Hadoop完全分布式集群搭建实战攻略
时间:2025-05-21 10:54:45 282浏览 收藏
本文详细介绍了在CentOS-6.6版本的四台虚拟机上搭建Hadoop完全分布式集群的完整攻略。使用hadoop用户进行搭建,并详细说明了虚拟机的准备、JDK的安装、免秘钥登录配置以及系统时间同步等前期准备工作。接着,文章提供了从下载Hadoop安装包到配置Hadoop环境变量的具体步骤,包括修改核心配置文件如hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml的详细指南。最后,文章还介绍了如何启动HDFS和YARN系统,并验证集群是否成功搭建,同时提供了集群重装的步骤和方法。
环境准备
我使用的是CentOS-6.6版本的4台虚拟机,主机名分别为node01、node02、node03和node04。我将使用hadoop用户来搭建集群(在生产环境中,root用户通常不允许任意使用)。关于虚拟机的安装,可以参考以下两篇文章:在Windows中安装一台Linux虚拟机,以及通过已有的虚拟机克隆四台虚拟机。为集群中的每个虚拟机创建一个hadoop用户,并赋予sudoer权限,参考:Linux用户管理常用命令和Linux给普通用户赋予sudoer权限。每台虚拟机都需要安装JDK,参考在Linux中安装JDK。集群中的所有虚拟机需要实现两两之间以及自身的免秘钥登录,参考配置各台虚拟机之间免秘钥登录。集群中的所有虚拟机的时间需要同步,参考Linux集群系统时间同步。hadoop安装包的下载地址为:https://mirrors.aliyun.com/apache/hadoop/common/,我使用的是hadoop2.6.5版本。
- 集群规划
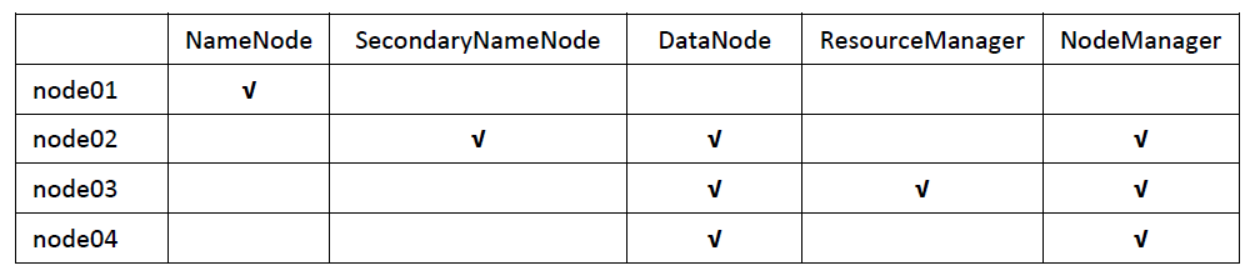
- 安装步骤
(1) 将hadoop安装包上传到服务器并解压
tar zxvf hadoop-2.6.5.tar.gz -C /home/hadoop/apps/
(2) 修改 hadoop-env.sh、mapred-env.sh 和 yarn-env.sh 这三个配置文件,添加JAVA_HOME。hadoop的配置文件位于HADOOP_HOME/etc/hadoop/目录下。
export JAVA_HOME=/usr/local/jdk1.8.0_73
(3) 修改 core-site.xml
fs.defaultFS hdfs://node01:9000 hadoop.tmp.dir /home/hadoop/hadoopdata
(4) 修改 hdfs-site.xml
dfs.namenode.name.dir /home/hadoop/hadoopdata/name dfs.datanode.data.dir /home/hadoop/hadoopdata/data dfs.replication 2 dfs.secondary.http.address node02:50090
(5) 修改 mapred-site.xml。集群中只有mapred-site.xml.template,可以从这个文件进行复制。
cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name yarn
(6) 修改 yarn-site.xml
yarn.resourcemanager.hostname node03 yarn.nodemanager.aux-services mapreduce_shuffle
(7) 修改 slaves 配置文件,指定DataNode所在的节点
node02 node03 node04
(8) 将hadoop安装包分发给其他节点
[hadoop@node01 hadoop]# scp -r /home/hadoop/apps/hadoop-2.6.5 node02:/home/hadoop/apps/ [hadoop@node01 hadoop]# scp -r /home/hadoop/apps/hadoop-2.6.5 node03:/home/hadoop/apps/ [hadoop@node01 hadoop]# scp -r /home/hadoop/apps/hadoop-2.6.5 node04:/home/hadoop/apps/
(9) 为每个节点配置HADOOP_HOME环境变量
vim ~/.bash_profile export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.5 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
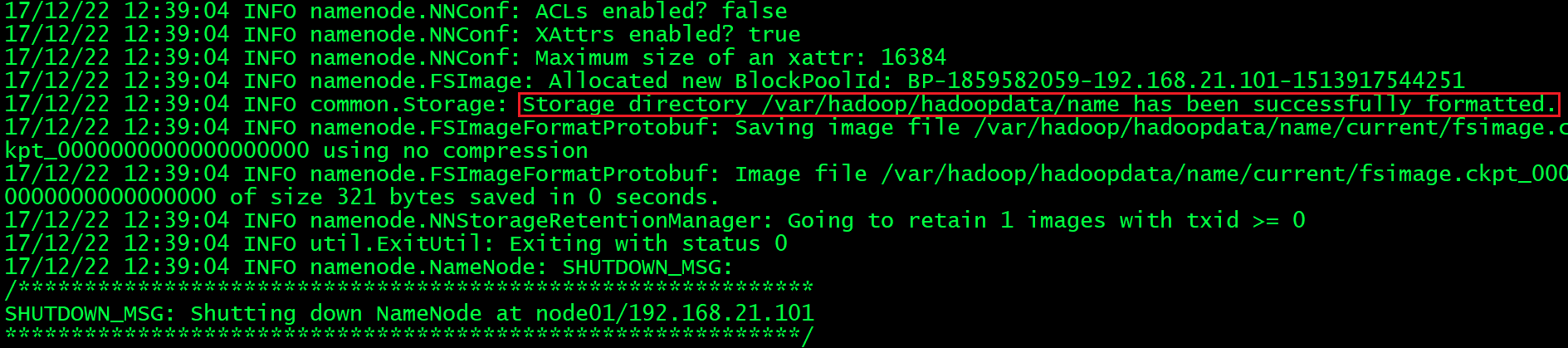
(10) 在namenode主节点(node01)上格式化文件系统
[hadoop@node01 ~]# hdfs namenode -format
看到以下信息说明格式化成功:
(11) 在namenode主节点(node01)上启动hdfs系统
[hadoop@node01 ~]# start-dfs.sh
(12) 在resourcemanager所在节点(node03)上启动yarn
[hadoop@node03 ~]# start-yarn.sh
- 验证集群是否搭建成功
(1) 查看进程是否全部启动
[hadoop@node01 ~]# jps 4000 NameNode 4281 Jps[hadoop@node02 ~]# jps 3442 SecondaryNameNode 3289 DataNode 3375 NodeManager 3647 Jps
[hadoop@node03 ~]# jps 2945 DataNode 3019 ResourceManager 3118 NodeManager 3919 Jps
[hadoop@node04 ~]# jps 2899 DataNode 2984 NodeManager 3149 Jps
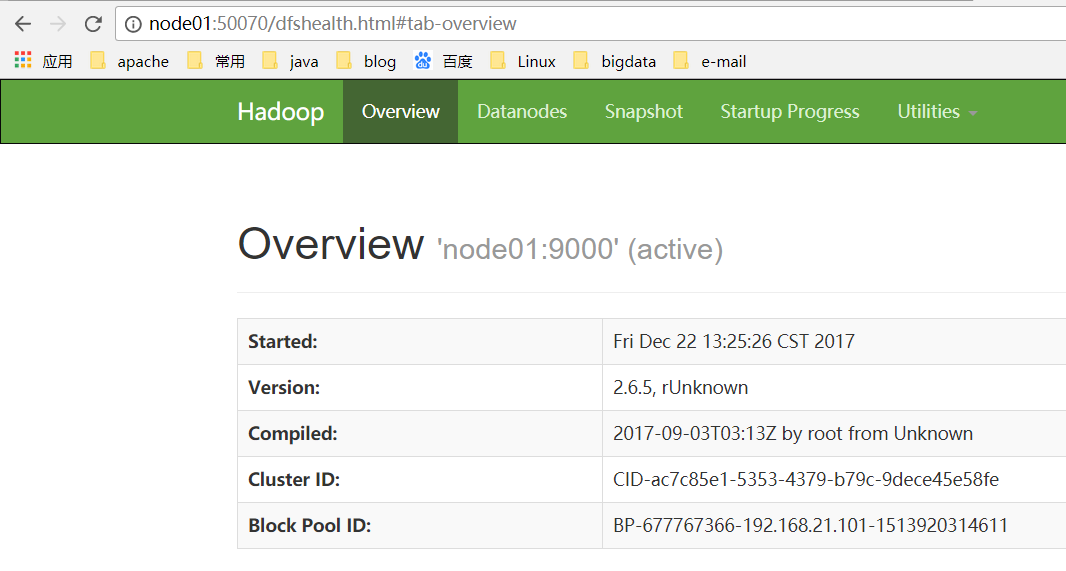
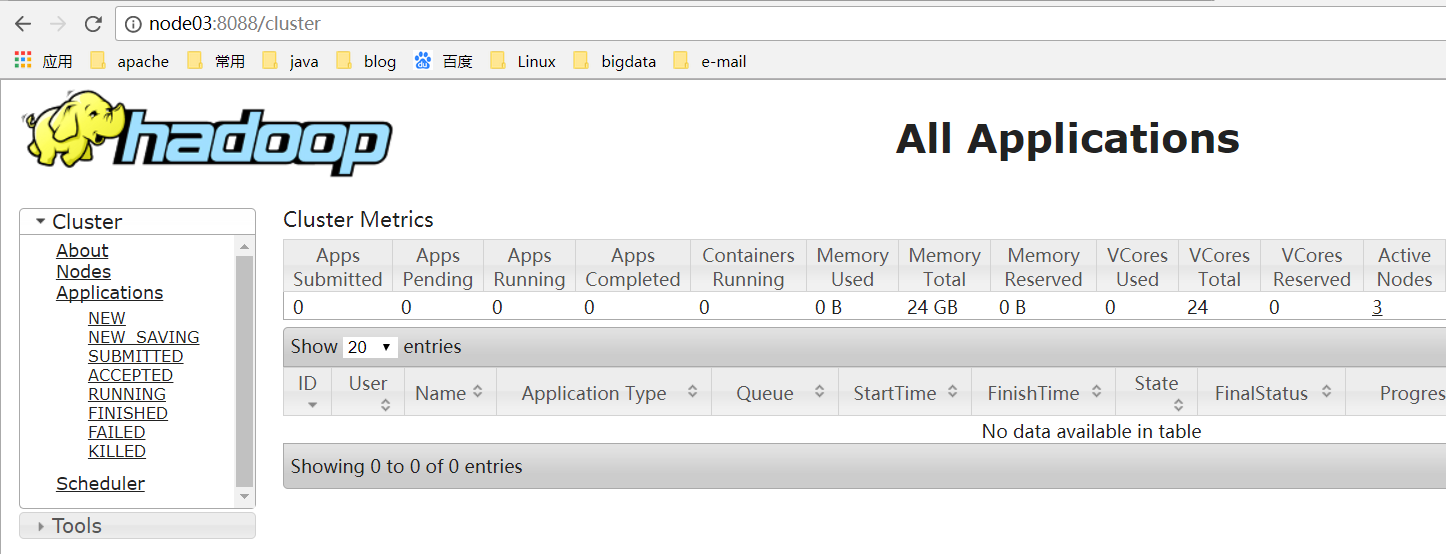
(2) 访问WEB页面
(3) 执行hdfs命令或运行一个mapreduce程序测试
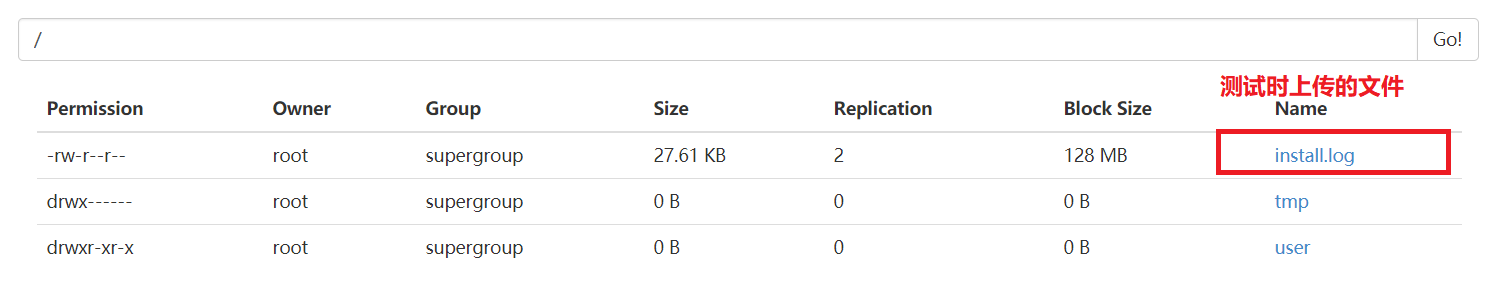
# 上传一个文件 [hadoop@node01 ~]# hdfs dfs -put ./install.log /执行一个mapreduce例子程序
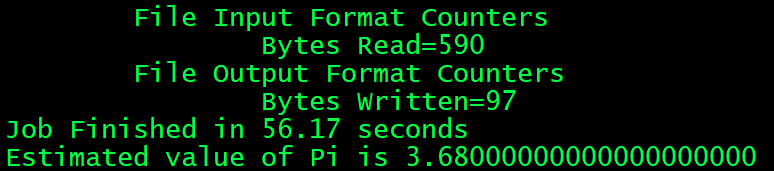
[hadoop@node01 mapreduce]# pwd /home/hadoop/apps/hadoop-2.6.5/share/hadoop/mapreduce [root@node02 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.6.5.jar pi 5 5
文件上传成功:
任务成功运行:

到这里,hadoop完全分布式集群就已经搭建成功了!
- 如果hadoop集群需要重装,按以下步骤进行
(1) 删除每个机器中的hadoop日志。日志默认在HADOOP_HOME/logs下,如果不删除,日志文件会越积累越多,占用磁盘。
(2) 删除原来的namenode和datanode产生的数据和文件。删除你配置的hadoop.tmp.dir这个目录,如果你配置了dfs.datanode.data.dir和dfs.datanode.name.dir这两个配置,那么把这两个配置对应的目录也删除。
(3) 再重新修改hadoop配置文件后,按照安装时的步骤进行即可。
文中关于配置文件,jdk,hadoop,完全分布式集群,CentOS-6.6的知识介绍,希望对你的学习有所帮助!若是受益匪浅,那就动动鼠标收藏这篇《Hadoop完全分布式集群搭建实战攻略》文章吧,也可关注golang学习网公众号了解相关技术文章。
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
366 收藏
-
422 收藏
-
203 收藏
-
438 收藏
-
文章 · 软件教程 | 3天前 | vs code · 软件教程 · Auto Save · 编辑器设置 · 代码格式化 · VS Code 自动保存 settings.json Auto Save 保存后格式化356 收藏
-
383 收藏
-
269 收藏
-
文章 · 软件教程 | 4天前 | Redis · 数据库工具 · ttl · 软件教程 · RedisInsight · Key管理 · redis 软件教程 TTL WorkBench RedisInsight Key筛选119 收藏
-
270 收藏
-
文章 · 软件教程 | 6天前 | MySQL · SQL · dbeaver · 软件教程 · 数据库客户端 · mysql 数据库工具 SQL Editor DBeaver Database Navigator465 收藏
-
278 收藏
-
343 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习