知乎 Hive Metastore 实践:从 MySQL 到 TiDB
来源:SegmentFault
时间:2023-02-24 17:03:38 133浏览 收藏
你在学习数据库相关的知识吗?本文《知乎 Hive Metastore 实践:从 MySQL 到 TiDB》,主要介绍的内容就涉及到MySQL、tidb、hive,如果你想提升自己的开发能力,就不要错过这篇文章,大家要知道编程理论基础和实战操作都是不可或缺的哦!
作者介绍:胡梦宇,知乎数据架构平台开发工程师
背景
Apache Hive 是基于 Apache Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并且提供了 Hive SQL 进行查询和分析,在离线数仓中被广泛使用。
Hive Metastore 是 Hive 的元信息管理工具,它提供了操作元数据的一系列接口,其后端存储一般选用关系型数据库如 Derby、 MySQL 等。现在很多除了 Hive 之外计算框架都支持以 Hive Metastore 为元数据中心来查询底层 Hadoop 生态的数据,比如 Presto、Spark、Flink 等等。
在知乎,我们是将元信息存储在 MySQL 内的,随着业务数据的不断增长,MySQL 内已经出现单表数据量两千多万的情况,当用户的任务出现 Metastore 密集操作的情况时,往往会出现缓慢甚至超时的现象,极大影响了任务的稳定性。长此以往,MySQL 在未来的某一天一定会不堪重负,因此优化 Hive 的元数据库势在必行。
在去年,我们做过数据治理,Hive 表生命周期管理,定期去删除元数据,期望能够减少 MySQL 的数据量,缓解元数据库的压力。但是经过实践,发现该方案有以下缺点:
- 数据的增长远比删除的要快,治标不治本;
- 在删除超大分区表(分区数上百万)的分区时,会对 MySQL 造成一定的压力,只能单线程去做,否则会影响其他正常的 Hive 查询,效率极其低下;
- 在知乎,元信息删除是伴随数据一起删除的(删除 HDFS 过期数据,节约成本),Hive 的用户可能存在建表不规范的情况,将分区路径挂错,导致误删数据。
因此,我们需要寻找新的技术方案来解决这个问题。
技术选型
已有方案
业内目前有两种方案可供借鉴:
- 对 MySQL 进行分库分表处理,将一台 MySQL 的压力分摊到 MySQL 集群;
- 对 Hive Metastore 进行 Federation,采用多套 Hive Metastore + MySQL 的架构,在 Metastore 前方设置代理,按照一定的规则,对请求进行分发。
但是经过调研,我们发现两种方案都有一定的缺陷:
- 对 MySQL 进行分库分表,首先面临的直接问题就是需要修改 Metastore 操作 MySQL 的接口,涉及到大量高风险的改动,后续对 Hive 的升级也会更加复杂;
- 对 Hive Metastore 进行 Federation,尽管不需要对 Metastore 进行任何改动,但是需要额外维护一套路由组件,并且对路由规则的设置需要仔细考虑,切分现有的 MySQL 存储到不同的 MySQL 上,并且可能存在切分不均匀,导致各个子集群的负载不均衡的情况;
- 我们每天都会同步一份 MySQL 的数据到 Hive,用作数据治理,生命周期管理等,同步是利用内部的数据同步平台,如果采用上面两种方案,数据同步平台也需要对同步逻辑做额外的处理。
最终方案
其实问题主要在于,当数据量增加时,MySQL 受限于单机性能,很难有较好的表现,而将单台 MySQL 扩展为集群,复杂度将会呈几何倍上升。如果能够找到一款兼容 MySQL 协议的分布式数据库,就能完美解决这个问题。因此,我们选择了 TiDB。
TiDB 是 PingCAP 开源的分布式 NewSQL 数据库,它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适 OLAP 场景的混合数据库。
选用 TiDB 的理由如下:
- TiDB 完全兼容 MySQL 的协议,经过测试,TiDB 支持 Hive Metastore 对元数据库的所有增删改查操作, 使用起来不存在兼容性相关的问题。因此,除了将 MySQL 的数据原样 dump 到 TiDB,几乎没有其他工作需要做;
- TiDB 由于其分布式的架构,在大数据集的表现远远优于 MySQL;
- TiDB 的可扩展性十分优秀,支持水平弹性扩展,不管是选用分库分表还是 Federation,都可能会再次遇到瓶颈,届时需要二次切分和扩容,TiDB 从根本上解决了这个问题;
- TiDB 在知乎已经得到了十分广泛的应用,相关技术相对来说比较成熟,因此迁移风险可控。
Hive 架构
迁移前
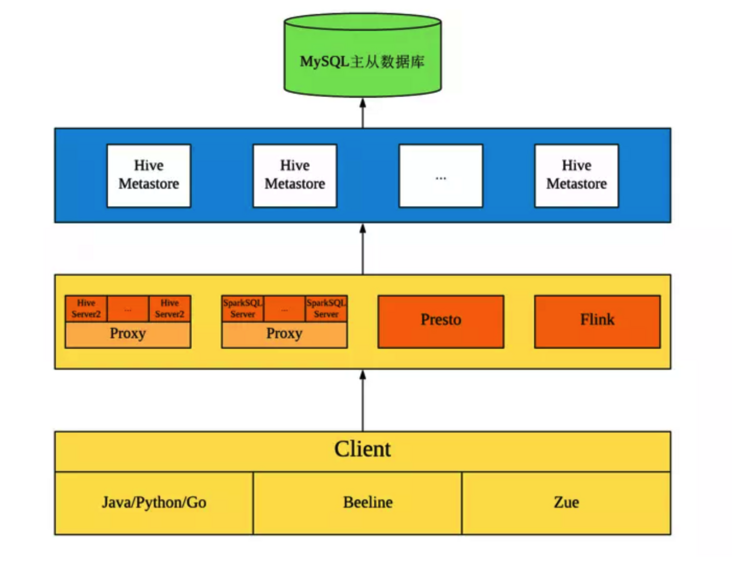
其中 Zue 是知乎内部使用的可视化查询界面。
迁移后
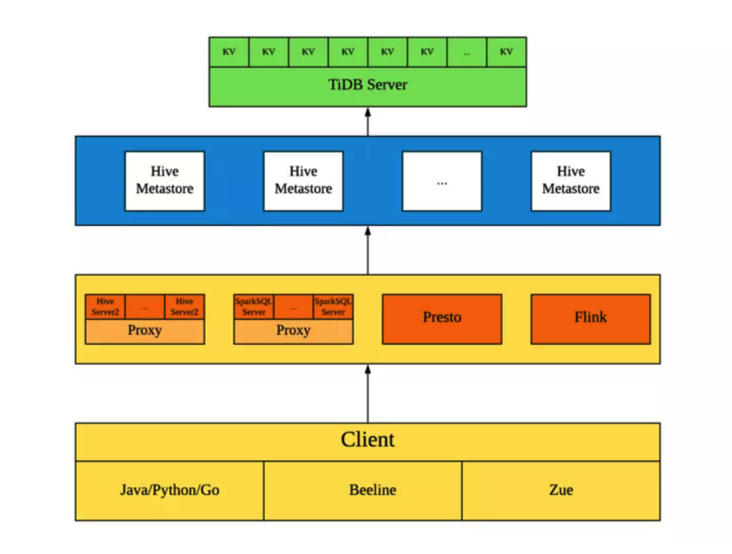
在 Hive 的元数据库迁移到 TiDB 了以后,架构几乎没有任何变化,只不过查询的压力由单台 MySQL 节点分摊到了整个 TiDB 集群,集群越大,查询效率越高,性能提升越明显。
迁移流程
- 将 TiDB 作为 MySQL 的从库,实时同步数据;
- Metastore 缩容至 1 个,防止多个 Metastore 分别向 MySQL 及 TiDB 写入,导致元数据不一致;
- 选取业务低峰期,主从切换,将主切为 TiDB,重启 Metastore ;
- Metastore 扩容。
此迁移过程对业务几乎无感,成功上线。
运行概况
-
我们从 Hive 层面对数据库进行了测试,模拟业务高峰期,多并发对百万分区级别的表增删分区,所执行的 Hive SQL 如下:
ALTER TABLE '${table_name}' DROP IF EXISTS PARTITION(...); ALTER TABLE '${table_name}' ADD IF NOT EXISTS PARTITION(...);
花费时间从 45s-75s 降低到了 10s 以下。
- 我们从元数据库层面测试了一些 Metastore 提交的 SQL,尤其是那些会造成元数据库压力巨大的 SQL,例如:
SELECT `A0`.`PART_NAME`,`A0`.`PART_NAME` AS `NUCORDER0` FROM `PARTITIONS` `A0
当某个 Hive 表的分区数量十分巨大时,这条 SQL 会给元数据库造成相当大的负担。迁移前,此类 SQL 在 MySQL 运行时间约为 30s - 40s,迁移后,在 TiDB 运行仅需 6s - 7s,提升相当明显。
- 数据同步平台上的 Hive 元数据库内的 SDS 表的同步任务时间从 90s 降低到 15s。
展望
在 Hive Metastore 的场景下,我们已经感受到了 TiDB 在大数据应用场景下的魅力。后续我们希望 TiDB 能够成为跨数据中心的服务,通过数据副本的跨机房部署,打通离线与在线,让离线场景能够在对在线服务无压力的情况下为数据提供实时的 ETL 能力,解决离线 ETL 任务实时性差的问题。为此,我们正在开发 TiBigData。
目前其作为 PingCAP Incubator 的孵化项目。由来自知乎的 TiKV Maintainer 孙晓光发起。PingCAP Incubator 旨在梳理一套相对完整的 TiDB 生态开源项目孵化体系,将关于 TiDB 开源生态的想法与实际生产环境中的需求相关联,通过开源项目协作方式,共同将想法落地。力求想法项目化。从「我有一个想法」到「项目顺利毕业」,PingCAP 提供一系列的资源支持,确保所有项目孵化的流程都有章可循,同时结合项目不同特征及孵化目的,将项目划分为 Feature 类和 Project 类,针对性地给出孵化流程建议。PingCAP Incubator 中的项目有:TiDB Dashboard、TiUP、TinyKV,TiDB Wasm 等。
完整项目请查看:
https://github.com/pingcap-incubator
PingCAP Incubator 完整文档参考:
https://github.com/pingcap/community/tree/master/incubator
目前 TiBigData 项目已经为 TiDB 提供了 Presto 与 Flink 的只读支持。后续我们希望在 PingCAP Incubator 计划的扶持下同社区一起建设 TiBigData 项目,力图为 TiDB 带来更加完整的大数据能力。
本篇关于《知乎 Hive Metastore 实践:从 MySQL 到 TiDB》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于数据库的相关知识,请关注golang学习网公众号!
-
374 收藏
-
499 收藏
-
384 收藏
-
184 收藏
-
265 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习