把RLHF带给VLA模型!通过偏好对齐来优化机器人策略,代码已开源
时间:2025-01-01 11:19:13 434浏览 收藏
哈喽!大家好,很高兴又见面了,我是golang学习网的一名作者,今天由我给大家带来一篇《把RLHF带给VLA模型!通过偏好对齐来优化机器人策略,代码已开源》,本文主要会讲到等等知识点,希望大家一起学习进步,也欢迎大家关注、点赞、收藏、转发! 下面就一起来看看吧!
GRAPE:通过偏好对齐提升机器人策略泛化能力
AIxiv专栏持续报道全球顶尖AI研究成果。本文介绍一篇来自北卡罗来纳大学教堂山分校、华盛顿大学及芝加哥大学的研究,该研究提出了一种名为GRAPE的新算法,显著提升了视觉-语言-动作(VLA)模型的泛化能力。

论文第一作者为北卡罗来纳大学教堂山分校的张子健,指导老师为助理教授Huaxiu Yao。共同第一作者为华盛顿大学的Kaiyuan Zheng。其他作者来自北卡教堂山、华盛顿大学和芝加哥大学。
论文信息:
- 标题: GRAPE: Generalizing Robot Policy via Preference Alignment
- 链接: https://arxiv.org/abs/2411.19309
- 项目地址: https://grape-vla.github.io
- 代码地址: https://github.com/aiming-lab/GRAPE
研究挑战与GRAPE的解决方案
现有的VLA模型在机器人任务中的泛化能力有限,主要原因在于它们依赖于成功的执行轨迹进行行为克隆,难以应对新任务和环境变化。 GRAPE算法通过偏好对齐来解决这个问题,其核心思想是将VLA模型与预设目标对齐,从而提升其泛化能力。
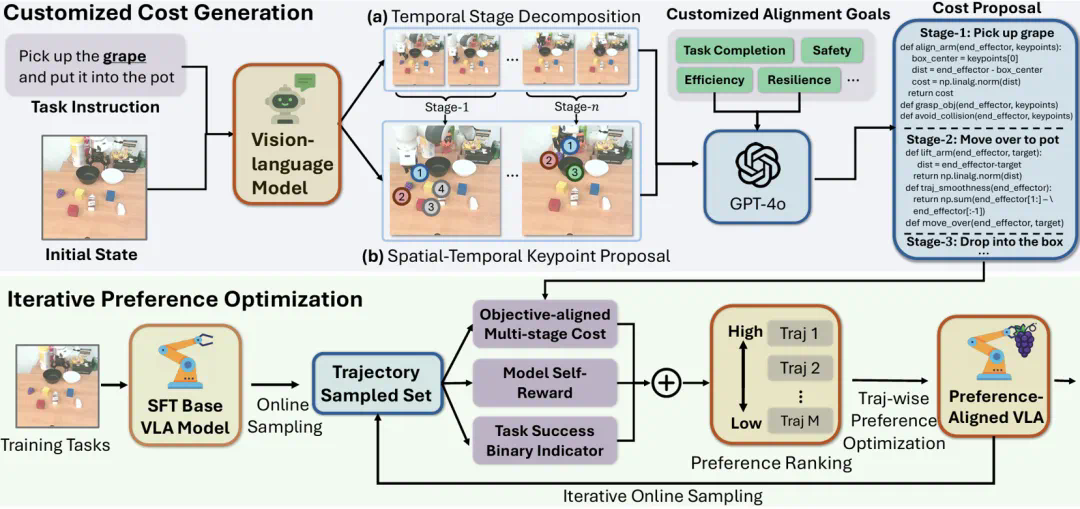
GRAPE具有三大优势:
- 轨迹级强化学习对齐: GRAPE在轨迹层面使用强化学习目标对VLA模型进行优化,使其能够全局地进行决策,而非简单的行为模仿。
- 隐式奖励建模: GRAPE能够隐式地对成功和失败尝试进行奖励建模,从而增强其对多样化任务目标的适应能力。
- 可扩展的偏好合成: GRAPE采用可扩展的算法合成偏好,能够将VLA模型与任意目标(如效率、安全性、任务完成度)对齐。
算法核心模块
GRAPE由三个核心模块构成:
-
轨迹级偏好优化 (Trajectory-wise Preference Optimization, TPO): 通过改进的DPO损失函数(TPO_Loss),根据优劣轨迹样本进行训练,实现轨迹级别的偏好对齐。
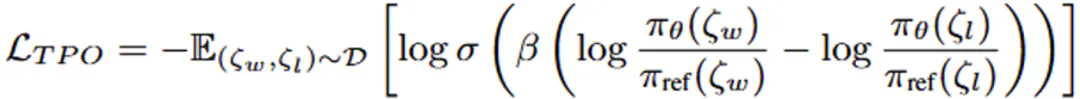
-
定制化偏好合成 (Customized Preference Synthesis): 针对复杂任务缺乏明确奖励模型的问题,GRAPE通过大型视觉-语言模型分解任务阶段,并自动引导偏好建模过程,实现对不同目标的定制化对齐。
-
迭代式在线对齐 (Iterative Online Alignment): 通过迭代的在线样本采集、偏好排序和轨迹级偏好优化,逐步提升VLA策略的泛化能力和目标对齐程度。
实验结果与结论
GRAPE在真实机器人和仿真环境下均进行了测试,结果表明其在各种分布外泛化任务(包括视觉、物体、动作、语义和空间位置变化)上显著优于现有最先进的OpenVLA-SFT模型。 此外,GRAPE还能有效地将机器人策略与安全性、效率等目标对齐,例如降低碰撞率或缩短执行时间。
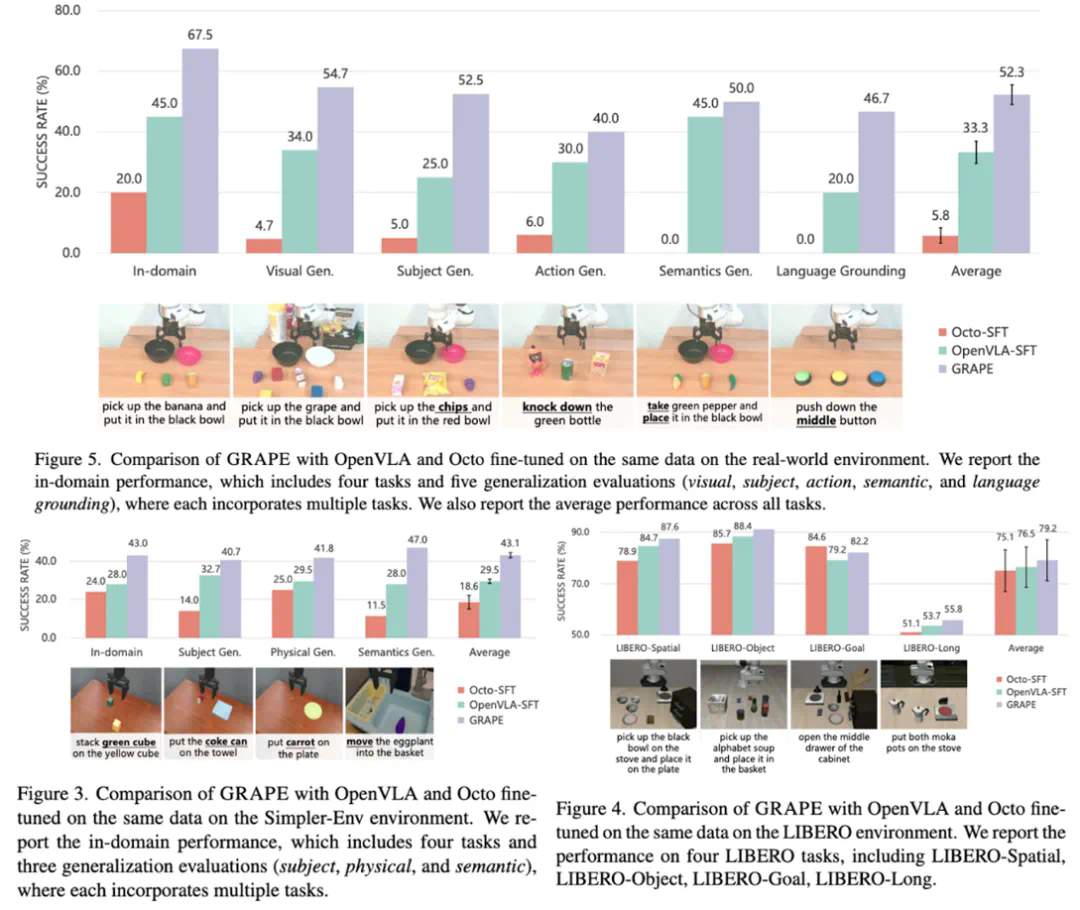
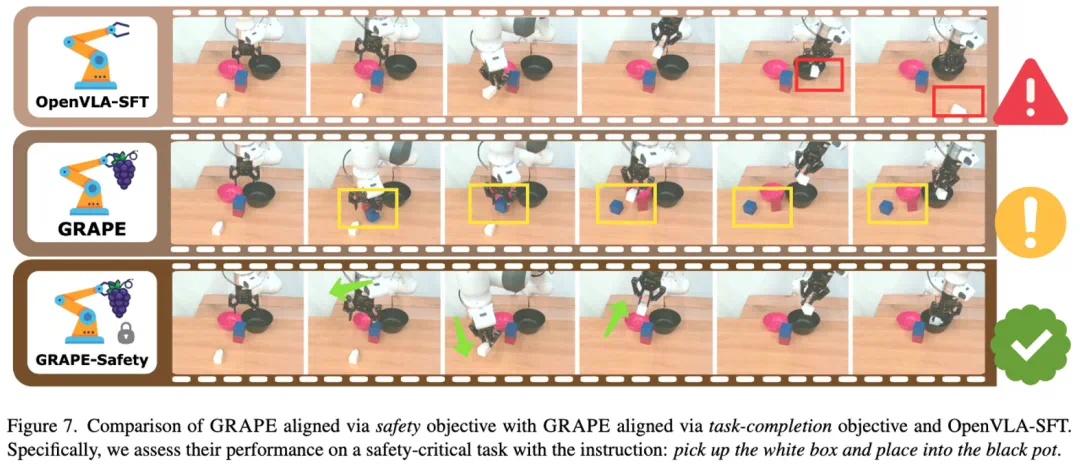
GRAPE为提升VLA模型的泛化能力提供了一种有效的方法,其即插即用的特性使其在各种机器人任务中具有广泛的应用前景。
今天关于《把RLHF带给VLA模型!通过偏好对齐来优化机器人策略,代码已开源》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习