Redis在大数据中的使用技巧
来源:51cto
时间:2023-01-08 21:01:41 293浏览 收藏
对于一个数据库开发者来说,牢固扎实的基础是十分重要的,golang学习网就来带大家一点点的掌握基础知识点。今天本篇文章带大家了解《Redis在大数据中的使用技巧》,主要介绍了大数据、互联网、IT,希望对大家的知识积累有所帮助,快点收藏起来吧,否则需要时就找不到了!
今天将会跟大家讨论一些Redis在大数据中的使用,包括一些Redis的使用技巧和其他的一些内容。
一、Redis封装架构讲解
实际上NewLife.Redis是一个完整的Redis协议功能的实现,但是Redis的核心功能并没有在这里面,而是在NewLife.Core里面。
这里可以打开看一下,NewLife.Core里面有一个NewLife.Caching的命名空间,里面有一个Redis类,里面实现了Redis的基本功能;另一个类是RedisClient是Redis的客户端。
Redis的核心功能就是有这两个类实现,RedisClient代表着Redis客户端对服务器的一个连接。Redis真正使用的时候有一个Redis连接池,里面存放着很多个RedisClient对象。
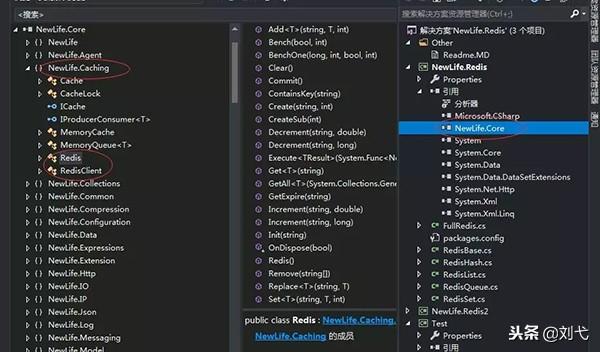
所以我们Redis的封装有两层,一层是NewLife.Core里面的Redis以及RedisClient;另一层就是NewLife.Redis。这里面的FullRedis是对Redis的实现了Redis的所有的高级功能。
这里你也可以认为NewLife.Redis是Redis的一个扩展。
二、Test实例讲解Redis的基本使用
1、实例
打开Program.cs看下代码:
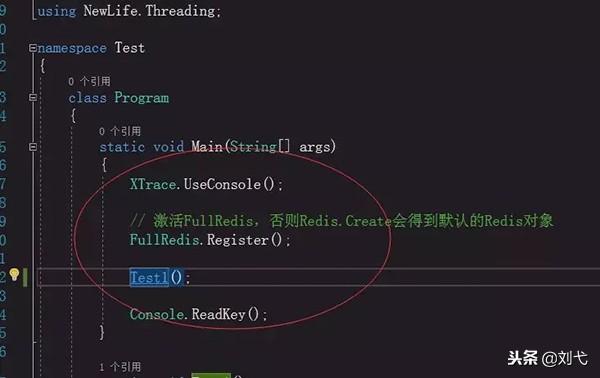
这里XTrace.UseConsole();是向控制台输出日志,方便调试使用查看结果。
接下来看***个例子Test1,具体的我都在代码中进行了注释,大家可以看下:

- Set的时候,如果是字符串或者字符数据的话,Redis会直接保存起来(字符串内部机制也是保存二进制),如果是其他类型,会默认进行json序列化然后再保存起来。
- Get的时候,如果是字符串或者字符数据会直接获取,如果是其他类型会进行json反序列化。
- Set第三个参数过期时间单位是秒。
- vs调试小技巧,按F5或者直接工具栏“启动”会编译整个解决方案会很慢(VS默认),可以选中项目然后右键菜单选择调试->启动新实例,会只编译将会用到的项目,这样对调试来说会快很多。
- 大家运行调试后可以看到控制台输出的内容:向右的箭头=》是ic.Log=XTrace.Log输出的日志。
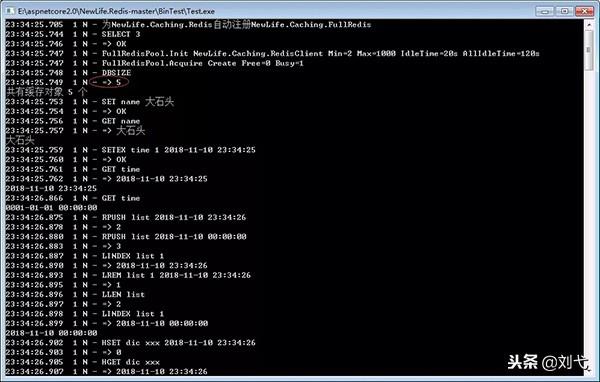
- 字典的使用:对象的话,需要把json全部取出来,然后转换成对象,而字典的话,就可以直接取某个字段。
- 队列是List结构实现的,上游数据太多,下游处理不过来的时候,就可以使用这个队列。上游的数据发到队列,然后下游慢慢的消费。另一个应用,跨语言的协同工作,比方说其他语言实现的程序往队列里面塞数据,然后另一种语言来进行消费处理。这种方式类似MQ的概念,虽然有点low,但是也很好用。
- 集合,用的比较多的是用在一个需要精确判断的去重功能。像我们每天有三千万订单,这三千万订单可以有重复。这时候我想统计下一共有订单,这时候直接数据库group by是不大可能的,因为数据库中分了十几张表,这里分享个实战经验:
- 比方说揽收,商家发货了,网点要把件收回来,但是收回来之前网点不知道自己有多少货,这时候我们做了一个功能,也就是订单会发送到我们公司来。我们会建一个time_site的key的集合,而且集合本身有去重的功能,而且我们可以很方便的通过set.Count功能来统计数量,当件被揽收以后,我们后台把这个件从集合中Remove掉。然后这个Set中存在的就是网点还没有揽收的件,这时候通过Count就会知道这个网点今天还有多少件没有揽收。实际使用中这个数量比较大,因为有几万个网点。
- Redis中布隆过滤器,去重的,面试的时候问的比较多。
小经验分享:
- 数据库中不合法的时间处理:判断时间中的年份是否大于2000年,如果小于2000就认为不合法;习惯大于小于号不习惯用等于号,这样可以处理很多意外的数据;
- Set的时候***指定过期时间,防止有些需要删除的数据我们忘记删了;
- Redis异步尽量不用,因为Redis延迟本身很小,大概在100us-200us,再一个就是Redis本身是单线程的,异步任务切换的耗时比网络耗时还要大;
- List用法:物联网中数据上传,量比较大时,我们可以把这些数据先放在Redis的List中,比如说一秒钟1万条,然后再批量取出来然后批量插入数据库中。这时候要设置好key,可以前缀+时间,对已处理的List可以进行remove移除。
2、压力测试
接下来看第四个例子,我们直接做压力测试,代码如下:
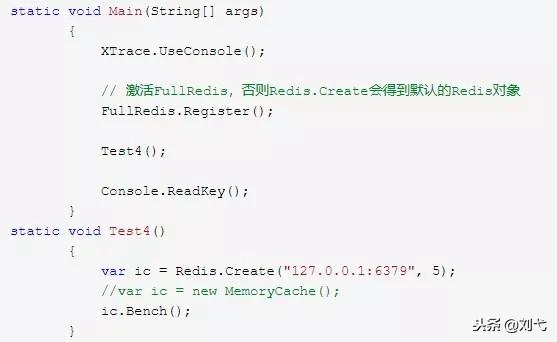
运行的结果如下图所示:
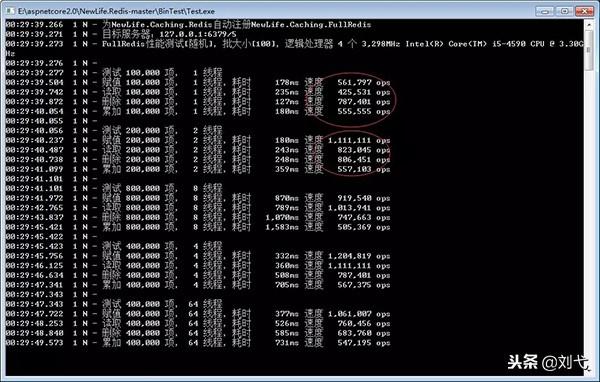
测试就是进行get,set remove,累加等的操作。大家可以看到在我本机上轻轻松松的到了六十万,多线程的时候甚至到了一百多万。
为什么会达到这么高的Ops呢?下面给大家说一下:
- Bench会分根据线程数分多组进行添删改压力测试;
- rand参数,是否随机产生key/value;
- batch批大小,分批执行读写操作,借助GetAll/SetAll进行优化。
3、Redis中NB的函数来提升性能
上面的操作如果大家都掌握了就基本算Redis入门了,接下来进行进阶。如果能全然吃透,差不多就会比别人更胜一筹了。
GetAll()与SetAll()
GetAll:比方说我要取十个key,这个时候可以用getall。这时候Redis就执行了一次命令。比方说我要取10个key那么用get的话要取10次,如果用getall的话要用1次。1次getall时间大概是get的一点几倍,但是10次get的话就是10倍的时间,这个账你应该会算吧?强烈推荐大家用getall。
setall跟getall相似,批量设置K-V。
setall与getall性能很恐怖,官方公布的Ops也就10万左右,为什么我们的测试轻轻松松到五十万甚至上百万?因为我们就用了setall,getall。如果get,set两次以上,建议用getall,setall。
Redis管道Pipeline
比如执行10次命令会打包成一个包集体发过去执行,这里实现的方式是StartPipeline()开始,StopPipeline()结束中间的代码就会以管道的形式执行。
这里推荐使用更强的武器,AutoPipeline自动管道属性。管道操作到一定数量时,自动提交,默认0。使用了AutoPipeline,就不需要StartPipeline,StopPipeline指定管道的开始结束了。
Add与Replace
- Add:Redis中没有这个Key就添加,有了就不要添加,返回false;
- Replace:有则替换,还会返回原来的值,没有则不进行操作。
Add跟Replace就是实现Redis分布式锁的关键。
三、Redis使用技巧,经验分享
在项目的Readme中,这里摘录下:
1、特性
- 在ZTO大数据实时计算广泛应用,200多个Redis实例稳定工作一年多,每天处理近1亿包裹数据,日均调用量80亿次;
- 低延迟,Get/Set操作平均耗时200~600us(含往返网络通信);
- 大吞吐,自带连接池,***支持1000并发;
- 高性能,支持二进制序列化(默认用的json,json很低效,转成二进制性能会提升很多)。
2、Redis经验分享
- 在Linux上多实例部署,实例个数等于处理器个数,各实例***内存直接为本机物理内存,避免单个实例内存撑爆(比方说8核心处理器,那么就部署8个实例)。
- 把海量数据(10亿+)根据key哈希(Crc16/Crc32)存放在多个实例上,读写性能成倍增长。
- 采用二进制序列化,而非常见的Json序列化。
- 合理设计每一对Key的Value大小,包括但不限于使用批量获取,原则是让每次网络包控制在1.4k字节附近,减少通信次数(实际经验几十k,几百k也是没问题的)。
- Redis客户端的Get/Set操作平均耗时200~600us(含往返网络通信),以此为参考评估网络环境和Redis客户端组件(达不到就看一下网络,序列化方式等等)。
- 使用管道Pipeline合并一批命令。
- Redis的主要性能瓶颈是序列化、网络带宽和内存大小,滥用时处理器也会达到瓶颈。
- 其它可查优化技巧。
以上经验,源自于300多个实例4T以上空间一年多稳定工作的经验,并按照重要程度排了先后顺序,可根据场景需要酌情采用。
3、缓存Redis的兄弟姐妹
Redis实现ICache接口,它的孪生兄弟MemoryCache,内存缓存,***吞吐率。
各应用强烈建议使用ICache接口编码设计,小数据时使用MemoryCache实现;数据增大(10万)以后,改用Redis实现,不需要修改业务代码。
四、关于一些疑问的回复
这一Part我们会来聊聊大数据中Redis使用的经验:
Q1:一条数据多个key怎么设置比较合理?
A1:如果对性能要求不是很高直接用json序列化实体就好,没必要使用字典进行存储。
Q2:队列跟List有什么区别?左进右出的话用List还是用队列比较好?
A2:队列其实就是用List实现的,也是基于List封装的。左进右出的话直接队列就好。Redis的List结构比较有意思,既可以左进右出,也能右进左出。所以它既可以实现列表结构,也能队列,还能实现栈。
Q3:存放多个字段的类性能一样吗?
A3:大部分场景都不会有偏差,可能对于大公司数据量比较大的场景会有些偏差。
Q4:大数据写入到数据库之后,比如数据到亿以上的时候,统计分析、查询这块,能不能分享些经验。
A4:分表分库,拆分到一千万以内。
Q5:CPU为何暴涨?
A5:程序员***理念——CPU达到***,然后性能达到***,尽量不要浪费。最痛恨的是——如果CPU不到***,性能没法提升了,说明代码有问题。
虽然Redis大家会用,但是我们可能平时不会有像这样的大数据使用场景。希望本文能够给大家一些值得借鉴的经验。
今天带大家了解了大数据、互联网、IT的相关知识,希望对你有所帮助;关于数据库的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
217 收藏
-
263 收藏
-
282 收藏
-
204 收藏
-
258 收藏
-
422 收藏
-
326 收藏
-
494 收藏
-
数据库 · Redis | 1天前 | Redis · 缓存 · 限流 · Redis 8.8 · INCREX · Redis 8.8 INCREX Redis窗口限流 Redis计数器 ENX UBOUND123 收藏
-
数据库 · Redis | 3天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT259 收藏
-
183 收藏
-
413 收藏
-
数据库 · Redis | 5天前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计364 收藏
-
250 收藏
-
110 收藏
-
366 收藏
-
449 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 受伤的冬瓜
- 这篇技术文章真是及时雨啊,太细致了,感谢大佬分享,码住,关注楼主了!希望楼主能多写数据库相关的文章。
- 2023-01-21 09:08:03
-
- 傻傻的玫瑰
- 太细致了,mark,感谢老哥的这篇博文,我会继续支持!
- 2023-01-21 07:35:58
-
- 香蕉月饼
- 真优秀,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢up主分享技术文章!
- 2023-01-19 11:36:23