Ollama模型本地部署接入Dify教程
时间:2025-03-20 22:06:54 462浏览 收藏
本文提供Ollama模型本地部署并接入Dify平台的详细教程。通过下载运行Ollama,配置其API服务地址(例如:http://localhost:11434或局域网IP地址),并在Dify平台“设置>模型供应商>Ollama”页面填写相关信息,包括模型名称、基础URL、模型类型及上下文长度等参数,即可实现Ollama模型与Dify的集成。文章还针对Docker部署下的连接错误及不同操作系统环境变量设置等常见问题提供了相应的解决方案,帮助用户快速、高效地完成Ollama模型的本地部署和Dify接入。
Dify 支持集成 Ollama 部署的大型语言模型 (LLM) 推理和嵌入能力。
快速集成指南
-
下载并运行 Ollama: 请参考 Ollama 官方文档进行本地部署和配置。运行 Ollama 并启动 Llama 模型,例如:
ollama run llama3.1。成功启动后,Ollama 会在本地 11434 端口启动 API 服务,访问地址为http://localhost:11434。更多模型信息请访问 https://ollama.ai/library。 -
在 Dify 中配置 Ollama: 在 Dify 的“设置 > 模型供应商 > Ollama”页面填写以下信息:
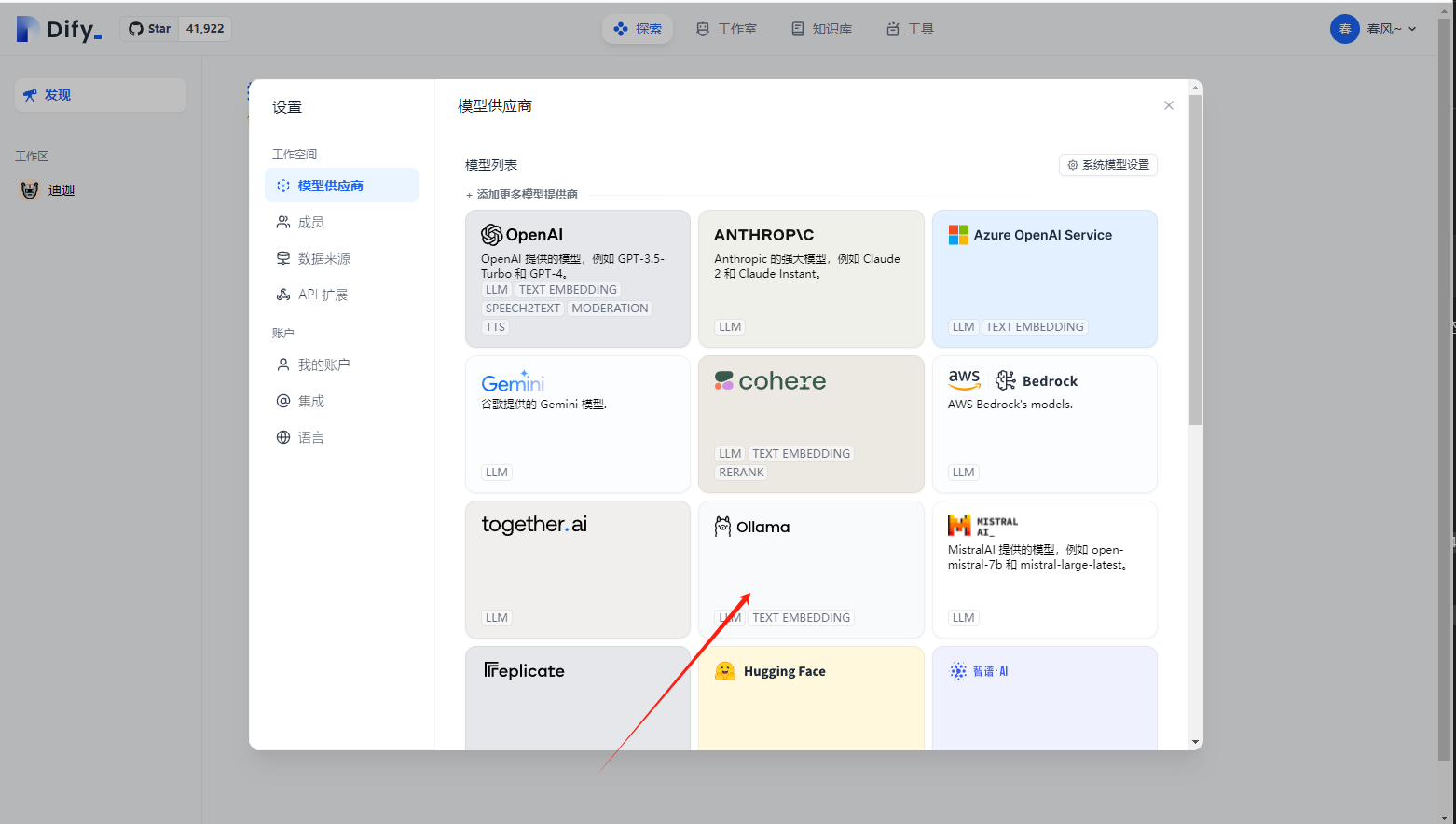

- 模型名称:
llama3.1(或您选择的模型名称) - 基础 URL: 根据您的部署环境填写可访问的 Ollama 服务地址。
- Docker 部署: 建议使用局域网 IP 地址 (例如
http://192.168.1.100:11434) 或 Docker 宿主机 IP 地址 (例如http://172.17.0.1:11434)。 您可以使用ip addr show(Linux/macOS) 或ipconfig(Windows) 命令查找您的 IP 地址。 - 本地源码部署: 使用
http://localhost:11434。
- Docker 部署: 建议使用局域网 IP 地址 (例如
- 模型类型:
对话(或文本嵌入,取决于您使用的模型) - 模型上下文长度:
4096(或模型支持的最大上下文长度) - 最大 token 上限:
4096(或模型支持的最大 token 数量) - 是否支持 Vision:
是(如果模型支持图像理解)
保存配置后,Dify 将验证连接。
- 模型名称:
-
使用 Ollama 模型: 在 Dify 应用的提示词编排页面选择 Ollama 供应商下的
llama3.1模型,设置参数后即可使用。
常见问题解答 (FAQ)
⚠️ Docker 部署下的连接错误:
如果您使用 Docker 部署 Dify 和 Ollama,可能会遇到连接错误,例如 Connection refused。这是因为 Docker 容器无法访问 Ollama 服务。 解决方法是将 Ollama 服务暴露给网络,并使用正确的 Ollama 服务地址 (例如 Docker 宿主机 IP 地址) 在 Dify 中进行配置。
不同操作系统下的环境变量设置:
- macOS: 使用
launchctl setenv OLLAMA_HOST "0.0.0.0"设置环境变量,重启 Ollama 应用。 如果无效,尝试使用host.docker.internal替换localhost。 - Linux: 使用
systemctl edit ollama.service编辑 systemd 服务文件,添加Environment="OLLAMA_HOST=0.0.0.0",然后systemctl daemon-reload和systemctl restart ollama。 - Windows: 关闭 Ollama,修改系统环境变量
OLLAMA_HOST,然后重新启动 Ollama。
如何暴露 Ollama 服务:
Ollama 默认绑定到 127.0.0.1:11434。 您可以通过设置 OLLAMA_HOST 环境变量将其绑定到 0.0.0.0,使其在网络上可见。 请注意网络安全,并仅在受信任的网络环境中这样做。
今天带大家了解了的相关知识,希望对你有所帮助;关于科技周边的技术知识我们会一点点深入介绍,欢迎大家关注golang学习网公众号,一起学习编程~
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
科技周边 · 人工智能 | 1天前 | go · openai · AI接口 · Responses API · Go OpenAI Responses API background mode 异步轮询 大模型接口388 收藏
-
科技周边 · 人工智能 | 1天前 | go语言 · 异步任务 · 人工智能 · openai · API工程化 · Go 异步任务 轮询 数据保留 OpenAI Responses API background mode183 收藏
-
202 收藏
-
科技周边 · 人工智能 | 3天前 | API · go · 人工智能 · 工程实践 · 工具调用 · Go Anthropic Messages API tool_use tool_result Claude工具调用368 收藏
-
243 收藏
-
195 收藏
-
186 收藏
-
333 收藏
-
419 收藏
-
280 收藏
-
科技周边 · 人工智能 | 1星期前 | 异步任务 · 人工智能 · jsonl · AI工程化 · Batch API · 结果对账 · JSONL 大模型批量任务 OpenAI Batch API custom_id AI 离线处理 结果对账113 收藏
-
149 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习