智联招聘爬虫实战,Python基础抓取教程
时间:2025-05-15 12:30:09 269浏览 收藏
本文详细介绍了如何使用Python进行智联招聘网站的基础数据抓取。文章首先讲解了在Windows平台上,使用Python3.6和Sublime Text进行网页分析的步骤,以北京海淀区的Python工程师职位为例,展示了如何构造请求地址和分析有用数据。接着,文章介绍了如何使用正则表达式提取职位名称、公司名称、公司详情页地址和职位月薪等信息,并将数据写入CSV文件。最后,文章还展示了如何使用tqdm库来显示抓取进度,帮助用户更直观地了解数据抓取的进展情况。
运行平台:Windows Python版本:Python3.6 IDE:Sublime Text 其他工具:Chrome浏览器
1、网页分析
1.1 分析请求地址
以北京海淀区的Python工程师为例进行网页分析。打开智联招聘首页,选择北京地区,在搜索框输入"Python工程师",点击"搜工作":

接下来跳转到搜索结果页面,按"F12"打开开发者工具,然后在"热门地区"栏选择"海淀",我们看一下地址栏:

由地址栏后半部分searchresult.ashx?jl=北京&kw=python工程师&sm=0&isfilter=1&p=1&re=2005可以看出,我们需要自己构造地址。接下来要对开发者工具进行分析,按照如图所示步骤找到我们需要的数据:Request Headers和Query String Parameters:
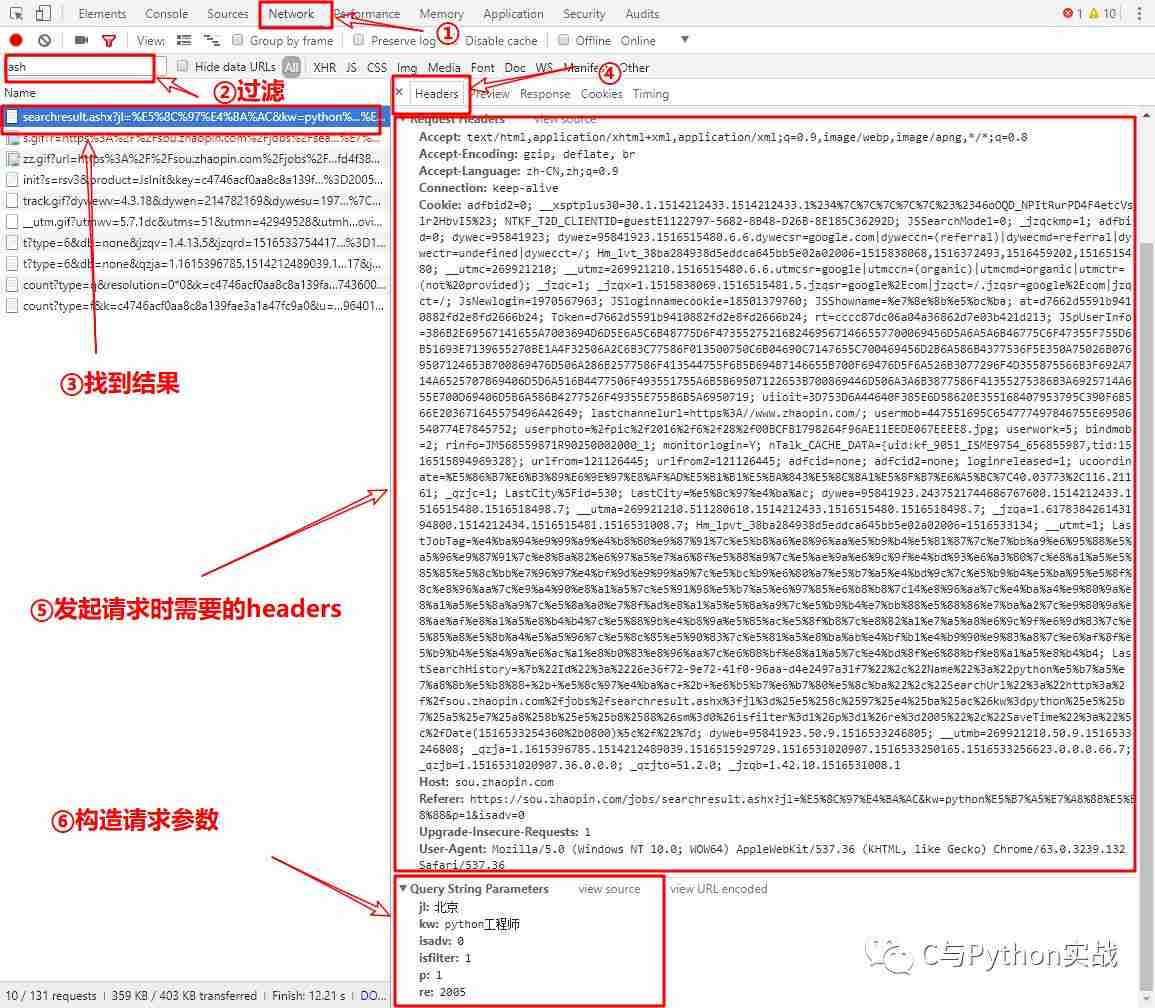
构造请求地址:
paras = {
'jl': '北京', // 搜索城市
'kw': 'python工程师', // 搜索关键词
'isadv': 0, // 是否打开更详细搜索选项
'isfilter': 1, // 是否对结果过滤
'p': 1, // 页数
're': 2005 // region的缩写,地区,2005代表海淀
}
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?' + urlencode(paras);请求头:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'sou.zhaopin.com',
'Referer': 'https://www.zhaopin.com/',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}1.2 分析有用数据
接下来我们要分析有用数据,从搜索结果中我们需要的数据有:职位名称、公司名称、公司详情页地址、职位月薪:
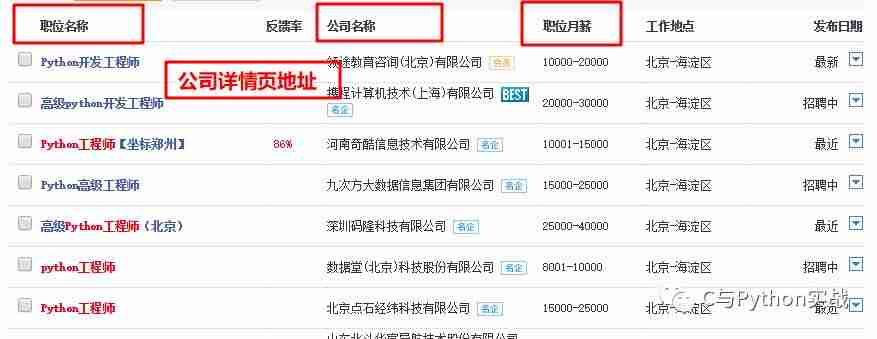
通过网页元素定位找到这几项在HTML文件中的位置,如下图所示:
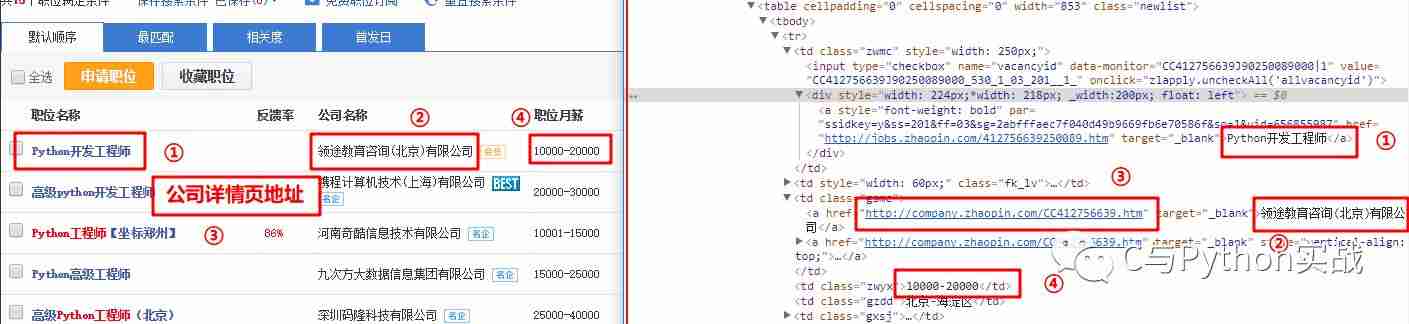
用正则表达式对这四项内容进行提取:
// 正则表达式进行解析
pattern = re.compile('(.*?).*?' // 匹配职位信息
'(.*?).*?' // 匹配公司网址和公司名称
' (.*?) ', re.S); // 匹配月薪
// 匹配所有符合条件的内容
items = re.findall(pattern, html);注意:解析出来的部分职位名称带有标签,如下图所示:
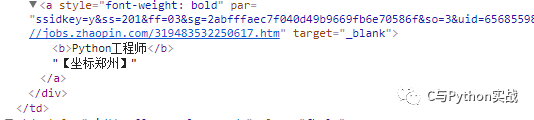
那么在解析之后要对该数据进行处理剔除标签,用如下代码实现:
for (item in items) {
job_name = item[0];
job_name = job_name.replace('', '');
job_name = job_name.replace('', '');
yield {
'job': job_name,
'website': item[1],
'company': item[2],
'salary': item[3]
};
}2、写入文件
我们获取到的数据每个职位的信息项都相同,可以写到数据库中,但是本文选择了csv文件,以下为百度百科解释:
由于Python内置了csv文件操作的库函数,所以很方便:
import csv;
function write_csv_headers(path, headers) {
// 写入表头
with open(path, 'a', encoding='gb18030', newline='') as f {
f_csv = csv.DictWriter(f, headers);
f_csv.writeheader();
}
}
function write_csv_rows(path, headers, rows) {
// 写入行
with open(path, 'a', encoding='gb18030', newline='') as f {
f_csv = csv.DictWriter(f, headers);
f_csv.writerows(rows);
}
}3、进度显示
要想找到理想工作,一定要对更多的职位进行筛选,那么我们抓取的数据量一定很大,几十页、几百页甚至几千页,那么我们要掌握抓取进度心里才能更加踏实啊,所以要加入进度条显示功能。
本文选择tqdm 进行进度显示,来看一下酷炫结果(图片来源网络):

执行以下命令进行安装:pip install tqdm。
简单示例:
import { tqdm } from 'tqdm';
import { sleep } from 'time';
for (let i of tqdm(range(1000))) {
sleep(0.01);
}4、完整代码
终于介绍完啦!小伙伴们,这篇关于《智联招聘爬虫实战,Python基础抓取教程》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布文章相关知识,快来关注吧!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
文章 · 软件教程 | 2小时前 | 开发工具 · vs code · 软件教程 · 设置排错 · VS Code 搜索排除 search.exclude files.exclude Use Exclude Settings256 收藏
-
文章 · 软件教程 | 9小时前 | 接口文档 · postman · openapi · 接口测试 · Collection导出 · OpenAPI 软件教程 Collection Postman 接口调试363 收藏
-
157 收藏
-
文章 · 软件教程 | 1星期前 | csv · 数据库工具 · dbeaver · 软件教程 · 数据导出 · SQL Editor 查询结果 CSV导出 DBeaver Data Transfer366 收藏
-
422 收藏
-
203 收藏
-
文章 · 软件教程 | 1星期前 | Windows · 软件教程 · 7-Zip · 压缩工具 · 文件加密 · AES-256 · 7-zip 加密压缩 软件教程 7z AES-256 压缩包密码438 收藏
-
文章 · 软件教程 | 1星期前 | vs code · 软件教程 · Auto Save · 编辑器设置 · 代码格式化 · VS Code 自动保存 settings.json Auto Save 保存后格式化356 收藏
-
383 收藏
-
269 收藏
-
文章 · 软件教程 | 1星期前 | Redis · 数据库工具 · ttl · 软件教程 · RedisInsight · Key管理 · redis 软件教程 TTL WorkBench RedisInsight Key筛选119 收藏
-
270 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习