DeepSeek-R1、o1都低于10%,人类给AI的「最后考试」来了,贡献者名单长达两页
时间:2025-02-08 16:25:56 474浏览 收藏
本篇文章主要是结合我之前面试的各种经历和实战开发中遇到的问题解决经验整理的,希望这篇《DeepSeek-R1、o1都低于10%,人类给AI的「最后考试」来了,贡献者名单长达两页》对你有很大帮助!欢迎收藏,分享给更多的需要的朋友学习~
AI大模型正以前所未有的速度发展,其能力已在许多任务上达到甚至超越人类水平。然而,现有的基准测试已难以准确衡量最先进的大型语言模型(LLM)的能力,例如,在常用的MMLU基准测试中,顶尖LLM的准确率已超过90%。
为应对这一挑战,AI安全中心(Center for AI Safety)与Scale AI合作,推出了一项极具挑战性的新基准测试:人类的最后考试(Humanity's Last Exam,HLE)。
HLE旨在成为一个涵盖广泛学科的终极封闭式学术基准,目前包含3000多个难题,涉及数百个学科领域,包括数学、人文科学和自然科学。题目主要为多项选择题和简答题,答案明确且易于验证,但无法通过网络搜索快速解答。
HLE的构建汇聚了全球近千名专家的力量,他们来自50多个国家和地区的500多个机构。
 这项庞大的工作也设立了50万美元的奖金池,鼓励高质量的题目提交。
这项庞大的工作也设立了50万美元的奖金池,鼓励高质量的题目提交。
一些SOTA模型在HLE上的表现令人惊讶地低。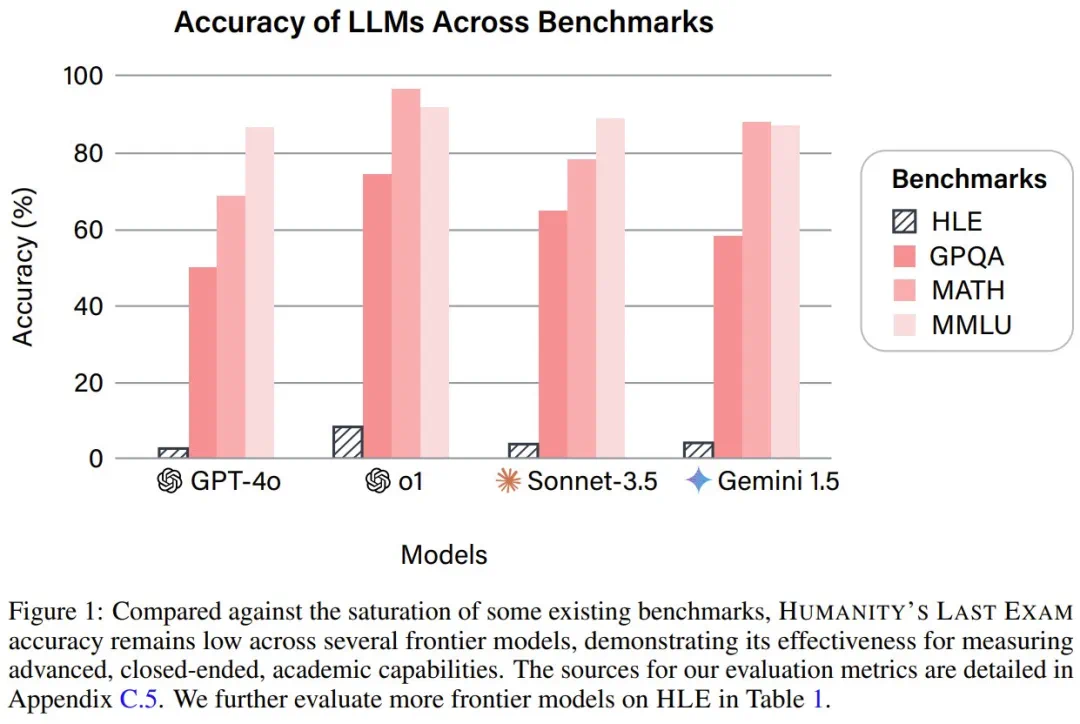 即使是顶尖模型,准确率也远低于10%。 HLE数据集的学科覆盖范围如下图所示:
即使是顶尖模型,准确率也远低于10%。 HLE数据集的学科覆盖范围如下图所示: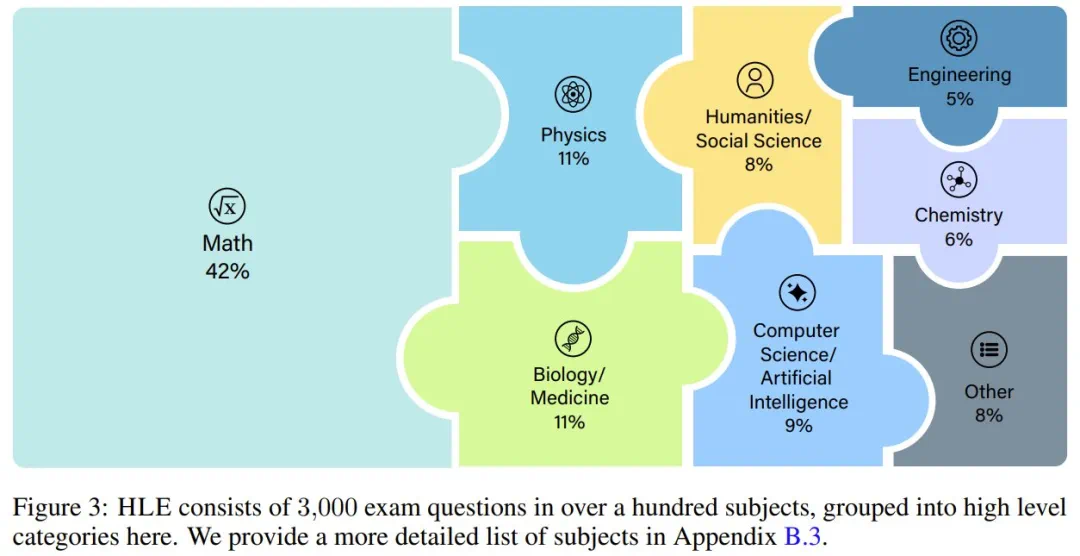 部分题目示例如下:
部分题目示例如下: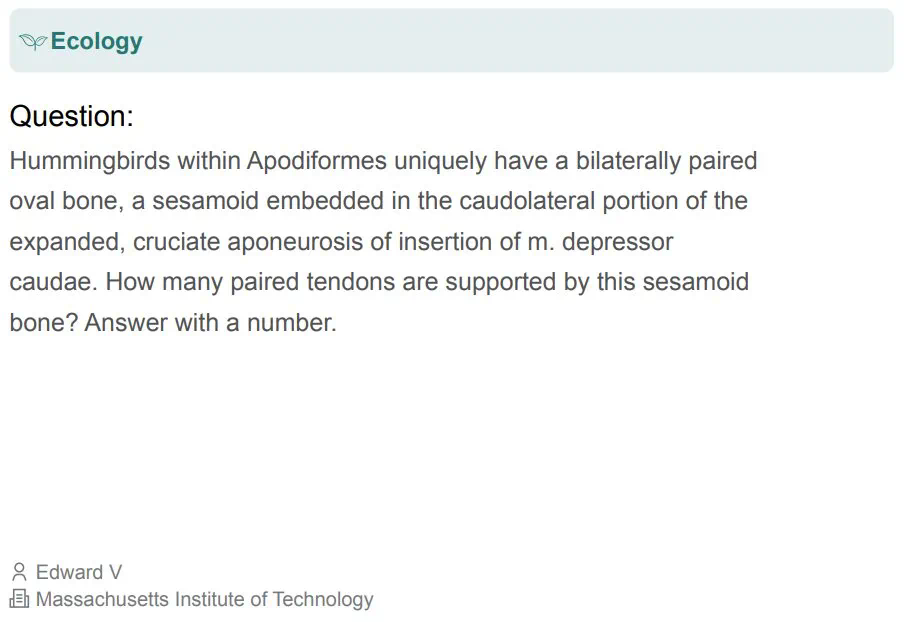
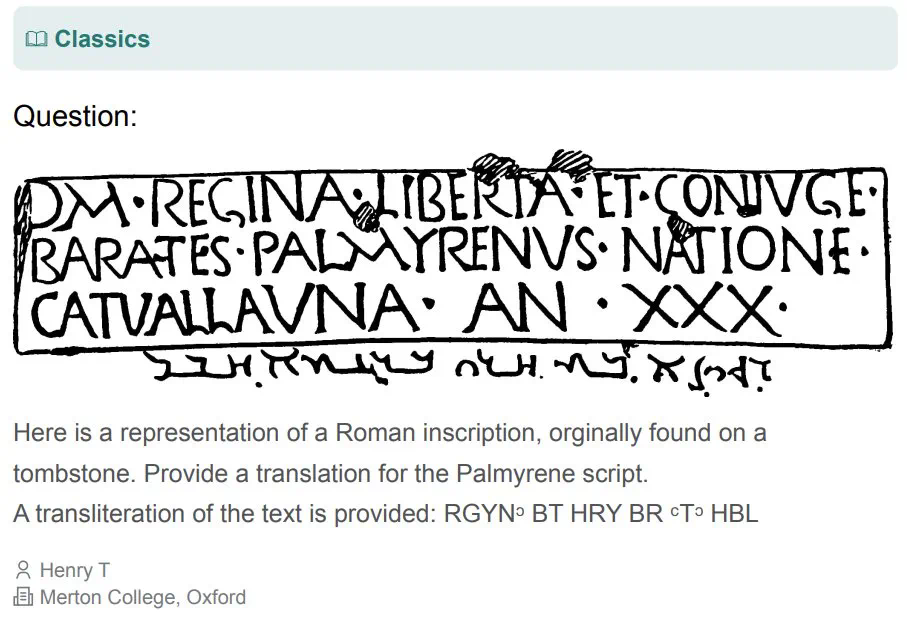


除了公开发布的题目,研究团队还保留了一个私有测试集,用于评估模型的过拟合情况。 HLE的数据收集过程严格,确保题目准确、明确、可解且不可通过简单搜索获得答案。
尽管目前LLM在HLE上的表现不佳,但研究团队预测,到2025年底,模型的准确率可能超过50%。 即使模型在HLE上取得高分,也并不意味着其具备了通用人工智能,HLE主要测试的是模型在结构化学术问题上的推理能力。 研究团队认为,HLE可能是对模型进行的“最后一次学术考试”,但这绝非AI发展的最终基准。 最新的o3-mini模型在HLE上的表现,以及使用Deep Research后的表现结果也已更新至官网。
 模型的token使用量分析也表明,未来模型不仅需要提高准确率,还需要优化计算效率。
模型的token使用量分析也表明,未来模型不仅需要提高准确率,还需要优化计算效率。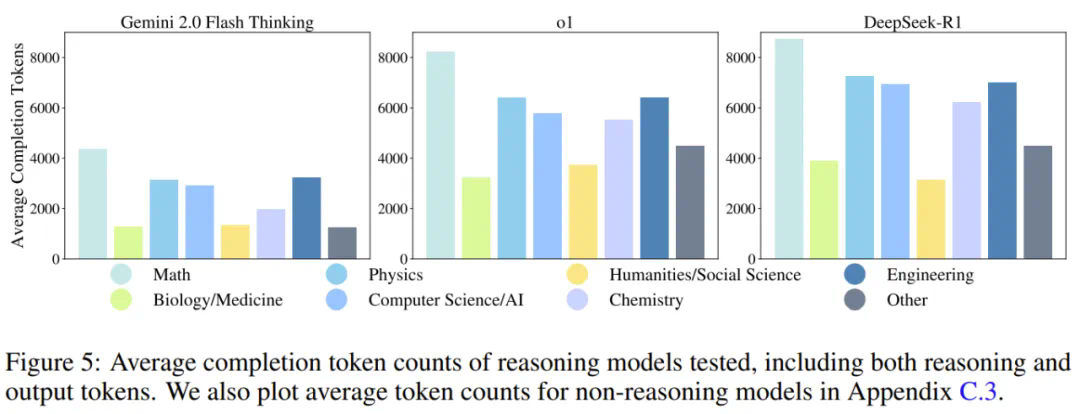
到这里,我们也就讲完了《DeepSeek-R1、o1都低于10%,人类给AI的「最后考试」来了,贡献者名单长达两页》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于产业的知识点!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
339 收藏
-
260 收藏
-
438 收藏
-
152 收藏
-
232 收藏
-
280 收藏
-
152 收藏
-
102 收藏
-
247 收藏
-
306 收藏
-
357 收藏
-
334 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习