大模型量化训练极限在哪?腾讯混元提出低比特浮点数训练Scaling Laws
时间:2025-01-23 12:16:35 267浏览 收藏
今天golang学习网给大家带来了《大模型量化训练极限在哪?腾讯混元提出低比特浮点数训练Scaling Laws》,其中涉及到的知识点包括等等,无论你是小白还是老手,都适合看一看哦~有好的建议也欢迎大家在评论留言,若是看完有所收获,也希望大家能多多点赞支持呀!一起加油学习~
腾讯混元团队揭示大模型浮点量化训练规律,找到最佳性价比配置

大模型低精度训练和推理是降低成本的关键方向,而浮点量化因其损耗小而备受关注。然而,现有整数量化经验能否直接应用于浮点量化?浮点量化是否存在极限?这些问题亟待解答。腾讯混元团队近期发表的论文《Scaling Laws for Floating–Point Quantization Training》(https://huggingface.co/papers/2501.02423)对此进行了深入研究,并提出了浮点量化的Scaling Laws。
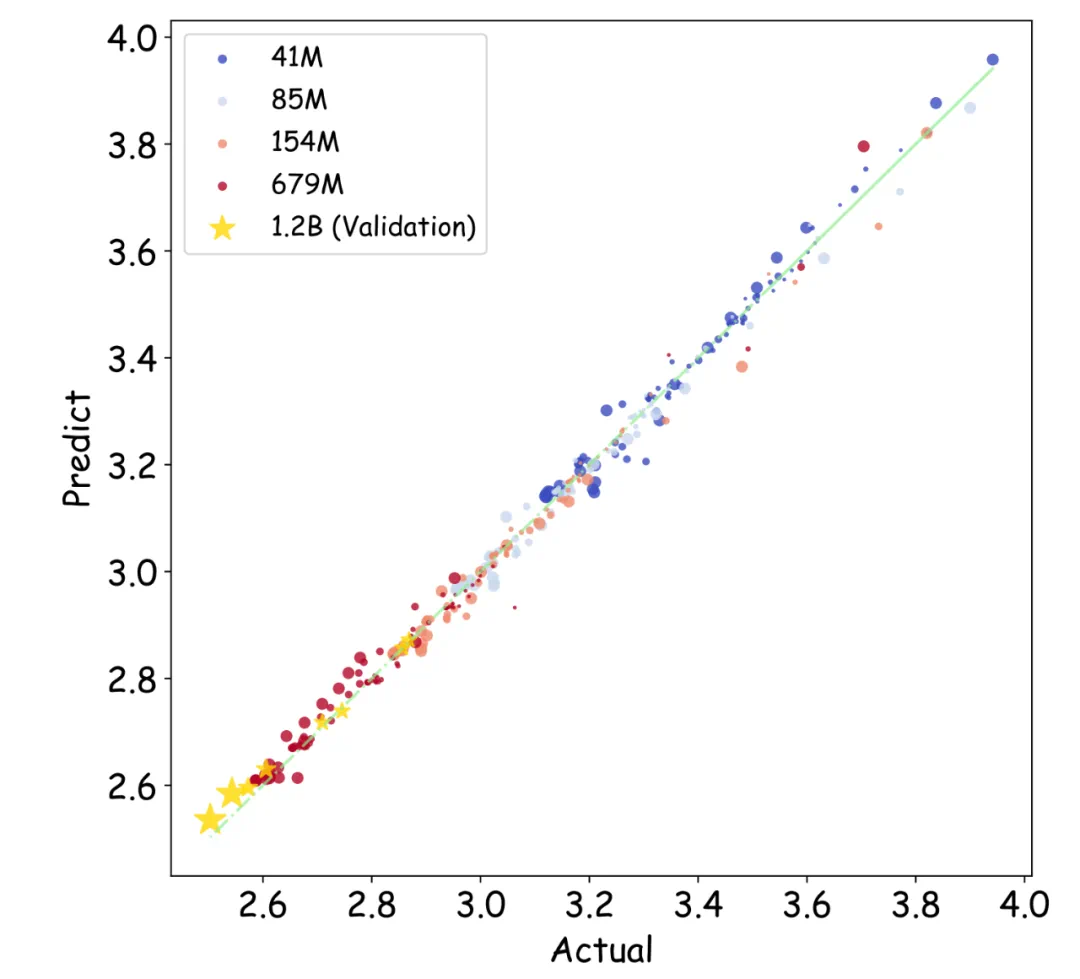
该研究通过366组不同参数规模和精度的浮点量化训练实验,综合考虑模型大小(N)、训练数据量(D)、指数位(E)、尾数位(M)以及量化放缩因子共享粒度(B),最终得出统一的Scaling Law公式:
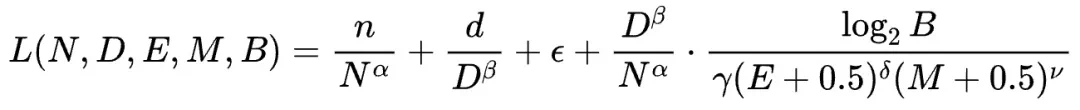
基于此公式,研究团队得出以下重要结论:
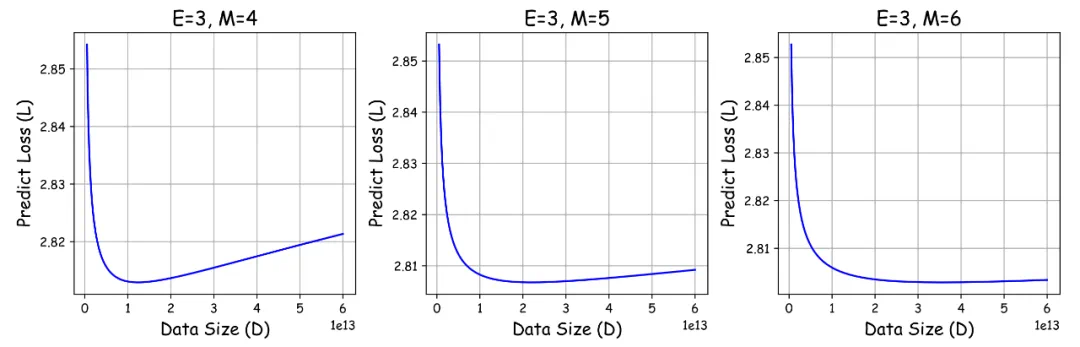
- 存在模型效果极限及最佳数据量: 无论精度如何,每个模型都存在一个最佳数据量,超过此量反而会降低效果。
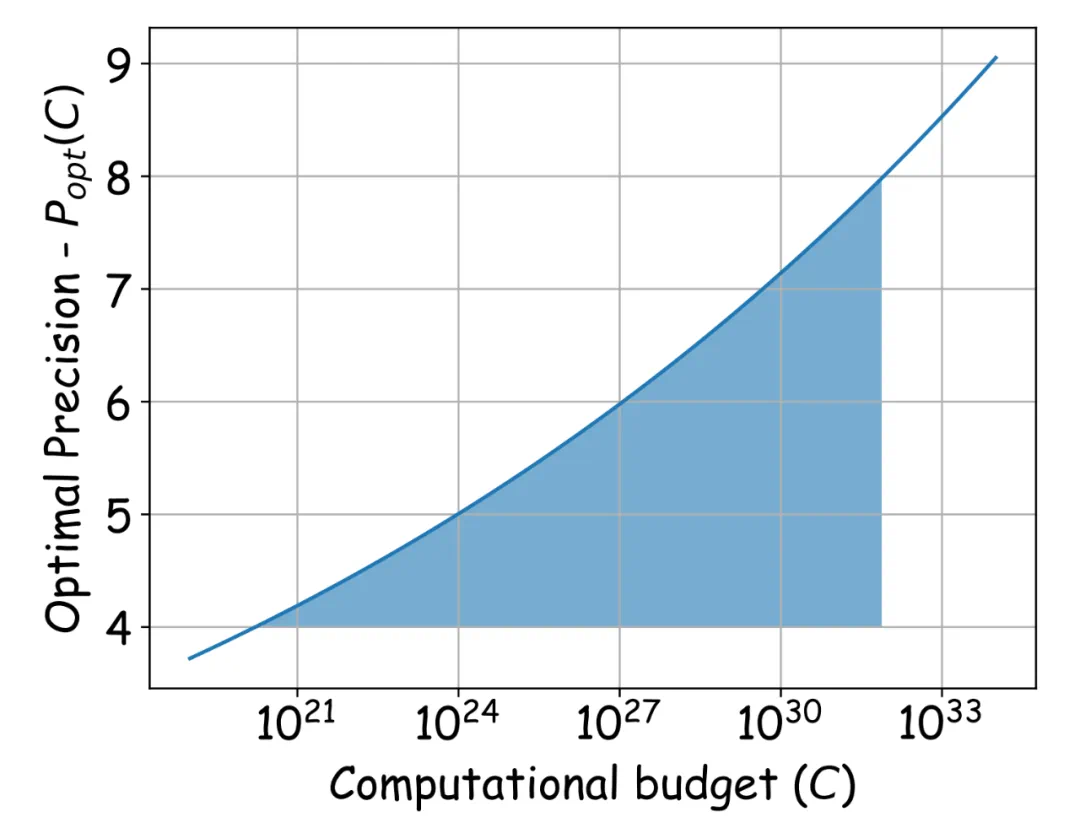
- 最佳性价比精度范围: 在大范围算力下,理论预测的最佳性价比精度位于4-8比特之间。
- 资源受限下的最优配置策略: 该Scaling Laws可指导在不同计算资源下,确定最佳性价比的浮点量化训练精度、模型参数量和训练数据量。
浮点数最佳配比及精细量化
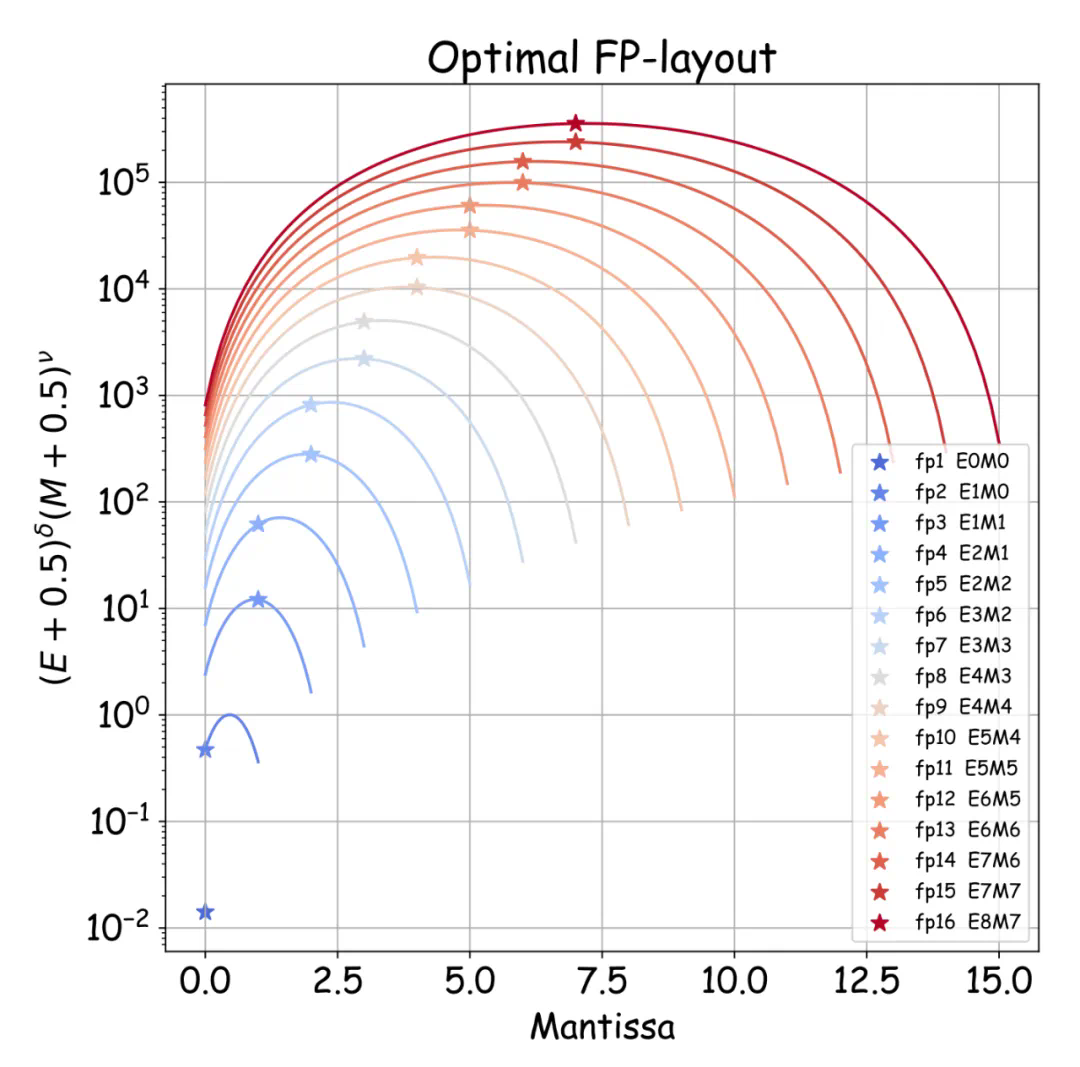
研究团队还深入分析了指数位(E)和尾数位(M)对模型效果的影响,得出其最佳配比规律:
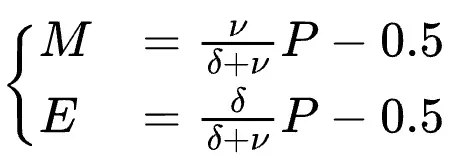
并定量研究了放缩因子共享粒度(B)的影响,发现验证损失与B的对数成正比:
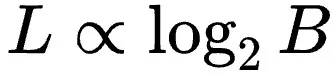
效果屏障与资源受限下的最优解
该研究发现,由于效果屏障的存在,即使资源无限,训练数据量也不应超过Dcrit:
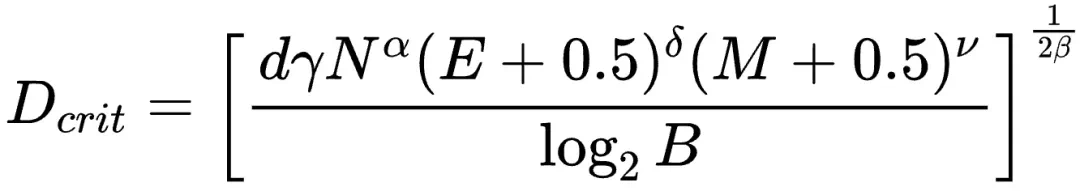
在资源受限的情况下,通过求解方程组,可以得到最佳性价比精度和参数量N与数据量D的配置策略,以及精度P与参数量N之间的“汇率”关系:
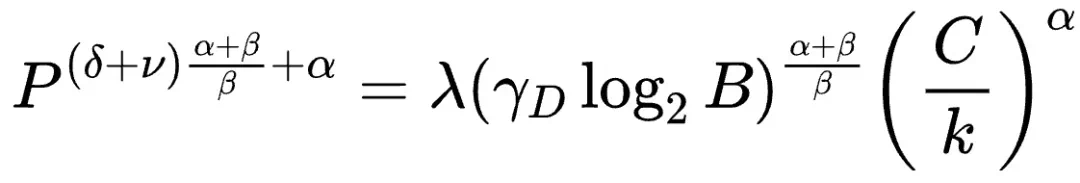
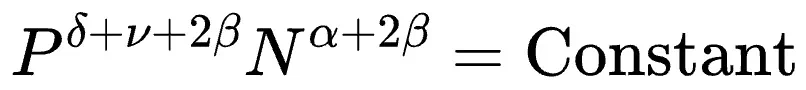
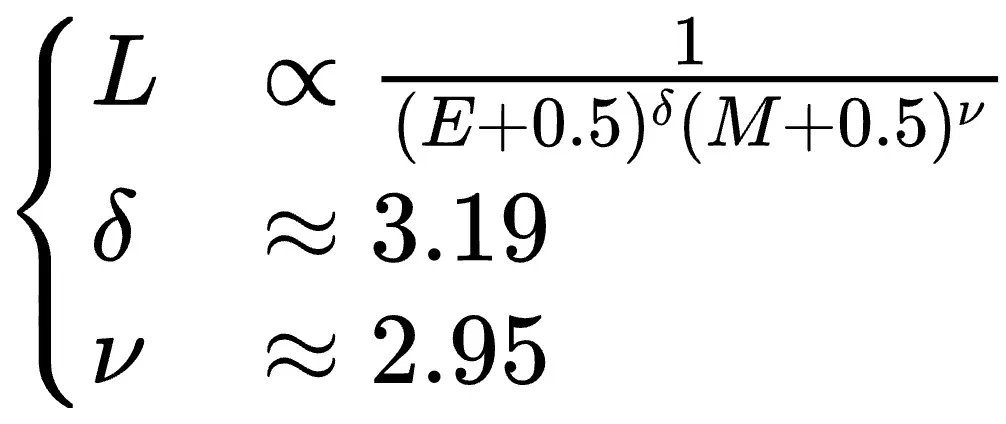
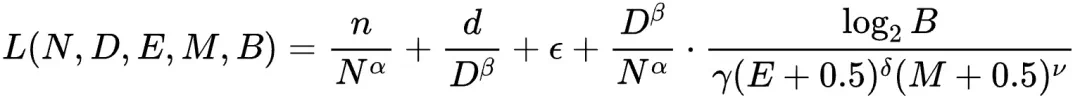
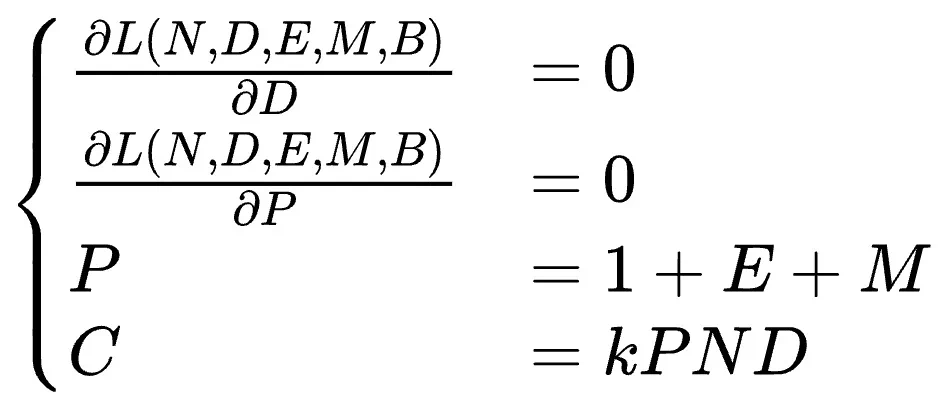
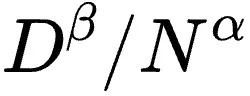
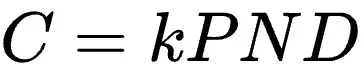
这项研究为大模型浮点量化训练提供了重要的理论指导,对降低训练成本和推动大模型应用具有重要意义。 它不仅为优化训练配置提供了依据,也为硬件厂商优化浮点运算能力和研究人员开展相关创新提供了新的方向。
文中关于工程的知识介绍,希望对你的学习有所帮助!若是受益匪浅,那就动动鼠标收藏这篇《大模型量化训练极限在哪?腾讯混元提出低比特浮点数训练Scaling Laws》文章吧,也可关注golang学习网公众号了解相关技术文章。
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习