数据库中间件分片算法之stringhash
来源:SegmentFault
时间:2023-02-23 16:28:36 309浏览 收藏
编程并不是一个机械性的工作,而是需要有思考,有创新的工作,语法是固定的,但解决问题的思路则是依靠人的思维,这就需要我们坚持学习和更新自己的知识。今天golang学习网就整理分享《数据库中间件分片算法之stringhash》,文章讲解的知识点主要包括MySQL、数据库,如果你对数据库方面的知识点感兴趣,就不要错过golang学习网,在这可以对大家的知识积累有所帮助,助力开发能力的提升。
前言
又是一个夜黑风高的晚上,带上无线耳机听一曲。突然很感慨一句话:
name func_hashString 3,2 3,4 0:3
和之前的hash算法一样。需要在rule.xml中配置tableRule和function。
- tableRule标签,name对应的是规则的名字,而rule标签中的columns则对应的分片字段,这个字段必须和表中的字段一致。algorithm则代表了执行分片函数的名字。
- function标签,name代表分片算法的名字,算法的名字要和上面的tableRule中的
标签相对应。class:指定分片算法实现类。property指定了对应分片算法的参数。不同的算法参数不同。
1.partitionCount:指定分区的区间数,具体为 C1 +C2 + ... + Cn
2.partitionLength:指定各区间长度,具体区间划分为 [0, L1), [L1, 2L1), ..., [(C1-1)L1, C1L1), [C1L1, C1L1+L2), [C1L1+L2, C1L1+2L2), ... 其中,每一个区间对应一个数据节点。
3.hashSlice:指定参与hash值计算的key的子串。字符串从0开始索引计数
接下来我们来详细介绍一下StringHash的工作原理。我们以上面的配置为例。
1.在启动的时候,两个数组点乘做运算,得到取模数。

2.两个数组进行叉乘,得出物理分区表。

3.根据hashSlice二维数组,把分片字段的字符串进行截取。
字符串截取的范围是hashSlice[0]到hashSlice[1]。比如我这里设置0,3。‘buddy'这个字符串就会截取出
/** * String hash:s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* h = 31*h + s.charAt(i); => h = (h * * @param start hash for s.substring(start, end) * @param end hash for s.substring(start, end) */ public static long hash(String s, int start, int end) { if (start s.length()) { end = s.length(); } long h = 0; for (int i = start; i
这段源代码的意思其实上面有解释。算法是s[0]31^(n-1) + s[1]31^(n-2) + ... + s[n-1]。然后接下来它说明h = 31*h + s.charAt(i)是等同于h = (h
这里我们把这个公式分解一下,根据上述的公式,我们能推导出下列算术式:
public class test {
public static void main(String args[]) {
String Str = new String("buddy");
System.out.println(hash(Str,0,3));
}
public static long hash(String s, int start, int end) {
if (start s.length()) {
end = s.length();
}
long h = 0;
for (int i = start; i
通过运行程序截取字符串buddy,0-3得到的结果是97905。那么这个结果是怎么算出来的。首先截取0,3,最终截取的是三个字符串
bud。索引从0开始计数对应的就是i=2。根据i=2的公式:
i=2 -> h = 31 * (31 * (31 * 0 + s.charAt(0)) + s.charAt(1)) + s.charAt(2)
我们可以查询ascii表
s.charAt(0),是算"b"这个字母的ASCII值,十进制数字为98
s.charAt(1),是算"u"这个字母的ASCII值,十进制数字为117
s.charAt(1),是算"d"这个字母的ASCII值,十进制数字为100
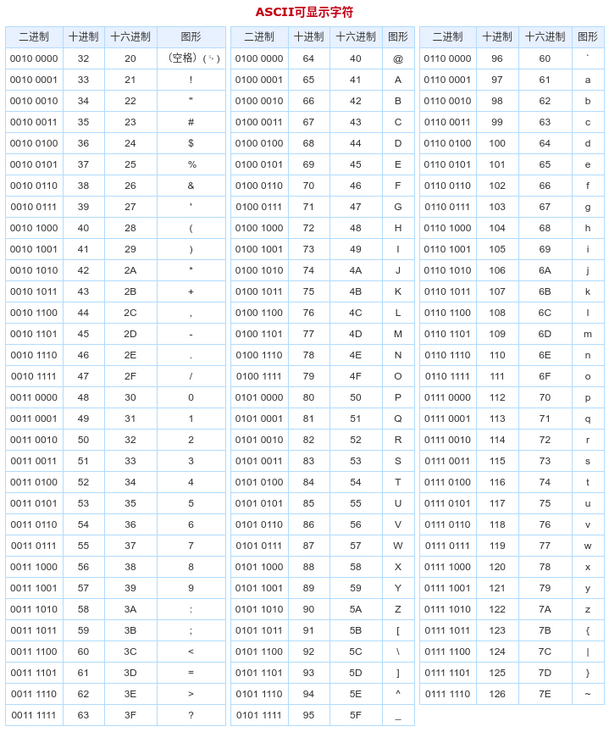
把上述三个值带入到公式得出 31 (31 (31 * 0 + 98) + 117) + 100 = 97905。正好和我们程序计算的值一样。
5.对计算出来的值取模,然后落在指定的分区中。
97905 mod 17 =2 根据取模的值,落在了dn1分区,dn1分区是存放(0,3)的。
6.让我们建表来测试一下,是不是落在第1个分区。
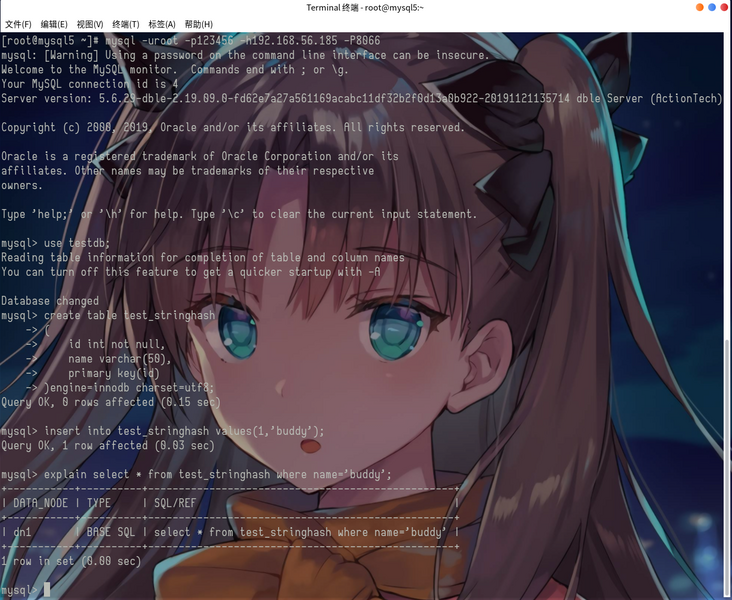
如图所示,当我们执行插入name='buddy',然后再一次查询的name='buddy'的时候,直接路由到了第一个分区。和我们之前计算的结果一致。
注意事项
- 该分区算法和hash分区算法有同样的限制(注意事项3除外)
- 分区字段为字符串类型
后记
今天介绍的stringhash和hash分区算法大致相同,只不过对于字符串需先计算出hash值。该算法有个经典的数字叫31。这个数字大有来头。《Effective Java》中的一段话说明了为什么要用31,因为31是一个奇质数,如果选择一个偶数的话,乘法溢出信息将丢失。因为乘2等于移位运算。使用质数的优势不太明显,但这是一个传统。31的一个很好的特性是乘法可以用移位和减法来代替以获得更好的性能:
31*i==(i。现代的 Java 虚拟机可以自动的完成这个优化。The value 31 was chosen because it is an odd prime. If it were even and the multiplication overflowed, information would be lost, as multiplication by 2 is equivalent to shifting. The advantage of using a prime is less clear, but it is traditional. A nice property of 31 is that the multiplication can be replaced by a shift and a subtraction for better performance: 31 * i == (i如果你前面没看懂前面那段java代码,现在应该明白(h 今天到这儿,后续将继续分享其他的算法。谢谢大家支持!
今天关于《数据库中间件分片算法之stringhash》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
100 收藏
-
100 收藏
-
100 收藏
-
100 收藏
-
100 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习
-

- 忧郁的花瓣
- 好细啊,码起来,感谢博主的这篇技术文章,我会继续支持!
- 2023-03-21 13:26:11
-
- 聪慧的舞蹈
- 这篇博文真及时,细节满满,真优秀,码起来,关注大佬了!希望大佬能多写数据库相关的文章。
- 2023-03-18 06:42:48
-
- 悲凉的胡萝卜
- 写的不错,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢up主分享技术文章!
- 2023-03-16 00:51:43
-
- 典雅的服饰
- 很好,一直没懂这个问题,但其实工作中常常有遇到...不过今天到这,帮助很大,总算是懂了,感谢up主分享文章内容!
- 2023-02-28 22:44:22
-
- 欣喜的服饰
- 这篇文章出现的刚刚好,细节满满,写的不错,码起来,关注作者大大了!希望作者大大能多写数据库相关的文章。
- 2023-02-26 22:55:44