817样本激发7倍推理性能:上交大「少即是多」定律挑战RL Scaling范式
时间:2025-02-07 13:46:12 428浏览 收藏
珍惜时间,勤奋学习!今天给大家带来《817样本激发7倍推理性能:上交大「少即是多」定律挑战RL Scaling范式》,正文内容主要涉及到等等,如果你正在学习科技周边,或者是对科技周边有疑问,欢迎大家关注我!后面我会持续更新相关内容的,希望都能帮到正在学习的大家!
上海交大最新研究颠覆传统认知:只需817个样本,AI数学推理能力即可超越众多顶尖模型!这项名为LIMO(Less Is More for Reasoning)的研究成果,挑战了“更大即更强”的行业共识,证明了高质量小样本数据在激发大模型推理能力方面的巨大潜力。

- 论文标题:LIMO: Less is More for Reasoning
- 论文地址:https://arxiv.org/pdf/2502.03387
- 代码地址:https://github.com/GAIR-NLP/LIMO
- 数据集地址:https://huggingface.co/datasets/GAIR/LIMO
- 模型地址:https://huggingface.co/GAIR/LIMO
一、挑战规模竞赛:激活模型潜能
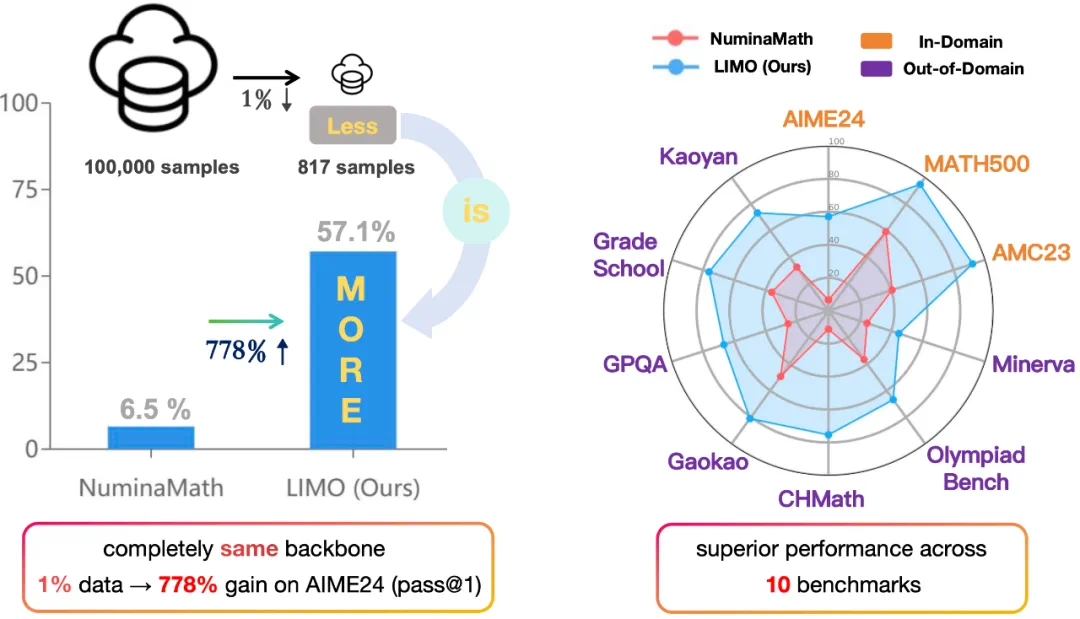
在AI数学推理领域,普遍认为需要海量数据和复杂的强化学习才能取得突破。然而,LIMO研究指出,大模型的数学能力可能早已存在,关键在于如何有效“唤醒”它。 这项研究仅用817个精心设计的样本,通过简单的监督微调,就使模型在数学竞赛级别的题目上超越了众多使用十万级数据训练的先进模型,例如o1-preview和QwQ。
二、少即是多:从对齐到推理的范式转变
LIMO延续了此前LIMA(Less Is More for Alignment)的研究理念,即在特定任务中,少量高质量数据即可取得显著效果。但将此应用于数学推理领域面临更大挑战。LIMO的成功,归功于两个关键因素:
- 知识基础革命: 现代LLM在预训练阶段已掌握海量数学知识。
- 推理计算革命: 长推理链与模型推理能力密切相关。
LIMO假设:在知识基础足够完善的前提下,少量高质量样本,通过推理链即可激活模型的潜在推理能力。

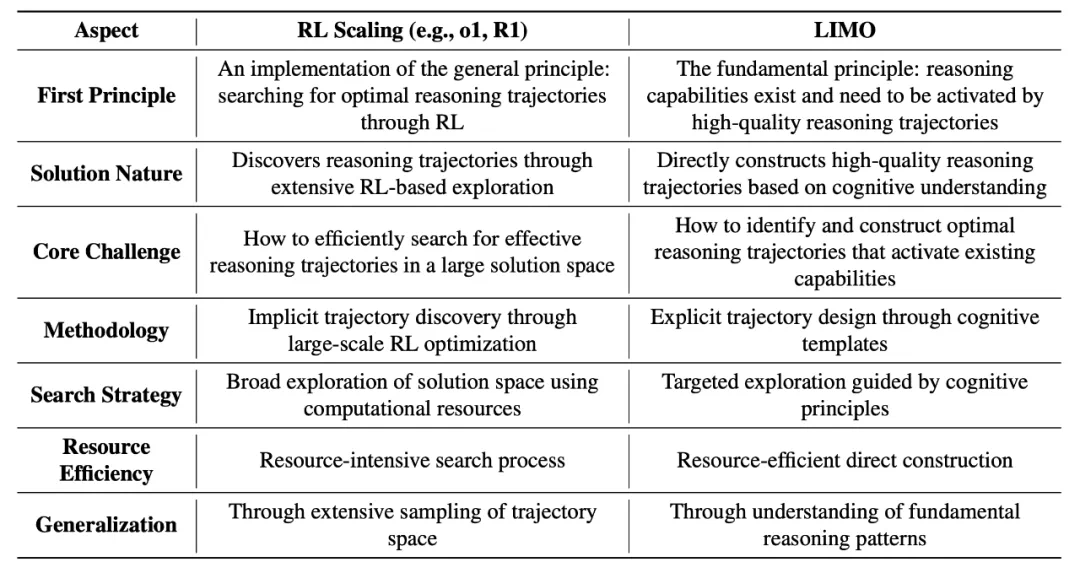
三、LIMO与强化学习扩展的对比
传统强化学习扩展方法(如OpenAI的o1系列和DeepSeek-R1)依赖海量数据和复杂算法,将推理能力提升视为一个“搜索”过程。而LIMO则专注于“激活”模型已具备的能力,强调方向的重要性,将强化学习视为寻找最优推理轨迹的一种手段。
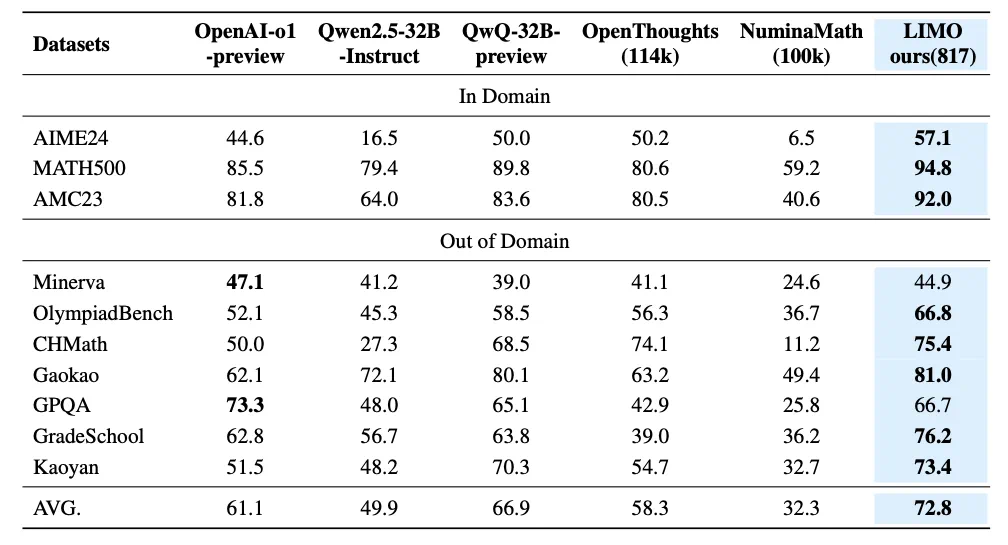
四、实验结果:显著超越传统方法
LIMO在多个基准测试中均取得了显著优于其他模型的结果,例如在AIME24测试中准确率高达57.1%,远超其他模型。这证明了高质量小样本数据的巨大潜力。
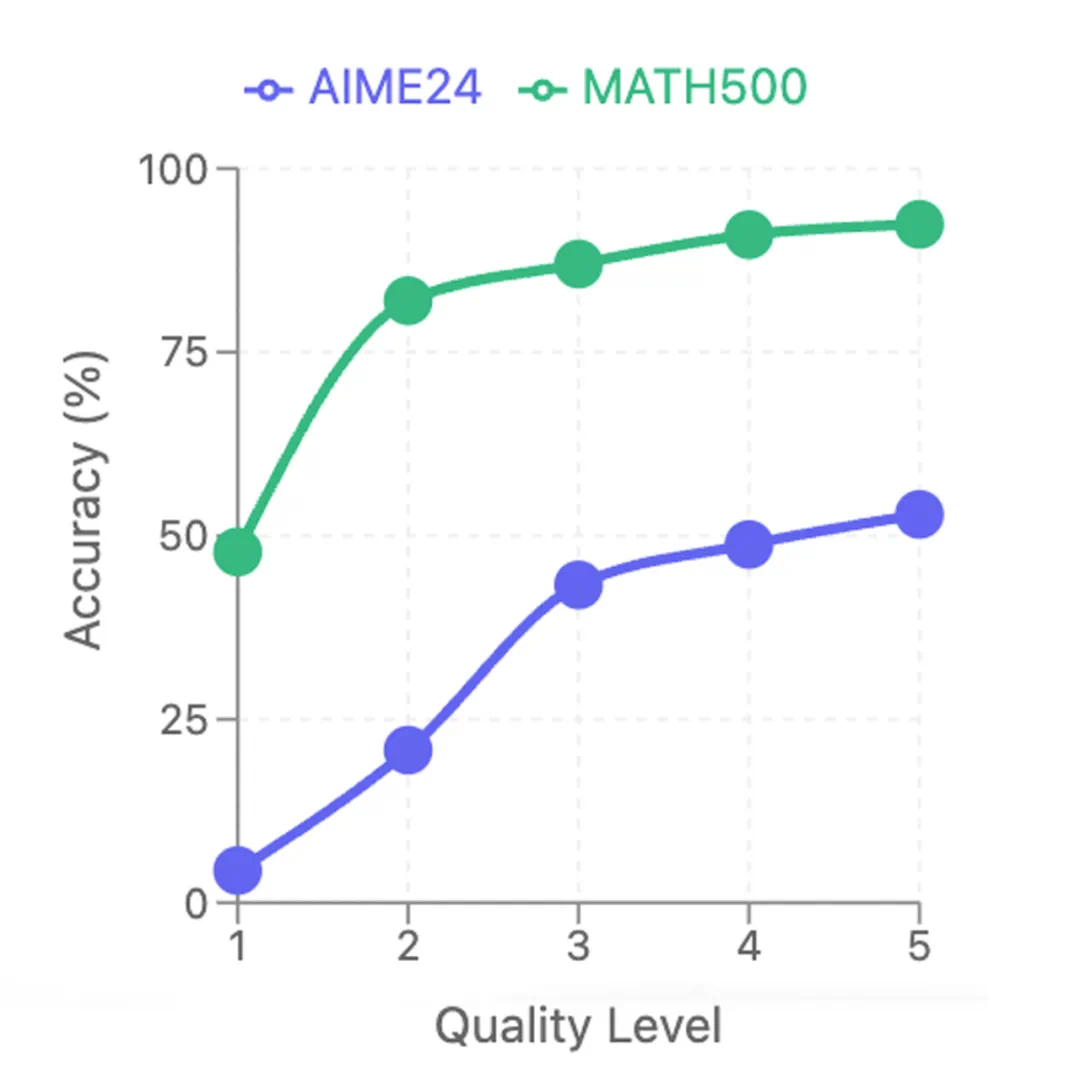
五、数据的三重密码:推理链质量、问题难度、预训练知识
LIMO数据集的成功,在于这三个关键因素:高质量推理链、更具挑战性的问题和高质量预训练知识。
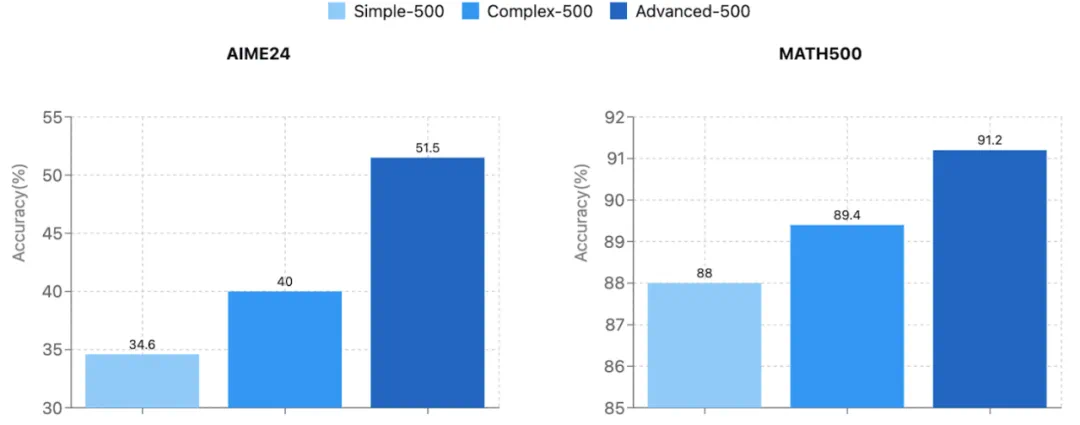

六、案例与定量分析:LIMO的卓越表现
具体的案例分析和定量数据进一步证明了LIMO的卓越推理能力和自我反思能力。

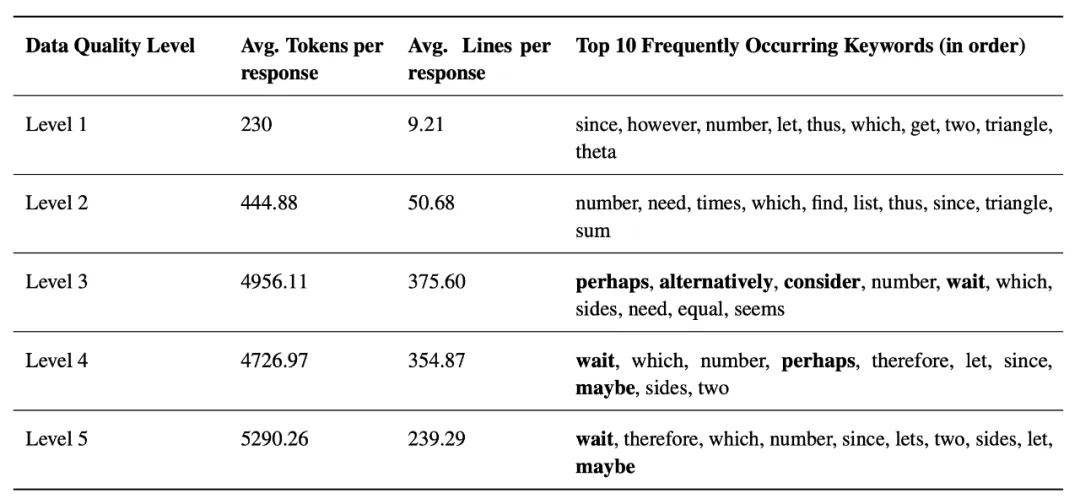
七、未来展望:少即是多的无限可能
LIMO的研究为未来研究指明了方向,包括领域泛化、理论基础研究、自动化评估、多模态集成、实际应用和认知科学的结合等。 LIMO的成功,标志着人工智能推理能力觉醒的新篇章。
以上就是《817样本激发7倍推理性能:上交大「少即是多」定律挑战RL Scaling范式》的详细内容,更多关于工程,上海交通大学,LIMO的资料请关注golang学习网公众号!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
468 收藏
-
科技周边 · 人工智能 | 1天前 | 人工智能 · ai agent · AI应用 · 工具调用 · 权限边界 · 审计链路 · 人工智能 权限控制 AI Agent 工具调用 审批链路 审计回放 上线指标343 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · GenAI · opentelemetry · 可观测性 · AI工程 · 人工智能 链路追踪 GenAI OpenTelemetry AI可观测性 LLM网关 Token统计427 收藏
-
154 收藏
-
309 收藏
-
234 收藏
-
科技周边 · 人工智能 | 1星期前 | 人工智能 · 前端流式输出 · AI聊天 · Fetch Stream · 前端 AI聊天 流式输出 ReadableStream TextDecoder Fetch Stream448 收藏
-
427 收藏
-
191 收藏
-
299 收藏
-
科技周边 · 人工智能 | 3星期前 | 人工智能 · mcp · ai agent · 工具接入 · 安全审计 · AI Agent MCP Model Context Protocol 工具清单 资源上下文 权限审计378 收藏
-
195 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习