Kafka集群搭建教程与优化秘籍
时间:2025-05-08 11:55:08 202浏览 收藏
本文详细介绍了在CentOS-6.7环境下搭建Kafka集群的完整教程。使用三台虚拟机(hadoop01、hadoop02、hadoop03)既作为Zookeeper集群又作为Kafka集群,并详细说明了安装包的下载、解压以及配置文件的修改。文中特别强调了需要修改的关键配置项,如broker.id、host.name、log.dirs和zookeeper.connect,并提供了启动Zookeeper和Kafka服务的具体命令。此外,还介绍了如何验证Kafka集群的运行状态以及测试集群的步骤,确保读者能够顺利搭建并优化Kafka集群。
环境准备
我使用的是CentOS-6.7版本的3个虚拟机,主机名为hadoop01、hadoop02、hadoop03。这3台虚拟机既是Zookeeper集群,又是Kafka集群(但在生产环境中,这两个集群通常会部署在不同的机架上)。我将使用hadoop用户来搭建集群(在生产环境中,root用户通常不被允许随意使用)。关于虚拟机的安装,可以参考以下两篇文章:在Windows中安装一台Linux虚拟机,以及通过已有的虚拟机克隆四台虚拟机。Zookeeper集群参考zookeeper-3.4.10的安装配置。Kafka安装包的下载地址为:https://mirrors.aliyun.com/apache/kafka/,我使用的是kafka_2.11-0.10.2.1.tgz。
- 将Kafka安装包上传到服务器并解压
[hadoop@hadoop01 ~]$ tar -zxvf /opt/soft/kafka_2.11-0.10.2.1.tgz -C /opt/apps/
- 进入Kafka的config目录下,修改server.properties文件
[hadoop@hadoop01 ~]$ cd /opt/apps/kafka_2.11-0.10.2.1/config/ [hadoop@hadoop01 config]$ vim server.properties broker.id=1 host.name=192.168.42.101 log.dirs=/opt/data/kafka zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
说明:
只需修改上述列出的4个配置,其余保持默认。host.name这个配置在原文件中不存在,需要手动添加,建议使用IP地址而不是主机名。这个配置在Kafka单节点或伪分布式集群中不需要设置。broker.id在每个节点上必须唯一,我设置hadoop01的broker.id=1,hadoop02的broker.id=2,hadoop03的broker.id=3。log.dirs指定Kafka数据的存储位置,默认的tmp目录会定期清空,因此需要修改,并且在启动Kafka集群前需要创建指定的目录。zookeeper.connect如果不指定,将使用Kafka自带的Zookeeper。
- 分发安装包
[hadoop@hadoop01 apps]$ scp -r kafka_2.11-0.10.2.1 hadoop03:`pwd`
分别修改hadoop02和hadoop03的broker.id和host.name
在每个节点下创建log.dirs指定的目录
启动Zookeeper服务
[hadoop@hadoop01 ~]$ zkServer.sh start [hadoop@hadoop02 ~]$ zkServer.sh start [hadoop@hadoop03 ~]$ zkServer.sh start
- 在3个节点上都启动Kafka
[hadoop@hadoop01 kafka_2.11-0.10.2.1]$ bin/kafka-server-start.sh -daemon config/server.properties [hadoop@hadoop02 kafka_2.11-0.10.2.1]$ bin/kafka-server-start.sh -daemon config/server.properties [hadoop@hadoop03 kafka_2.11-0.10.2.1]$ bin/kafka-server-start.sh -daemon config/server.properties # -daemon选项的意思是后台启动服务
- 验证Kafka服务是否启动
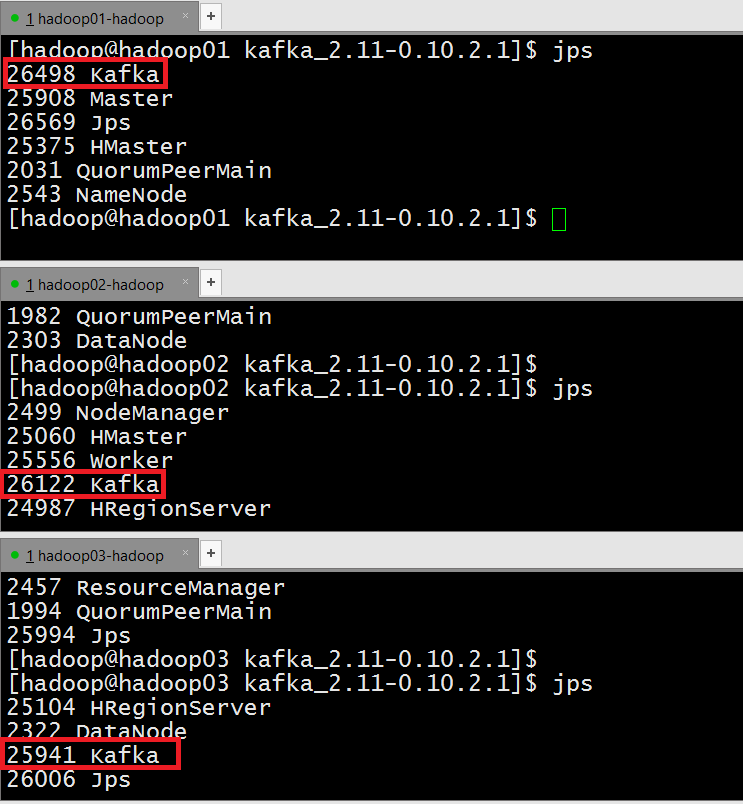
- 测试Kafka集群
(1) 在任意节点上创建"test01"这个topic
[hadoop@hadoop01 kafka_2.11-0.10.2.1]$ bin/kafka-topics.sh \ --create \ --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 \ --replication-factor 1 \ --partitions 1 \ --topic test01
(2) 在hadoop01上开启kafka-console-producer,向test01这个topic中写入数据
[hadoop@hadoop01 kafka_2.11-0.10.2.1]$ bin/kafka-console-producer.sh --broker-list hadoop01:9092,hadoop02:9092,hadoop03:9092 \ --topic test01
(3) 在另一台节点上开启kafka-console-consumer,将hadoop01节点接收到的数据打印出来
[hadoop@hadoop02 kafka_2.11-0.10.2.1]$ bin/kafka-console-consumer.sh \ --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 \ --topic test01 \ --from-beginning
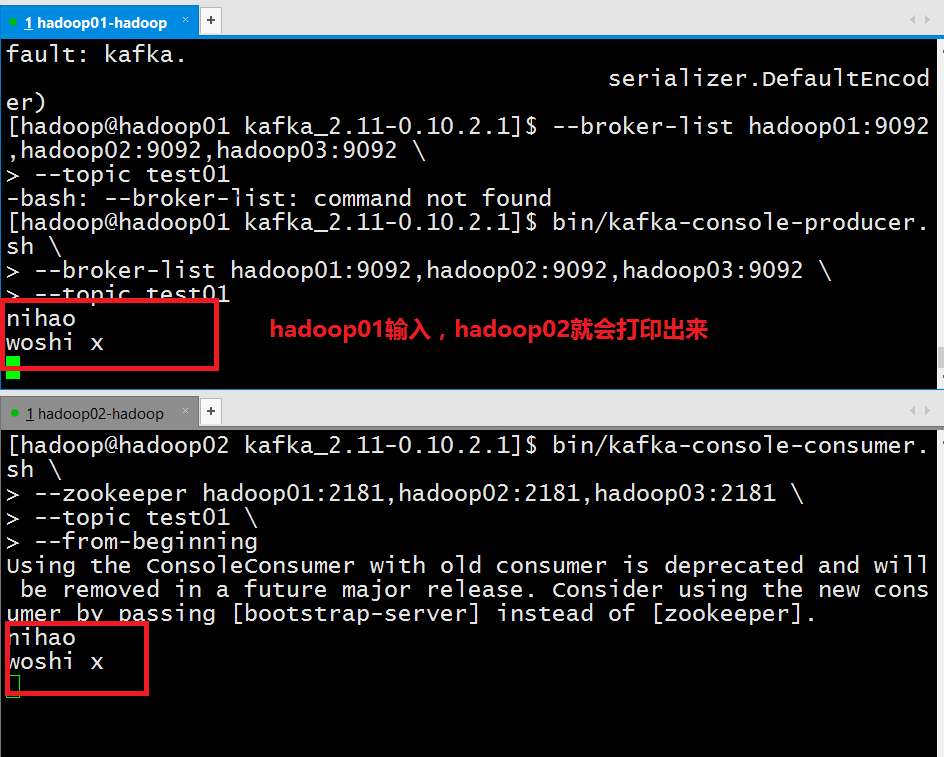
Kafka集群搭建成功!
今天关于《Kafka集群搭建教程与优化秘籍》的内容介绍就到此结束,如果有什么疑问或者建议,可以在golang学习网公众号下多多回复交流;文中若有不正之处,也希望回复留言以告知!
-
228 收藏
-
380 收藏
-
238 收藏
-
372 收藏
-
文章 · 软件教程 | 1星期前 | go · vs code · 软件教程 · 测试任务 · tasks.json · VS Code 测试任务 终端输出 Go插件 Go测试 tasks.json 问题面板501 收藏
-
284 收藏
-
文章 · 软件教程 | 1星期前 | 开发工具 · vs code · profiles · 软件教程 · 配置同步 · 软件教程 Visual Studio Code VS Code Profiles 配置档 导出配置 导入配置185 收藏
-
文章 · 软件教程 | 1星期前 | 开发环境 · windows terminal · 软件教程 · 终端工具 · Ubuntu PowerShell 软件教程 Windows Terminal 默认配置文件 起始路径495 收藏
-
文章 · 软件教程 | 1星期前 | Windows · 软件教程 · PowerToys · PowerRename · 批量重命名 · PowerToys 批量重命名 软件教程 PowerRename Windows重命名 文件改名413 收藏
-
217 收藏
-
486 收藏
-
文章 · 软件教程 | 2星期前 | 环境变量 · postman · 软件教程 · 接口测试 · 导入导出 · 环境变量 Collection JSON文件 导入导出 Postman Environment 接口集合308 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习