Kyutai开源多模态语音模型MoshiVis发布
时间:2025-04-22 12:09:45 130浏览 收藏
Kyutai推出的开源多模态语音模型MoshiVis,在实时对话语音模型Moshi的基础上,集成了视觉输入功能,实现了图像的自然、实时语音交互。MoshiVis能够接收图像输入并结合语音指令,理解图像中的场景、物体和人物等信息,支持实时语音交互,确保交互体验流畅自然。其核心技术包括轻量级交叉注意力模块和动态门控机制,广泛应用于老年人辅助、智能家居控制、辅助学习等领域,具有巨大的无障碍应用潜力。
MoshiVis:一款开源多模态语音模型,赋能语音与视觉交互
Kyutai推出的开源多模态语音模型MoshiVis,在实时对话语音模型Moshi的基础上,集成了视觉输入功能,实现了图像的自然、实时语音交互。它巧妙地融合了语音和视觉信息,让用户仅通过语音就能与模型轻松交流图像内容。
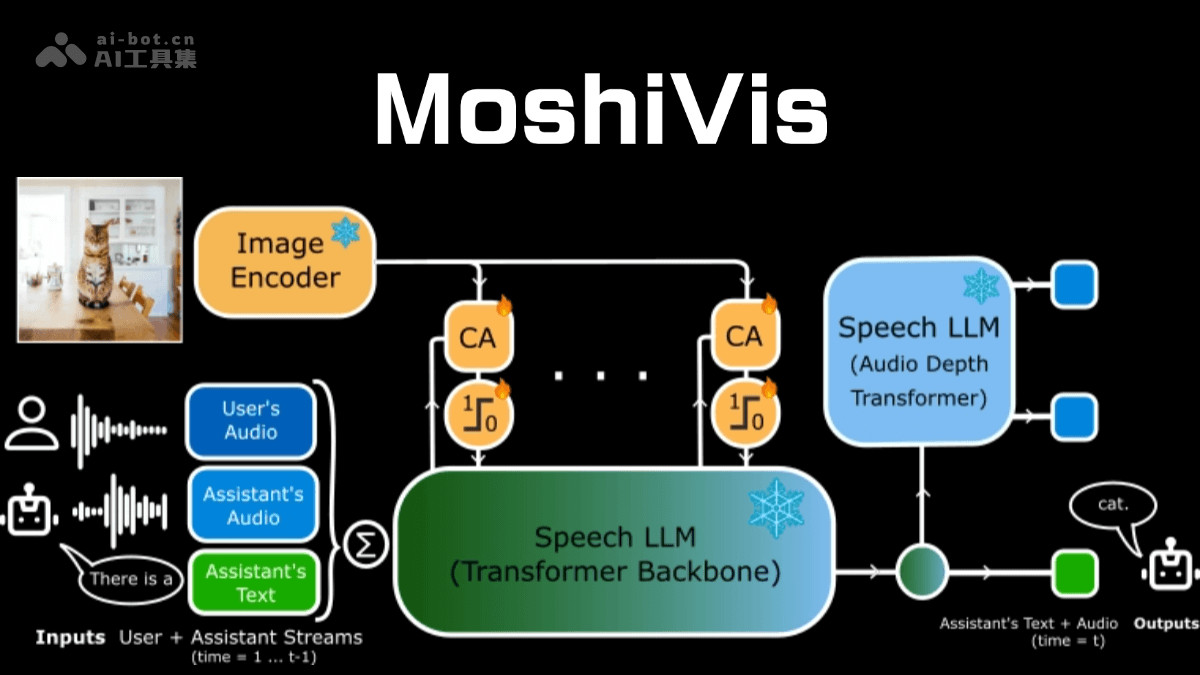
核心功能:
- 图像理解与语音交互: MoshiVis能够接收图像输入并结合语音指令,理解图像中的场景、物体和人物等信息。
- 实时响应,流畅对话: 支持实时语音交互,用户可自然流畅地与模型对话,无需等待。
- 多模态信息融合: 采用跨注意力机制,将视觉和语音信息无缝融合,实现真正意义上的多模态理解。
- 低延迟,自然表达: 在处理图像和语音时保持低延迟,并继承了Moshi的自然对话风格,确保交互体验流畅自然。
- 多后端支持: 兼容PyTorch、Rust和MLX三种后端,并推荐使用Web UI前端进行交互。
- 无障碍应用潜力: MoshiVis在无障碍AI领域具有巨大潜力,可辅助视障人士理解视觉场景。
技术原理:
MoshiVis的核心技术在于其高效的多模态融合和动态门控机制:
- 轻量级交叉注意力模块: 该模块将视觉编码器的图像特征信息注入到Moshi的语音标记流中,实现语音与图像内容的实时交互。
- 动态门控机制: 通过动态调整视觉信息的影响力,MoshiVis能够根据对话上下文灵活切换视觉信息的使用,从而提高对话的自然性和流畅性,避免视觉信息干扰非视觉主题的讨论。
- 参数高效微调: 采用单阶段、参数高效的微调流程,利用图像-文本和图像-语音样本的混合数据进行训练,降低训练成本并提高模型的适应性。
项目信息:
- 项目官网: kyutai.org/moshivis
- Github仓库: http://github.com/kyutai-labs/moshivis
- arXiv技术论文: http://arxiv.org/pdf/2503.15633
应用前景:
MoshiVis的应用场景广泛,涵盖:
- 老年人辅助: 帮助老年人识别物品、阅读文字和获取环境信息。
- 智能家居控制: 通过语音指令控制智能家居设备。
- 辅助学习: 辅助学生通过语音交互学习图像内容。
- 社交媒体互动: 为图片生成语音描述或评论。
- 工业质检: 辅助工人通过语音交互进行设备检查和故障识别。
MoshiVis凭借其强大的多模态融合能力和高效的运行效率,有望在众多领域发挥重要作用,为用户带来更便捷、更智能的交互体验。
本篇关于《Kyutai开源多模态语音模型MoshiVis发布》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于科技周边的相关知识,请关注golang学习网公众号!
相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
339 收藏
-
260 收藏
-
438 收藏
-
152 收藏
-
232 收藏
-
280 收藏
-
152 收藏
-
102 收藏
-
247 收藏
-
306 收藏
-
357 收藏
-
334 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习