FlaskCelery使用攻略与实战示例
时间:2025-05-08 12:09:04 145浏览 收藏
本文详细介绍了在Windows系统上使用Flask和Celery的攻略及示例。首先,讲述了在Windows上安装Celery 3.1版本的必要性及步骤,并强调了Redis服务在Windows上的安装和配置方法。接着,文中提供了在Flask项目中集成Celery的具体代码示例,包括如何配置Celery、创建Celery实例以及定义任务。最后,文章还介绍了常见错误的解决方案和使用Flower监控Celery任务的方法,旨在帮助读者更好地理解和应用Celery在Flask项目中的使用。
安装Celery在Windows上的步骤和注意事项如下:
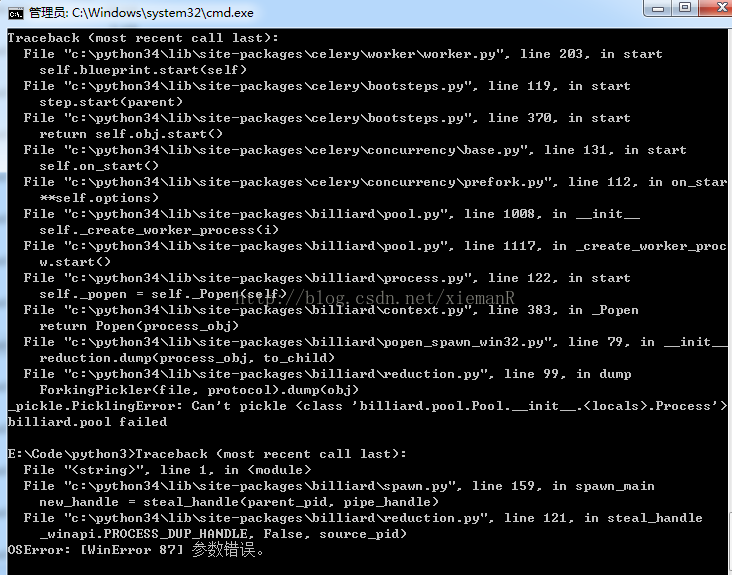
由于Celery 4.0版本不支持Windows操作系统,如果在Windows上安装Celery 4.0,会出现以下错误:
 flask_clery
flask_clery
因此,你只能安装Celery 3.1版本:
pip install celery==3.1
接下来,安装py for redis模块:
pip install redis
安装Redis服务时需要注意,许多在线文章对系统环境描述不清,导致误导。Redis官方支持Linux,但不支持Windows。要在Windows上使用Redis服务,请从以下地址下载Redis安装包并完成安装:
https://github.com/MSOpenTech/redis/releases
如果未安装Redis包,将会出现以下错误:
redis.exceptions.ConnectionError: Error 10061 connecting to localhost:6379.
或
redis.exceptions.ConnectionError
注意:安装目录不要选择C盘,否则可能会遇到权限依赖问题。
添加Redis环境变量:
D:\\Program Files\\Redis
初始化Redis服务:
进入Redis安装目录,打开cmd并运行命令:
redis-server.exe redis.windows.conf
如果出现错误,可以通过双击目录下的redis-cli.exe并在新窗口中输入shutdown和exit来解决。
在Flask中集成Celery时,需要在Flask配置中添加以下配置:
# Celery 配置 CELERY_BROKER_URL = 'redis://localhost:6379/0' # broker是一个消息传输的中间件 CELERY_RESULT_BACKEND = 'redis://localhost:6379/1' # 任务执行器
在Flask工程的__init__目录下创建Celery实例,注意以下代码必须在Flask app读取完配置文件后编写:
def make_celery(app):
celery = Celery(app.import_name, broker=app.config['CELERY_BROKER_URL'],
backend=app.config['CELERY_RESULT_BACKEND'])
celery.conf.update(app.config)
TaskBase = celery.Task
class ContextTask(TaskBase):
abstract = True
def __call__(self, *args, **kwargs):
with app.app_context():
return TaskBase.__call__(self, *args, **kwargs)
celery.Task = ContextTask
return celery
celery = make_celery(app)完整的示例代码如下:
app = Flask(__name__)
app.config.from_object(config['default'])
def make_celery(app):
celery = Celery(app.import_name, broker=app.config['CELERY_BROKER_URL'],
backend=app.config['CELERY_RESULT_BACKEND'])
celery.conf.update(app.config)
TaskBase = celery.Task
class ContextTask(TaskBase):
abstract = True
def __call__(self, *args, **kwargs):
with app.app_context():
return TaskBase.__call__(self, *args, **kwargs)
celery.Task = ContextTask
return celery
celery = make_celery(app)常用的配置文件示例如下:
# 注意,celery4版本后,CELERY_BROKER_URL改为BROKER_URL
BROKER_URL = 'amqp://username:passwd@host:port/虚拟主机名'
# 指定结果的接受地址
CELERY_RESULT_BACKEND = 'redis://username:passwd@host:port/db'
# 指定任务序列化方式
CELERY_TASK_SERIALIZER = 'msgpack'
# 指定结果序列化方式
CELERY_RESULT_SERIALIZER = 'msgpack'
# 任务过期时间,celery任务执行结果的超时时间
CELERY_TASK_RESULT_EXPIRES = 60 * 20
# 指定任务接受的序列化类型.
CELERY_ACCEPT_CONTENT = ["msgpack"]
# 任务发送完成是否需要确认,这一项对性能有一点影响
CELERY_ACKS_LATE = True
# 压缩方案选择,可以是zlib, bzip2,默认是发送没有压缩的数据
CELERY_MESSAGE_COMPRESSION = 'zlib'
# 规定完成任务的时间
CELERYD_TASK_TIME_LIMIT = 5
# 在5s内完成任务,否则执行该任务的worker将被杀死,任务移交给父进程
# celery worker的并发数,默认是服务器的内核数目,也是命令行-c参数指定的数目
CELERYD_CONCURRENCY = 4
# celery worker 每次去rabbitmq预取任务的数量
CELERYD_PREFETCH_MULTIPLIER = 4
# 每个worker执行了多少任务就会死掉,默认是无限的
CELERYD_MAX_TASKS_PER_CHILD = 40
# 设置默认的队列名称,如果一个消息不符合其他的队列就会放在默认队列里面,如果什么都不设置的话,数据都会发送到默认的队列中
CELERY_DEFAULT_QUEUE = "default"
# 设置详细的队列
CELERY_QUEUES = {
"default": { # 这是上面指定的默认队列
"exchange": "default",
"exchange_type": "direct",
"routing_key": "default"
},
"topicqueue": { # 这是一个topic队列 凡是topictest开头的routing key都会被放到这个队列
"routing_key": "topic.#",
"exchange": "topic_exchange",
"exchange_type": "topic",
},
"task_eeg": { # 设置扇形交换机
"exchange": "tasks",
"exchange_type": "fanout",
"binding_key": "tasks",
},
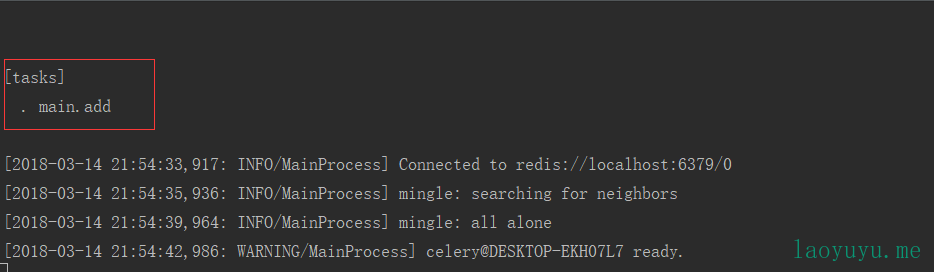
}在cmd中启动Celery服务:
celery -A your_application.celery worker --loglevel=info
其中,your_application为你的工程名称,在这里为get_tieba_film。
调用Celery任务的示例代码如下:
@app.route('/')
@app.route('/index')
def index():
print("耗时的任务")
# 任务已经交给异步处理了
result = get_film_content.apply_async(args=[1])
# 如果需要等待返回值,可以使用get()或wait()方法
# result.wait()
return '耗时的任务已经交给了celery'
@celery.task()
def get_film_content(a):
util = SpiderRunUtil.SpiderRun(TieBaSpider.FilmSpider())
util.start()
绑定任务的示例:
@task(bind=True) def add(self, x, y): logger.info(self.request.id)
任务继承的示例:
import celery
class MyTask(celery.Task):
def on_failure(self, exc, task_id, args, kwargs, einfo):
print('{0!r} failed: {1!r}'.format(task_id, exc))@task(base=MyTask)
def add(x, y):
raise KeyError()
任务名称的设置:
每个任务必须有不同的名称。如果没有显示提供名称,任务装饰器将会自动产生一个,产生的名称会基于这些信息:1)任务定义所在的模块,2)任务函数的名称。
显示设置任务名称的例子:
>>> @app.task(name='sum-of-two-numbers') >>> def add(x, y): ... return x + y >>> add.name 'sum-of-two-numbers'
最佳实践是使用模块名称作为命名空间,这样的话如果有一个同名任务函数定义在其他模块也不会产生冲突。
>>> @app.task(name='tasks.add') >>> def add(x, y): ... return x + y
安装Flower来监控任务和worker的状态:
pip install flower
启动Flower(默认会启动一个webserver,端口为5555):
celery flower --address=127.0.0.1 --port=5555
进入http://localhost:5555即可查看。
常见错误及其解决方案:
ERROR/MainProcess] consumer: Cannot connect to redis://localhost:6379/0:
原因是:Redis-server没有启动。
解决方案:到Redis安装目录下执行redis-server.exe redis.windows.conf。
检查Redis是否启动:redis-cli ping。
line 442, in on_task_received
解决:
Did you remember to import the module containing this task?Or maybe you are using relative imports?Please see http://bit.ly/gLye1c for more information.The full contents of the message body was:{'timelimit': (None, None), 'utc': True, 'chord': None, 'args': [4, 4], 'retries': 0, 'expires': None, 'task': 'main.add', 'callbacks': None,'errbacks': None, 'taskset': None, 'kwargs': {}, 'eta': None, 'id': '97000322-93be-47e9-a082-4620e123dc5e'} (210b)Traceback (most recent call last): File "d:\vm_env\flask_card\lib\site-packages\celery\worker\consumer.py", line 442, in on_task_received strategies[name](message, body,KeyError: 'main.add'
原因:任务没有注册或注册不成功,只有在启动的时候提示有任务的时候,才能使用该任务。
 flask_celery
flask_celery
解决:
你在那个类中使用Celery就在哪个类中执行celery -A 包名.类名.celery worker -l info。根据上一部提示的任务列表给任务设置对应的名称,如在Test中:
from main import app, celery @celery.task(name="main.Test.add") def add(x, y): print "ddddsws" return x + y
目录结构:
+ Card # 工程
- main
- admin
- Task.py
- init.py
- Test.py
则应该启动的命令为:
celery -A main.Test.celery worker -l info
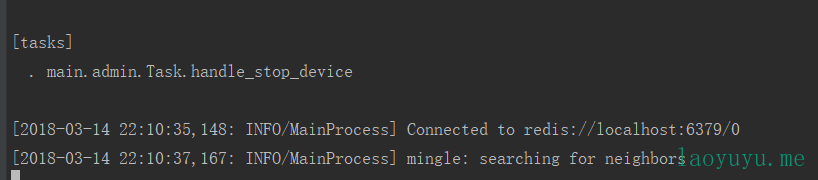
同时,如果你的Task.py也有任务,那么你还应该重新创建一个cmd窗口执行:
celery -A main.admin.Task.celery worker -l info
Celery的工作进程可以创建多个。
 flask_celery
flask_celery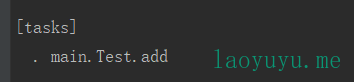 flask_celery
flask_celery参考:
https://www.laoyuyu.me/2018/02/10/python_flask_celery/
https://www.cnblogs.com/cwp-bg/p/8759638.html
Celery用户指南,强烈推荐看Redis安装Celery使用https://redis.io/topics/quickstart
http://einverne.github.io/post/2017/05/celery-best-practice.htmlCelery 最佳实践
http://orangleliu.info/2014/08/09/celery-best-practice/Celery最佳实践-正确使用celery的7条建议
https://www.jianshu.com/p/cc3a0ffb9c76
https://windard.com/opinion/2017/03/18/Task-Queue-Celery使用 Celery 和 redis 完成任务队列
- admin
到这里,我们也就讲完了《FlaskCelery使用攻略与实战示例》的内容了。个人认为,基础知识的学习和巩固,是为了更好的将其运用到项目中,欢迎关注golang学习网公众号,带你了解更多关于的知识点!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
397 收藏
-
460 收藏
-
296 收藏
-
351 收藏
-
128 收藏
-
132 收藏
-
486 收藏
-
184 收藏
-
158 收藏
-
193 收藏
-
141 收藏
-
337 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习