与机器学习理论。
参考文献
[1] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
[2] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, and et al. The llama 3 herd of models, 2024. URLhttps://arxiv.org/abs/2407.21783.
[3] Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, and et al. The falcon series of open language models, 2023. URL https://arxiv.org/abs/2311.16867.
[4] Jinze Bai, Shuai Bai, Yunfei Chu, and et al. Qwen technical report, 2023. URL https://arxi v.org/abs/2309.16609.
[5] OpenAI, Josh Achiam, Steven Adler, and et al. Gpt-4 technical report, 2024. URL https: //arxiv.org/abs/2303.08774.
[6] Ajay Patel, Colin Raffel, and Chris Callison-Burch. Datadreamer: A tool for synthetic data genera tion and reproducible llm workflows. arXiv preprint arXiv:2402.10379, 2024.
[7] Anders Giovanni Møller, Jacob Aarup Dalsgaard, Arianna Pera, and Luca Maria Aiello. The parrot dilemma: Human-labeled vs. llm-augmented data in classification tasks. arXiv preprint arXiv:2304.13861, 2023.
[8] Jeiyoon Park, Chanjun Park, and Heuiseok Lim. Chatlang-8: An llm-based synthetic data generation framework for grammatical error correction. arXiv preprint arXiv:2406.03202, 2024.
[9] Hao Liang, Linzhuang Sun, Jingxuan Wei, Xijie Huang, Linkun Sun, Bihui Yu, Conghui He, and Wentao Zhang. Synth-empathy: Towards high-quality synthetic empathy data. arXiv preprint arXiv:2407.21669, 2024.
[10] Oscar Giles, Kasra Hosseini, Grigorios Mingas, Oliver Strickson, Louise Bowler, Camila Rangel Smith, Harrison Wilde, Jen Ning Lim, Bilal Mateen, Kasun Amarasinghe, et al. Faking feature importance: A cautionary tale on the use of differentially-private synthetic data. arXiv preprint arXiv:2203.01363, 2022.
[11] Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, and Haobo Wang. On llms-driven synthetic data generation, curation, and evaluation: A survey, 2024. URL https: //arxiv.org/abs/2406.15126.
理论要掌握,实操不能落!以上关于《大模型合成数据机理分析,人大刘勇团队:信息增益影响泛化能力》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习