Python爬虫实战:轻松抓取糗事百科热门内容
时间:2025-05-22 08:18:06 307浏览 收藏
标题:Python爬虫实战:轻松抓取糗事百科 内容摘要:本文介绍了如何使用Python编写爬虫程序来抓取糗事百科的内容。文章详细讲解了从查看糗事百科的URL开始,到设置User-Agent、发送请求、获取返回数据,再到使用正则表达式匹配具体内容的整个过程。通过实际代码示例,读者可以轻松理解和掌握Python爬虫的基本操作和应用。
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科。
具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4959489,可以发现page后的数据代表第几页。
然后装配request,注意要设置user_agent
代码语言:javascript代码运行次数:0运行复制1 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'2 headers = {'User-Agent': user_agent}3 request=urllib2.Request(url,headers=headers)4 response=urllib2.urlopen(request)然后获取返回的数据
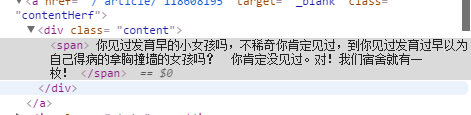
代码语言:javascript代码运行次数:0运行复制content=response.read().decode('utf-8')然后是关键,使用正则匹配出所有的具体内容。这里可以使用浏览器的检查功能查看页面结构,写出相对应的正则式,比如我们对下面的
...
进行匹配的正则式如下代码语言:javascript代码运行次数:0运行复制pattern=re.compile('....(.*?)...',re.S)(.*?) :表示组,该部分为一个整体,将该部分匹配到字符串作为返回值返回,findall表示找到所有匹配的字符串,以序列的形式返回
参数re.S表示"."点号匹配所有字符包括换行
下面是完整代码
代码语言:javascript代码运行次数:0运行复制 1 import urllib 2 import urllib2 3 import re 4 import time 5 6 page=2 7 f=open("D:\qiushi.txt","r+") 8 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' 9 headers = {'User-Agent': user_agent}10 while page....(.*?)...',re.S)20 items=re.findall(pattern,content)21 f.write((url+"\n").encode('utf-8'))22 for item in items:23 print "------"24 item=item+"\n"25 print item26 f.write("------\n".encode('utf-8'))27 f.write(item.replace('
','\n').encode('utf-8'))28 except urllib2.URLError,e:29 if hasattr(e,"code"):30 print e.code31 if hasattr(e,"reason"):32 print e.reason33 finally:34 page+=135 time.sleep(1)这里我是将找到的输出到d盘下的qiushi.txt文件
以上就是本文的全部内容了,是否有顺利帮助你解决问题?若是能给你带来学习上的帮助,请大家多多支持golang学习网!更多关于文章的相关知识,也可关注golang学习网公众号。
相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
366 收藏
-
422 收藏
-
203 收藏
-
438 收藏
-
文章 · 软件教程 | 5天前 | vs code · 软件教程 · Auto Save · 编辑器设置 · 代码格式化 · VS Code 自动保存 settings.json Auto Save 保存后格式化356 收藏
-
383 收藏
-
269 收藏
-
文章 · 软件教程 | 6天前 | Redis · 数据库工具 · ttl · 软件教程 · RedisInsight · Key管理 · redis 软件教程 TTL WorkBench RedisInsight Key筛选119 收藏
-
270 收藏
-
文章 · 软件教程 | 1星期前 | MySQL · SQL · dbeaver · 软件教程 · 数据库客户端 · mysql 数据库工具 SQL Editor DBeaver Database Navigator465 收藏
-
278 收藏
-
343 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习