视觉 AI 的「Foundation Model」,已经发展到哪一步?丨CVPR 2024 现场直击
时间:2025-01-13 21:18:45 352浏览 收藏
知识点掌握了,还需要不断练习才能熟练运用。下面golang学习网给大家带来一个科技周边开发实战,手把手教大家学习《视觉 AI 的「Foundation Model」,已经发展到哪一步?丨CVPR 2024 现场直击》,在实现功能的过程中也带大家重新温习相关知识点,温故而知新,回头看看说不定又有不一样的感悟!
2024年CVPR:视觉Foundation Model引领AI新浪潮
2024年6月17日至21日,IEEE国际计算机视觉与模式识别会议(CVPR)在美国西雅图举行。今年的CVPR,视觉Foundation Model成为除自动驾驶、3D视觉等传统研究领域外的核心主题,备受瞩目。 受快手“可灵”图生视频功能爆火和Runway Gen-3 Alpha模型发布的影响,“文生视频”也成为一大热点。
CVPR 2024两篇最佳论文均授予AIGC相关研究。论文接收数量方面,图像和视频合成与生成领域以329篇论文位居榜首,而文生视频也属于视觉Foundation Model的研究范畴。事实上,Foundation Model在人工智能领域的早期突破正是在计算机视觉领域。
2021年,斯坦福大学学者发布的Foundation Model综述就涵盖了众多计算机视觉领域专家,但OpenAI在自然语言处理领域的Foundation Model上率先取得领先地位。然而,Sora和“可灵”等技术的惊艳效果,再次将视觉Foundation Model推至研究前沿。
AI科技评论对多位视觉Foundation Model研究者进行了采访,总结出以下关键发现:
- 视觉Foundation Model的研究借鉴了OpenAI的经验,未来的突破方向集中在预测下一个visual token和扩大算力规模等方面;
- 多位研究者认为,Foundation Model的兴起使AI研究转变为“工业生产线”,研究重点转向“数据”和“算力”;
- 多模态成为视觉基础模型研究的热点,但视觉和语言领域间的合作仍有待加强。
除了Foundation Model,采访还涉及自动驾驶和3D视觉领域。 受访者指出,像CVPR这样的学术会议,其论文接收和会议召开时间跨度过长,可能已无法及时反映快速发展的研究成果。 AI研究中,工业界和学术界的界限日益模糊,学术会议也需要适应时代变化。
Foundation Model的瓶颈与突破方向
基于Transformer的通用视觉基础模型并非新兴概念。 微软Swin Transformer、谷歌ViT以及上海人工智能实验室的“书生”(Intern)系列都进行了早期探索,但都被Sora的光芒所掩盖。 Sora的技术路径也为后续研究提供了新的借鉴方向。
上海人工智能实验室的OpenGVLab团队在CVPR 2024上展示了其最新的视觉多模态基础模型InternVL-1.5。该模型凭借强大的视觉编码器InternViT-6B、高动态分辨率和高质量双语数据集,在业内获得高度评价。
OpenGVLab团队认为,视觉基础模型的关键在于构建多模态对话系统。InternVL-26B的研究始于2023年3月,其目标是在保持模型强大性和多功能性的前提下,将其作为对话系统的骨干,支持图像检测、分割以及图文检索等多模态任务。
InternVL-1.5的技术报告指出,视觉基础模型研究的三个关键点是:强大的语言模型支持、高分辨率适配和高质量数据集。 研究人员认为,GPT-4o等模型注重不同模型间的跨模态转换,而InternVL则专注于单个模型内不同模态的输入和文本理解的输出,两者并非相互排斥的路线。
一些研究者提出,视觉基础模型应具备更强的离散化特性,将各个模态转换为离散表示,以实现更统一的多模态处理。 但研究人员也指出,这种方法可能损失关键信息,仍需进一步探索。
思谋科技研究员张岳晨和南洋理工大学副教授张含望也分别就视觉基础模型的瓶颈和突破方向提出了各自的见解,他们都强调了高质量数据的获取、原生多模态支持以及解决“理解”和“生成”任务互斥问题的重要性。 张含望教授特别指出,视觉token的改进是将视觉信息有效接入大语言模型的关键。
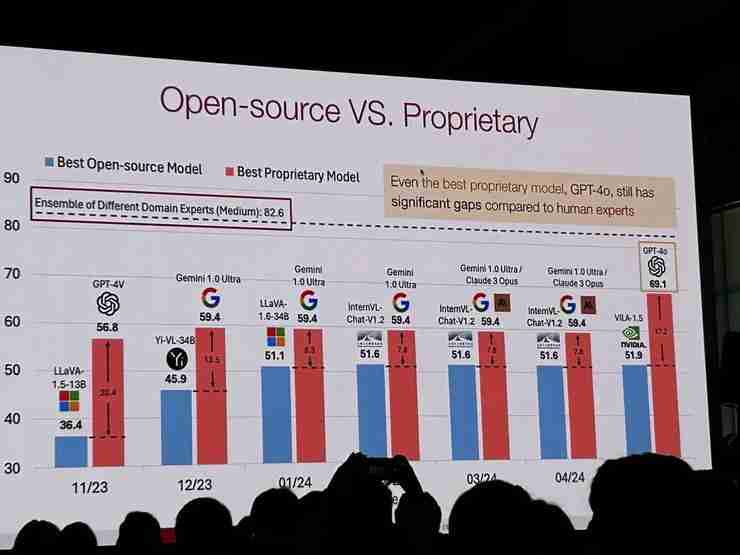
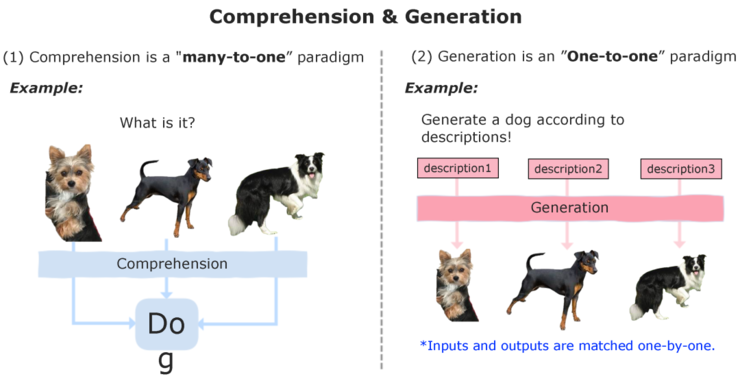
自动驾驶和端侧AI
自动驾驶在CVPR 2024上也占据重要地位,尤其关注将大语言模型应用于自动驾驶场景。 核心挑战在于如何在保证安全性的前提下,让大模型理解环境并预测车辆行驶轨迹。
今年的一个趋势是利用大语言模型为自动驾驶端到端技术提供新的解决方案,例如使用生成式AI构建仿真平台。 CVPR 2024自动驾驶国际挑战赛吸引了众多团队参赛,英伟达联合复旦大学的团队获得了冠军。
英伟达的研究人员介绍了其在端到端自动驾驶中的创新,即在数据量不足的情况下,使用基于规则的专家系统作为教师,将规则知识蒸馏给神经网络规划器。


苹果的多模态LLM模型
苹果公司也在CVPR 2024上展示了其在多模态LLM模型方面的最新研究进展。 苹果的研究人员介绍了如何通过高质量的数据混合和改进的MoE架构来提升多模态大模型的性能。


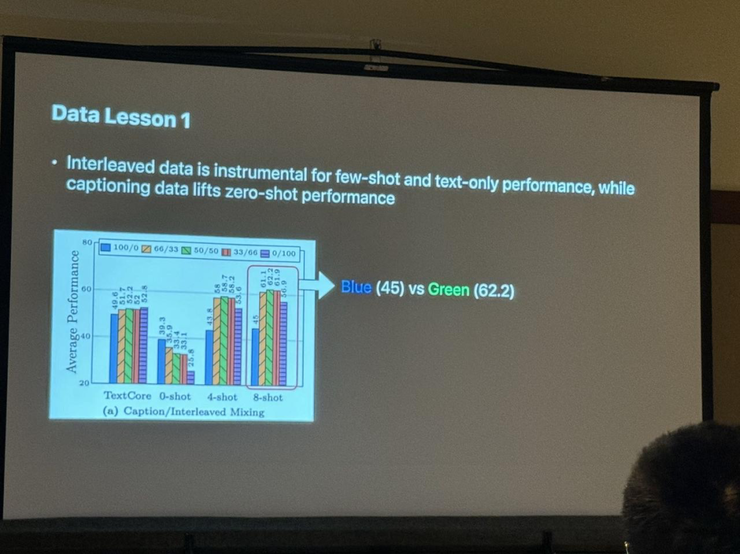
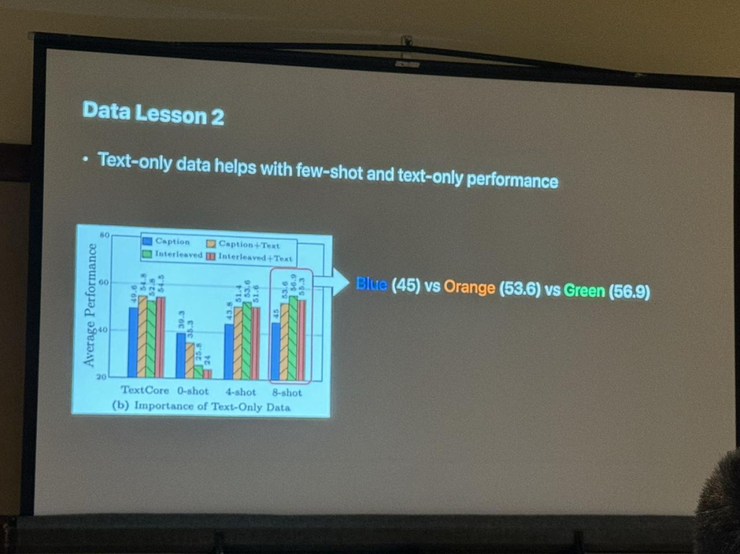
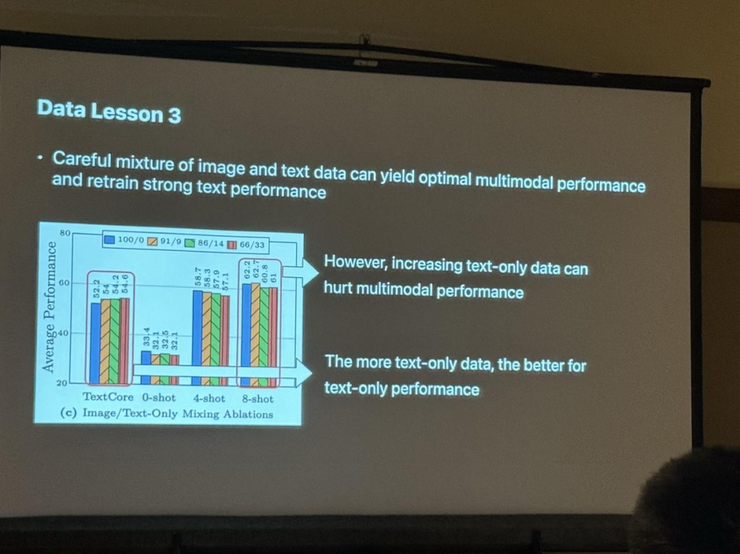
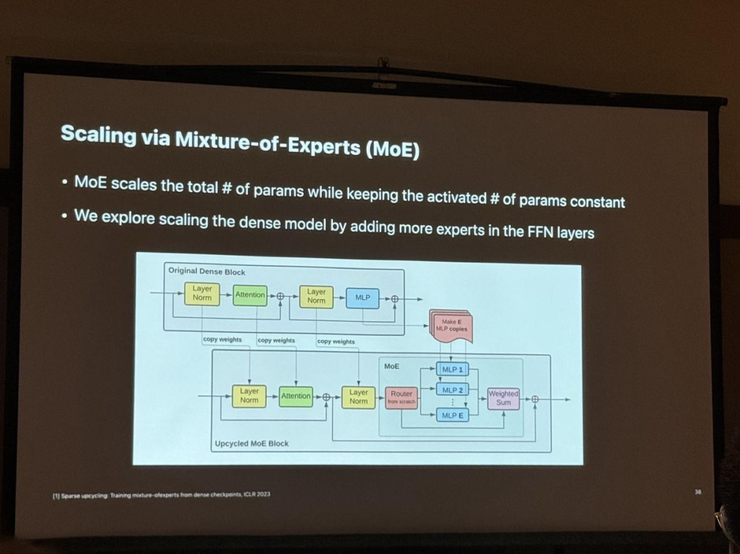
总结
CVPR 2024展现了AIGC技术在计算机视觉领域的蓬勃发展,但也引发了对学术会议适应性以及未来研究方向的思考。 未来,计算机视觉研究可能从虚拟世界转向物理世界,并以多种形式呈现。
理论要掌握,实操不能落!以上关于《视觉 AI 的「Foundation Model」,已经发展到哪一步?丨CVPR 2024 现场直击》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
339 收藏
-
260 收藏
-
438 收藏
-
152 收藏
-
232 收藏
-
280 收藏
-
152 收藏
-
102 收藏
-
247 收藏
-
306 收藏
-
357 收藏
-
334 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习