高效评估多模态预训练对齐质量,中科大提出模态融合率MIR
来源:机器之心
时间:2024-11-26 20:51:43 471浏览 收藏
哈喽!今天心血来潮给大家带来了《高效评估多模态预训练对齐质量,中科大提出模态融合率MIR》,想必大家应该对科技周边都不陌生吧,那么阅读本文就都不会很困难,以下内容主要涉及到,若是你正在学习科技周边,千万别错过这篇文章~希望能帮助到你!

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者来自于中国科学技术大学,上海人工智能实验室以及香港中文大学。其中第一作者黄启栋为中国科学技术大学三年级博士生,主要研究方向包括多模态大模型(MLLM)和可信 / 高效 AI,师从张卫明教授。
是否还在苦恼如何评估自己预训练好的多模态 LLM 的性能?是否还在使用并不靠谱的损失 Loss,困惑度 Perplexity(PPL),上下文 In-Context 评估,亦或是一遍遍地通过有监督微调(SFT)之后下游测试基准的分数来判断自己的预训练是否有效?
来自中科大等单位的研究团队共同提出了用来有效评估多模态大模型预训练质量的评估指标 Modality Integration Rate(MIR),能够快速准确地评估多模态预训练的模态对齐程度。

标题:Deciphering Cross-Modal Alignment in Large Vision-Language Models with Modality Integration Rate
论文:https://arxiv.org/abs/2410.07167
代码:https://github.com/shikiw/Modality-Integration-Rate
研究背景
预训练(Pre-training)是现有多模态大模型(MLLM)在训练过程中一个不可或缺的阶段。不同于大型语言模型(LLM)的预训练,多模态预训练的主要目标聚焦于不同模态之间的对齐。随着近两年的发展,多模态预训练已经从轻量级图像 - 文本对的对齐,发展为基于广泛多样的多模态数据进行深层次模态集成,旨在构建更通用的多模态大模型。
然而,多模态预训练的评估对于业界仍然是一个未被充分解决的挑战。现有最常用的评估手段为通过进一步的有监督微调(SFT)来测试在下游基准上的模型能力,但是其伴随的计算成本和复杂性不容忽视。另外有一些方法通过借用 LLM 的预训练评估指标,包括损失值 Loss、困惑度 PPL 和上下文 In-Context 评估等方式,在多模态预训练评估中都被证明是不稳定和不可靠的。
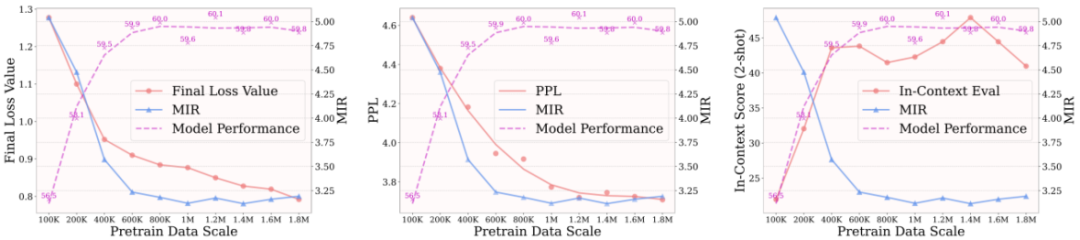
研究者们通过在不同规模的高质量预训练数据上预训练 LLaVA-v1.5 的 7B 模型,用上述不同的方法评估其预训练质量,并与有监督微调之后在下游测试基准上的得分进行对照。如下图所示,损失值 Loss、困惑度 PPL、以及上下文 In-Context 评估都无法准确的对应 SFT 之后在下游测试基准上的模型性能,而本文提出的模态融合率 MIR 则能完美对应。
实际上,PPL 等指标的不适用主要由于 LLM 与 MLLM 在预训练目标上的差异。LLM 预训练主要学习建模语言的基本模式,而 MLLM 预训练则侧重于缩小不同模态之间的差距。如果用多个不同来源的图像和文本数据,并在 LLaVA-v1.5 的大模型输入层去可视化它们的特征分布,会发现尽管图像或文本内容多样,但在每种模态内,它们的分布相对均匀,而模态之间则存在明显的分布差距,如下图(左)所示。
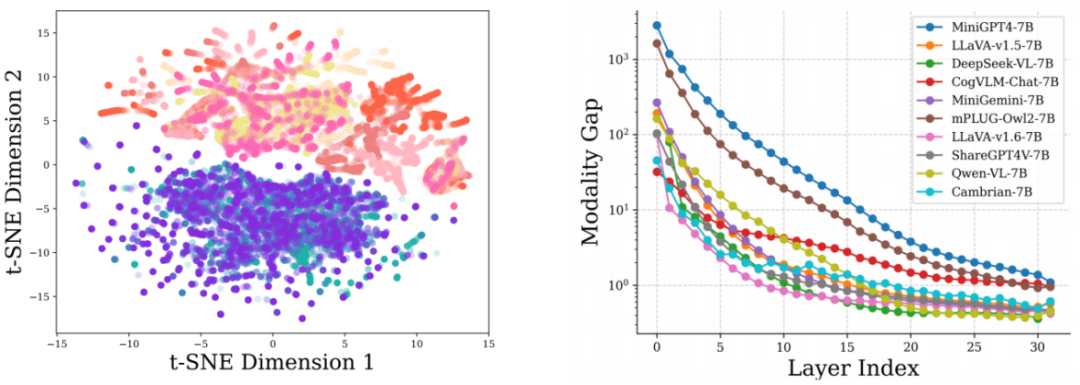
如上图(右)所示,通过进一步计算现有 MLLM 的在大模型不同层中的模态差距,会观察到浅层的时候仍然有较大差距,但当到越来越深的层,这一差距逐渐缩小,这表明 MLLM 在训练过程中仍需要学习对齐不同分布,以理解新引入的模态。
技术方案
本文提出模态融合率 MIR,能够用于评估多模态预训练的跨模态对齐质量。该指标能准确反映各种预训练配置(如数据、策略、训练配方和架构选择)对模型性能的影响,而无需再进行有监督微调 SFT 并于下游测试基准上评估。
对于一个预训练的多模态大模型 M = (E, P, D),其中 E 表示视觉编码器,P 表示视觉语言映射模块,D = (D_t, F) 表示包含分词器 D_t 和 K 层 transformer 的底座大模型 F。当输入一组 “图像 - 文本” 对 {v_n, t_n}, n = 1,..., N 给模型,会从大模型第 k 层 F_k 得到该层关于数据对 {v_n, t_n} 的视觉 token 特征 f_k^{v_n} 和文本 token 特征 f_k^{t_n},即
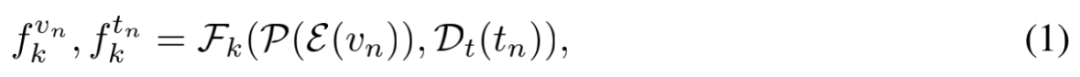
研究者们将多个样本的特征 f_k^{v_n} 合并到一起得到 f_k^v,同理 f_k^{t_n} 可以合并得到 f_k^t,并且定义 f_{k, i}^v 为第 i 个视觉 token 特征,f_{k, j}^t 为第 j 个语言 token 特征。
文本中心归一化
由于越深层的 token 特征在数值绝对尺度上明显比浅层的大,并且不同模态特征间在绝对尺度上存在差异,直接使用 Frechet 距离等度量函数、或是把所有 token 特征统一归一化后再使用度量函数都是不合适的。为此,研究者们设计了一种文本中心的归一化方法,对于 f_k^t 中的总共 s 个文本 token 特征,计算尺度因子:

然后对第 k 层对应的视觉特征和文本特征都使用该因子进行放缩,在保证跨层对比合理性的同时,保持模态间绝对尺度带来的差异。
离群值筛除
许多工作如 StreamLLM [1]、Massive Activations [2] 都提到,有极少部分绝对数值异常大的 token 会用来在注意力模块的 SoftMax 计算中使总和填充到 1。为了避免此类离群值对整体统计分布的影响,这里使用 “3-sigma” 的准则对于所有 f_k^v 和 f_k^t 中的离群值进行筛除。以下用 omega 表示这个操作。
模态融合率
在经过文本中心归一化以及离群 token 筛除之后,模态融合率 MIR 可以通过累和大模型逐层的模态域间距离来得到:
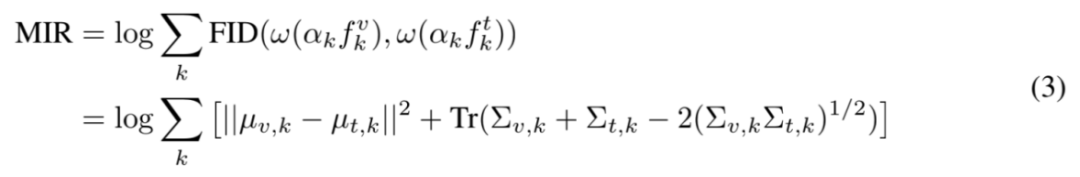
其中,mu_{v, k} 和 mu_{t, k} 分别是处理后视觉 token 特征和文本 token 特征的均值,而
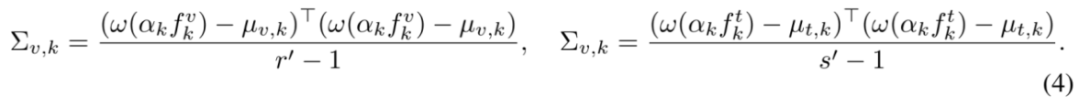
对应于各自的协方差计算。最后的平方根项通常在 PyTorch 中计算缓慢,这是由于大模型的特征维度普遍较高。因此研究者们使用 Newton-Schulz 迭代近似的方式估计该项,在大大提高计算速度的同时,保证实践中误差不超过 1%。总体上来看,越低的 MIR 代表着越高的预训练模态对齐质量。
可学习模态校准
在对 MIR 的探究推导过程中,证明了底座大模型在训练过程中展现出的在浅层逐渐缩小模态间差距的倾向。这促使研究者们重新思考多模态大模型中一些继承自大型语言模型的设计是否不利于促进跨模态对齐。为此,研究者们提出了 MoCa,一个可插拔轻量级的可学习模块,来促进跨模态对齐。简单来说,即对于每一层的视觉 token 特征单独进行一个可学习的缩放和偏移:

其中缩放向量 u 初始化为全一向量,偏移向量 v 初始化为全 0 向量,两者随着模型一起训练,但是基本不增加额外参数量。
实验探究
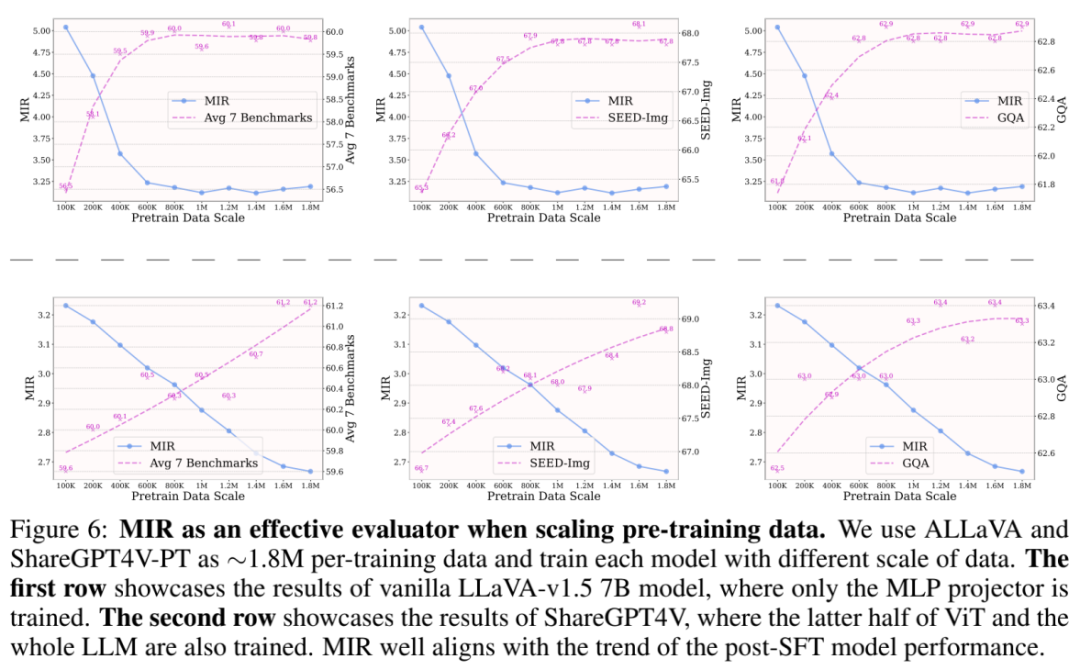
研究者们首先展示了 MIR 在在扩大预训练数据规模时衡量预训练质量的有效性。这里采用两种预训练策略:1) 仅训练 MLP 投影模块;2) 解锁视觉编码器后半部分和整个 LLM。在第一种策略下,SFT 后的性能在 800K∼1M 数据规模时逐渐改善但趋于饱和。而在使用第二种策略时,即使在 1.8M 数据规模下,性能仍持续显著提升。该结果说明了了 MIR 在扩大预训练数据时的有效性,也说明了适当地放开视觉编码器或 LLM 在大规模数据上有持续改善预训练的效果。
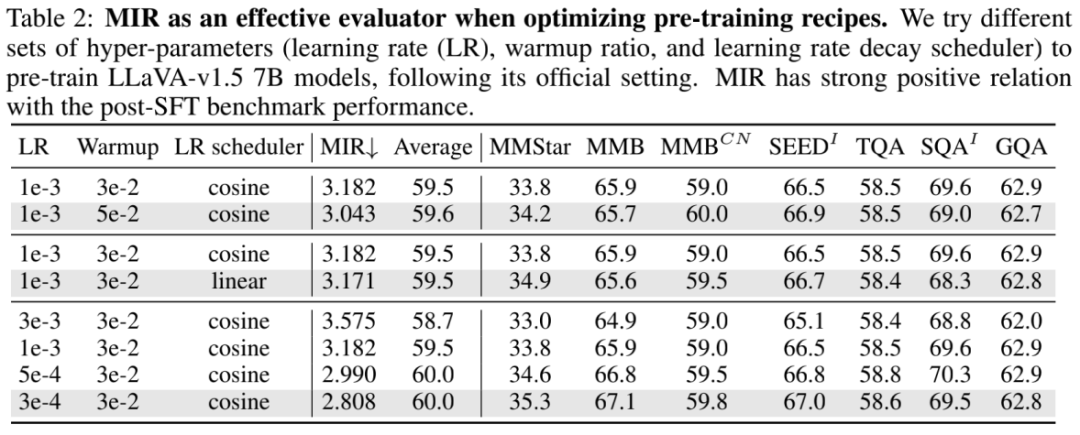
研究者们也探究了 MIR 在超参数调整、预训练策略选择上的有效性。在超参数调整方面,研究者们发现 MIR 与 SFT 后下游测试基准性能之间存在正相关,这说明 MIR 直接反映不同训练超参数对于在预训练质量的影响,以后对照 MIR 就可以实现预训练调参炼丹!
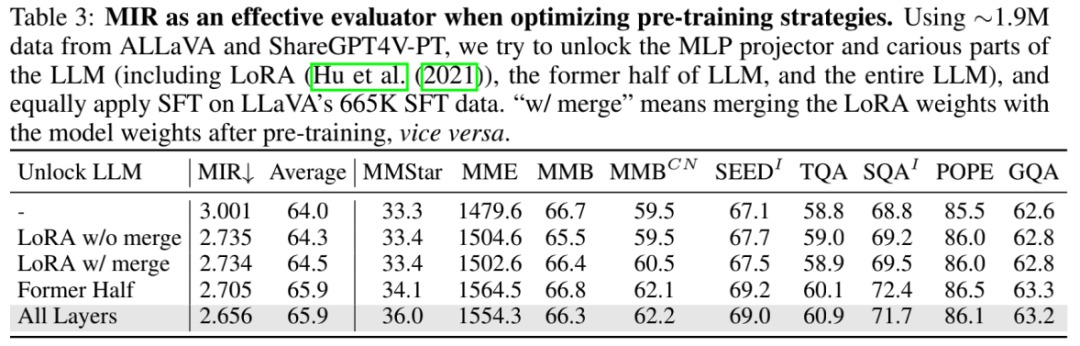
在训练策略方面,研究者们探讨了 MIR 如何指导选择有效的预训练放开策略。结果显示,放开 LLM 显著降低了 MIR,且显著增强下游基准上的表现。
同时,MIR 也可以帮助选择一些有利于跨模态对齐的模块设计。如下图所示,当使用不同的视觉语言投影模块结构时,MIR 可以很准确的对应到 SFT 之后的测试基准性能。
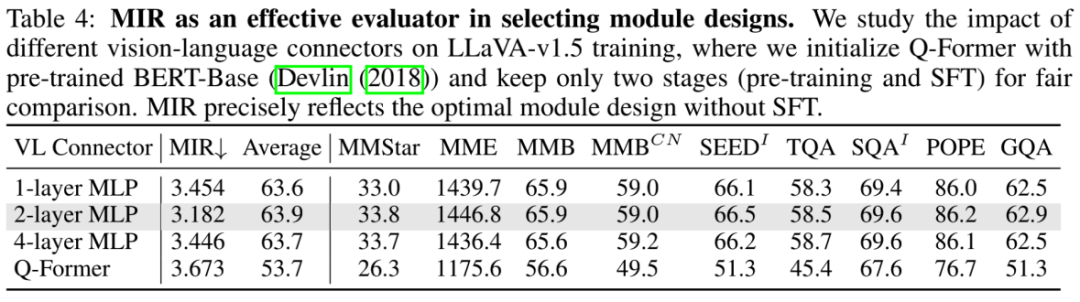
同样,所提出的可学习模态校准 MoCa 也可以有效帮助不同模型在下游测试基准上涨点,并取得更低的 MIR。
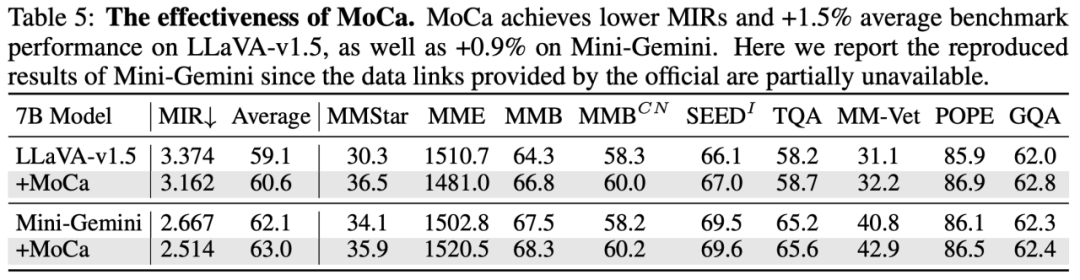
本文仍有较多其他方面的实验和探索,有兴趣的同学可以参考原文!
参考文献:
[1] Xiao et al. Efficient Streaming Language Models with Attention Sinks. ICLR, 2024.
[2] Sun et al. Massive Activations in Large Language Models. COLM, 2024.
好了,本文到此结束,带大家了解了《高效评估多模态预训练对齐质量,中科大提出模态融合率MIR》,希望本文对你有所帮助!关注golang学习网公众号,给大家分享更多科技周边知识!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
科技周边 · 人工智能 | 1小时前 | 前端 · 人工智能 · 用户体验 · 可访问性 · 流式输出 · AI对话 AbortController AbortSignal 流式输出 aria-live 停止生成425 收藏
-
468 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · ai agent · AI应用 · 工具调用 · 权限边界 · 审计链路 · 人工智能 权限控制 AI Agent 工具调用 审批链路 审计回放 上线指标343 收藏
-
科技周边 · 人工智能 | 2星期前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计427 收藏
-
154 收藏
-
309 收藏
-
234 收藏
-
科技周边 · 人工智能 | 2星期前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream448 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 4星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习