更快、更强!地平线ViG,基于视觉Mamba的通用视觉主干网络
时间:2025-01-12 20:54:51 412浏览 收藏
本篇文章给大家分享《更快、更强!地平线ViG,基于视觉Mamba的通用视觉主干网络》,覆盖了科技周边的常见基础知识,其实一个语言的全部知识点一篇文章是不可能说完的,但希望通过这些问题,让读者对自己的掌握程度有一定的认识(B 数),从而弥补自己的不足,更好的掌握它。
ViG:高效且可扩展的视觉骨干网络
论文链接: https://arxiv.org/abs/2405.18425
成果: 本工作已被AAAI 2025收录。
Vision Mamba的成功证明了将视觉表征学习转化为线性复杂度视觉序列建模的巨大潜力。然而,即使像Vision Mamba这样的线性视觉序列建模方法在高清图像上效率显著提升,但在更常见的分辨率下,其性能仍略逊于Transformer和CNN。
为了进一步提升线性复杂度视觉序列建模的效率,我们针对现代计算设备的硬件特性,设计了一种新型模型——ViG。ViG将自然语言处理中高效的门控线性注意力模块(Gated Linear Attention, GLA)引入视觉表征学习,并结合参数高效的双向建模、长短上下文动态门控机制以及硬件感知的双向算子设计。最终,ViG在各种视觉任务上,在精度、参数量和效率方面均超越了主流的Transformer和CNN模型。
技术背景
Transformer的自注意力(Self-Attention, SA)机制需要处理所有历史输入之间的交互,导致计算复杂度随输入序列长度呈二次方增长:
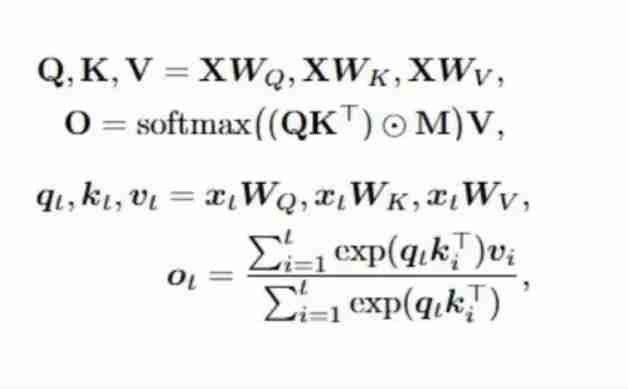
线性注意力(Linear Attention, LA)机制通过将softmax算子替换为简单的矩阵乘法,利用矩阵乘法的结合律,预先计算KV,从而将计算复杂度降低为线性:
线性门控注意力(Gated Linear Attention, GLA)机制进一步引入门控机制,控制对历史信息的遗忘和更新,提升了线性注意力机制的表达能力:
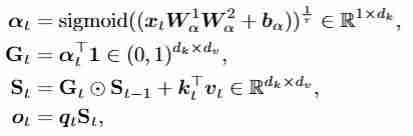
方法概述
双向门控注意力机制 (BiGLA):
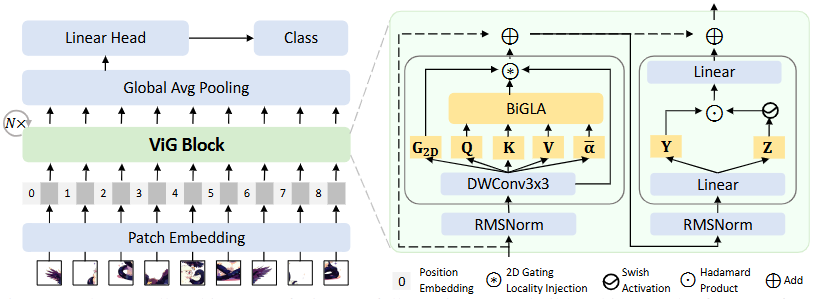
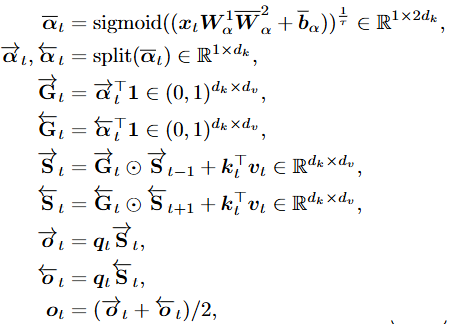
图片作为二维信号,在一维序列表示上具有多向特性。我们改进GLA,仅引入双向门控机制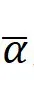 ,显著提升了对视觉信号的空间表达能力。BiGLA算子将前向和反向视觉序列压缩到固定大小的隐状态
,显著提升了对视觉信号的空间表达能力。BiGLA算子将前向和反向视觉序列压缩到固定大小的隐状态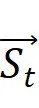 和
和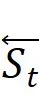 。
。
硬件感知的双向算子设计:
为了进一步提升效率,我们设计了一个硬件感知的双向实现,将BiGLA的前向和反向扫描合并到一个Triton算子中。这种设计避免了反向序列的实例化,只需维护单向视觉序列即可进行多向扫描和融合,显著降低了显存占用并提升了硬件运行速度。
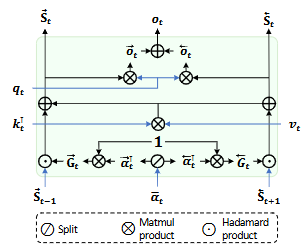
长短上下文动态门控机制:
BiGLA算子中的双向隐状态和进行长上下文全局压缩。为了增强对图像二维空间细节的感知,我们引入了短上下文卷积门控设计:
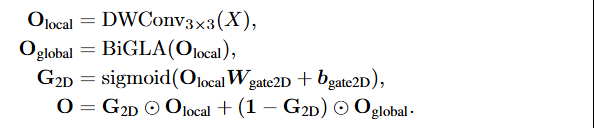
模型结构:
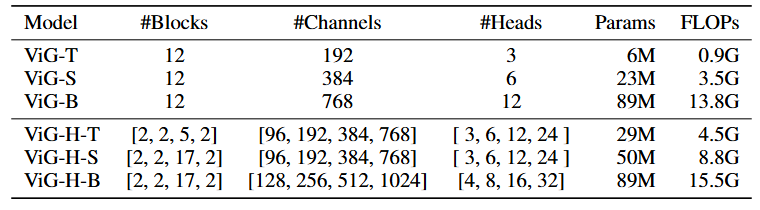
基于上述ViG模块,我们构建了两种结构变体:类似Vision Transformer的简单直筒结构ViG和类似CNN的层次化金字塔结构ViG-H。
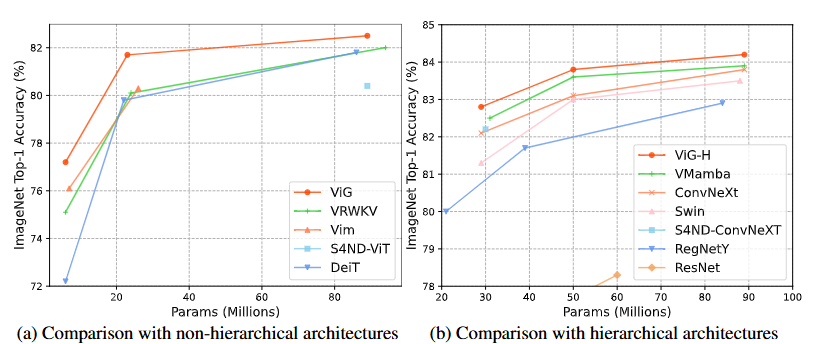
实验结果
实验结果表明,ViG和ViG-H在参数量和精度的权衡上优于先进的Transformer和CNN模型。ViG基础模块同时具备全局感受野和线性复杂度,这是传统CNN、基于原始注意力机制的Transformer和基于窗口化注意力机制的Transformer无法实现的。
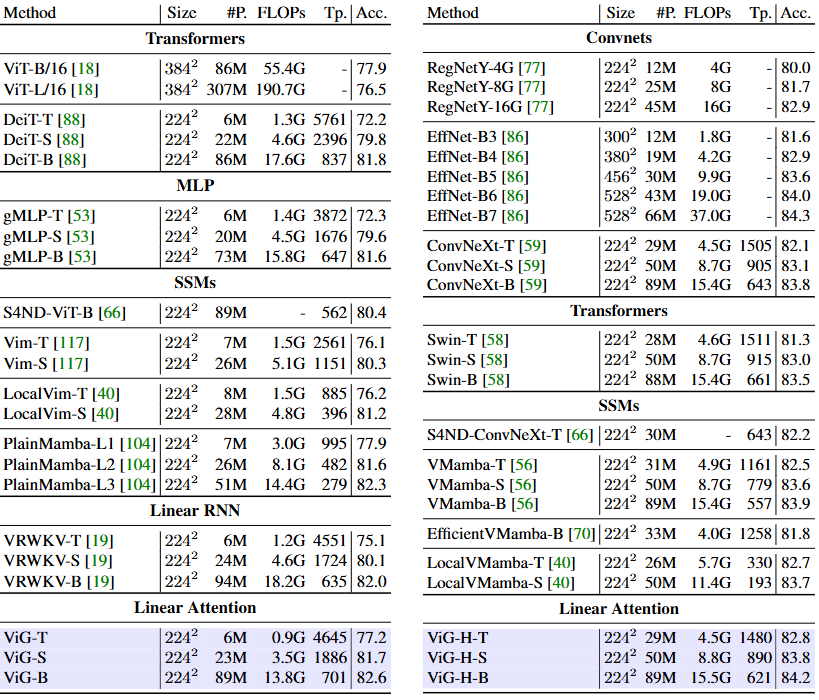
在高分辨率图像(1024x1024)上,ViG展现出显著的优势:计算量降低5.2倍,GPU显存节省90%,速度提升3.8倍,精度提升20.7%。
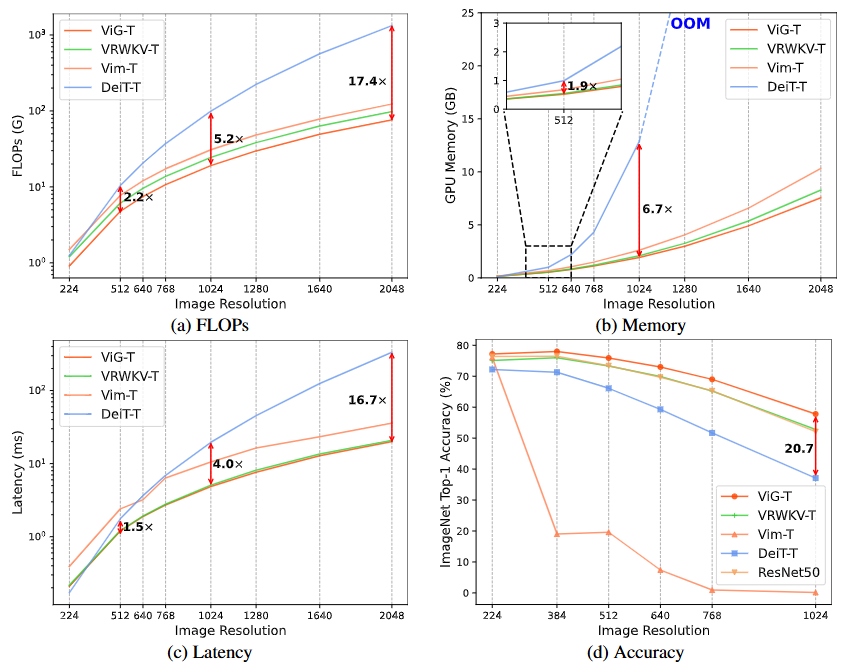
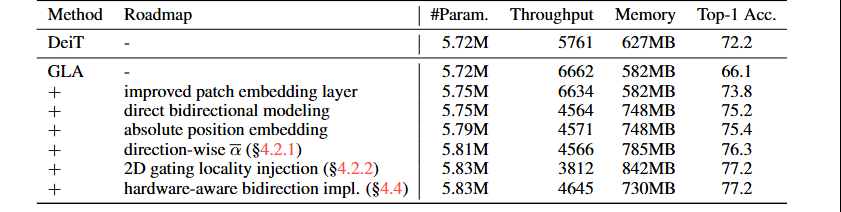
双向设计仅增加了2%的参数量,却带来了11.1%的精度提升;硬件感知实现减少了19%的推理代价和13%的显存占用。
总结与展望
ViG在高效视觉序列建模领域具有重要创新性和应用价值。通过BiGLA和二维门控局部注入机制,ViG有效结合了全局感知能力和局部细节捕获,实现了高效且准确的视觉表征学习。ViG在图像分类、目标检测和语义分割等任务中表现出色,尤其在高分辨率场景下,其性能和资源利用效率显著提升。 其硬件感知优化设计降低了内存占用和计算成本,为高清视觉信号处理和多模态序列建模提供了强有力的技术支撑。
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于科技周边的相关知识,也可关注golang学习网公众号。
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
299 收藏
-
科技周边 · 人工智能 | 1天前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-
419 收藏
-
170 收藏
-
475 收藏
-
科技周边 · 人工智能 | 5天前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK292 收藏
-
379 收藏
-
394 收藏
-
101 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习