阿里云通义开源最强过程奖励PRM模型,7B尺寸比GPT-4o更能发现推理错误
时间:2025-01-19 21:27:38 281浏览 收藏
在IT行业这个发展更新速度很快的行业,只有不停止的学习,才不会被行业所淘汰。如果你是科技周边学习者,那么本文《阿里云通义开源最强过程奖励PRM模型,7B尺寸比GPT-4o更能发现推理错误》就很适合你!本篇内容主要包括##content_title##,希望对大家的知识积累有所帮助,助力实战开发!
阿里云通义开源全新数学推理过程奖励模型Qwen2.5-Math-PRM,72B和7B版本性能均大幅领先同类开源模型。尤其在识别推理错误步骤方面,7B小尺寸模型便超越了GPT-4o。同时,通义团队还开源了首个步骤级评估标准ProcessBench,弥补了大模型推理过程错误评估的不足。
大模型推理中常出现逻辑错误或编造看似合理的步骤。准确识别并减少这类错误,对于增强模型推理能力和提升可信度至关重要。过程奖励模型(PRM)为此提供了一种有效方法:PRM对每一步推理行为进行评估和反馈,从而优化模型的推理策略,最终提升推理能力。
通义团队提出了一种高效的PRM数据构建方法,将蒙特卡洛估计与大模型判断相结合,提供更可靠的推理过程反馈。基于Qwen2.5-Math-Instruct模型微调,获得了72B和7B版本的Qwen2.5-Math-PRM模型,数据利用率和性能均显著提升。
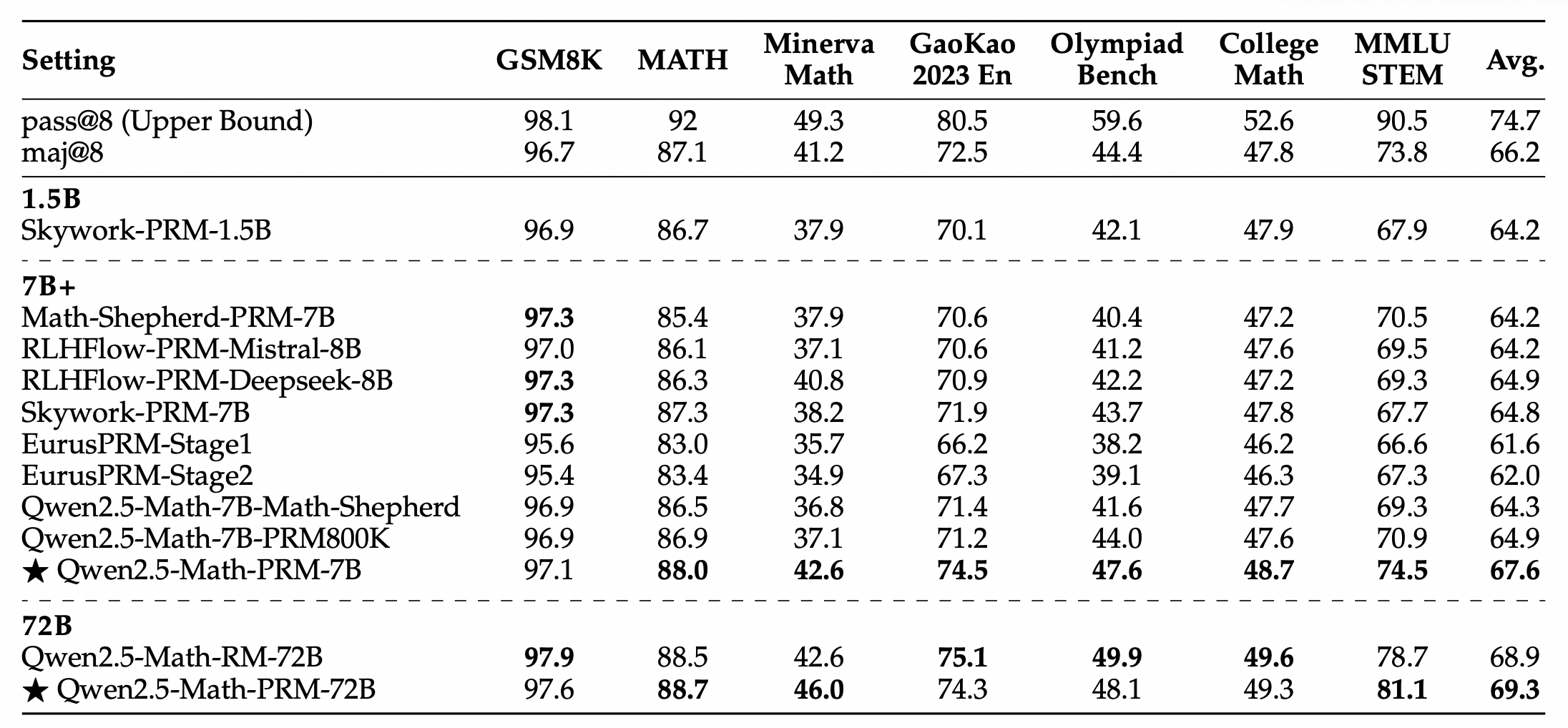
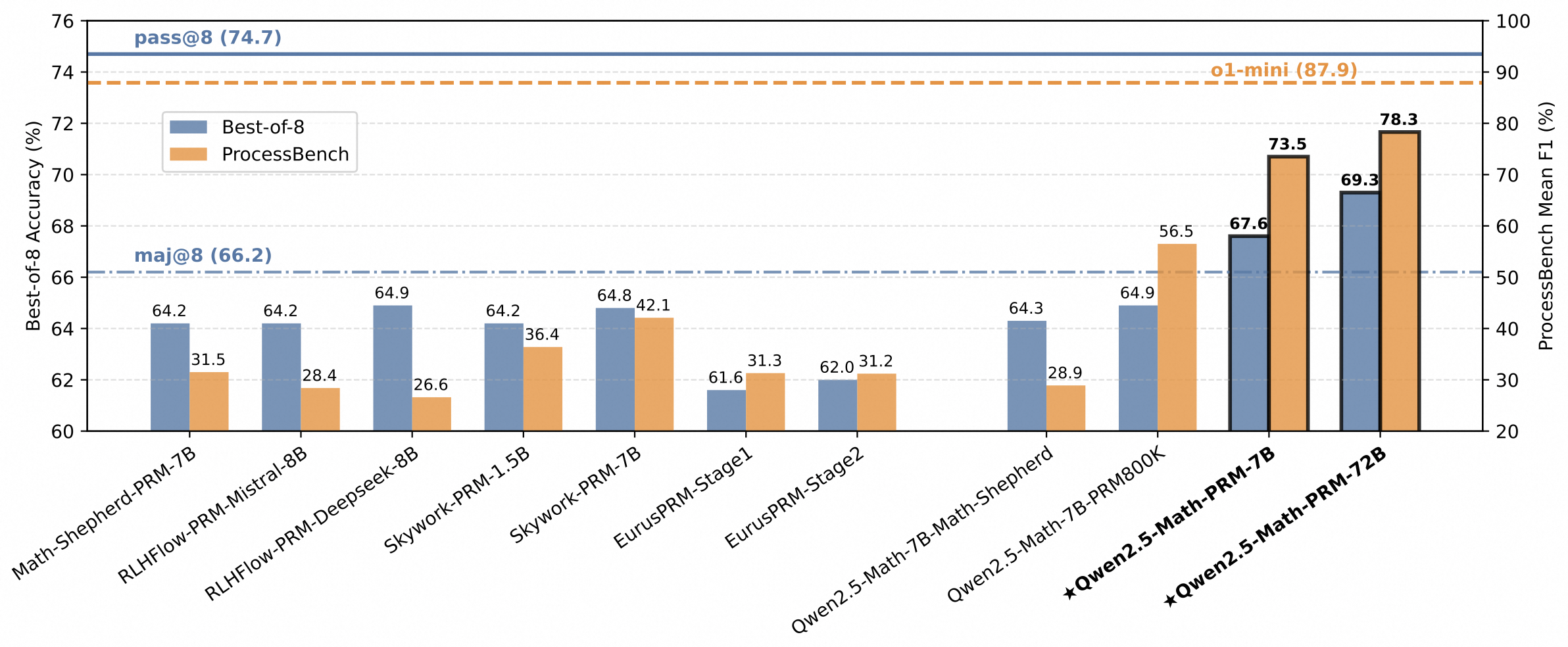
在GSM8K、MATH、Minerva Math等7个数学基准测试的Best-of-N评测中,Qwen2.5-Math-PRM-7B超越了同尺寸的开源PRM模型;Qwen2.5-Math-PRM-72B则整体性能最佳,优于同尺寸的结果奖励模型Qwen2.5-Math-RM-72B。
为更有效地评估模型识别数学推理错误步骤的能力,通义团队创建了ProcessBench评估标准。该基准包含3400个数学问题测试案例,涵盖奥赛难度题目,并由专家标注了逐步推理过程,能够全面评估模型识别错误步骤的能力。该标准也已开源。
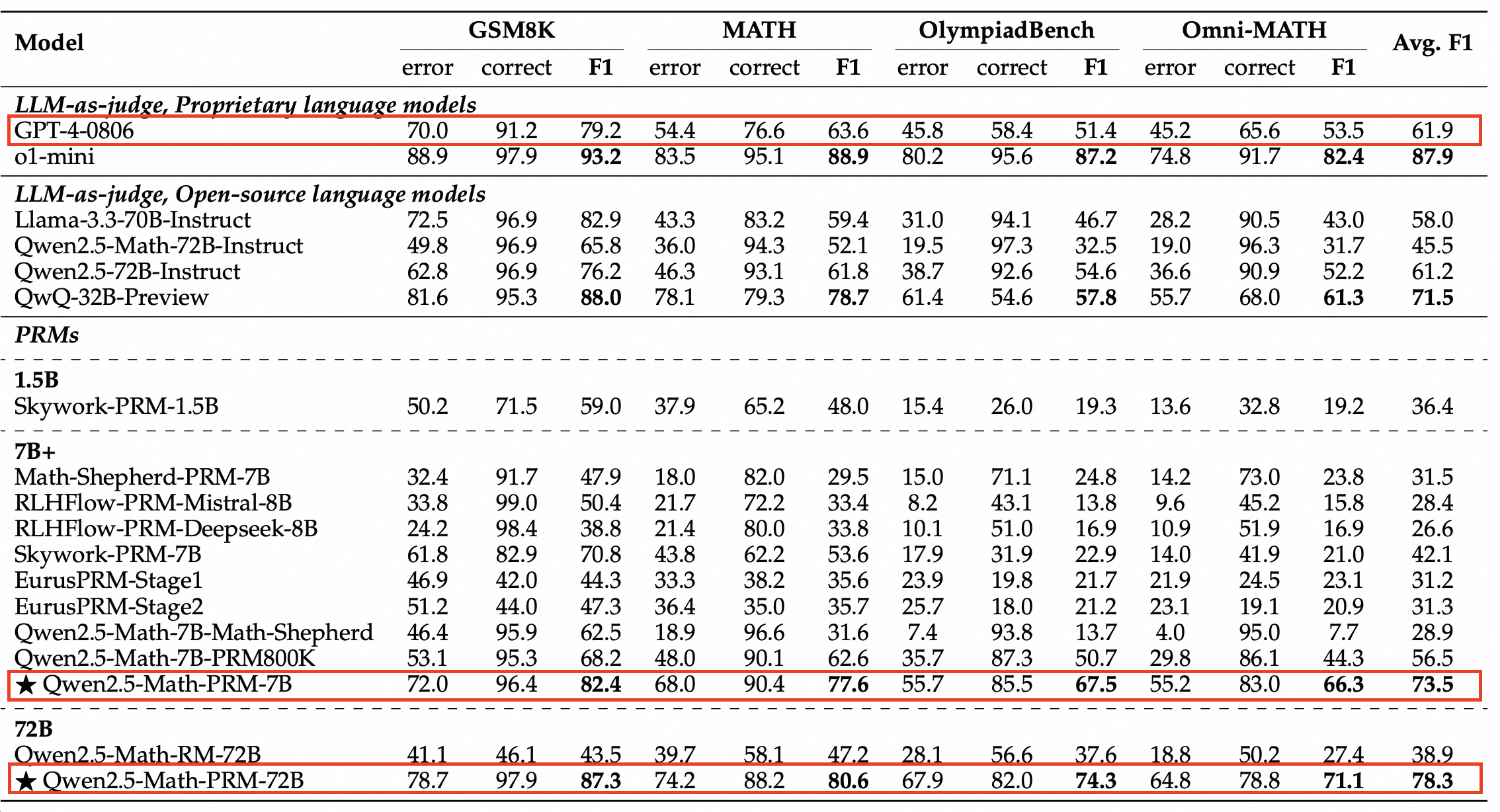
ProcessBench评估结果显示,72B和7B版本的Qwen2.5-Math-PRM均具有显著优势。7B版本不仅超越了同尺寸的开源PRM模型,甚至超过了闭源GPT-4o-0806,证明了PRM在提升推理可靠性方面的有效性,并为未来推理过程监督技术的研发提供了新的方向。
终于介绍完啦!小伙伴们,这篇关于《阿里云通义开源最强过程奖励PRM模型,7B尺寸比GPT-4o更能发现推理错误》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布科技周边相关知识,快来关注吧!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计427 收藏
-
154 收藏
-
309 收藏
-
234 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream448 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 3星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-
453 收藏
-
202 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习