OpenMP加速笛卡尔乘积并行计算技巧
时间:2025-05-24 17:37:19 444浏览 收藏
文章介绍了如何通过OpenMP加速字典字符集的笛卡尔乘积并行计算。首先,文章详细描述了笛卡尔乘积的概念和计算方法,并通过表达式\[0-9\]\[a-z\]等示例进行说明。其次,文章展示了如何利用OpenMP在Linux平台上实现并行计算,并提供了具体的代码示例。最后,文章还讨论了优化策略,通过从低位到高位计算字典元素下标以及减少重复拷贝来提高计算效率。
以下是对给定文章进行伪原创的输出,确保不改变文章的大意和图片的位置,并保持原文的语言:
- 字典字符集的笛卡尔乘积
问题描述:对于一个由字典字符集组合而成的表达式,如何求出所有可能的元素组合?例如,表达式[0-9][a-z],其中0-9代表10个数字,a-z代表26个小写字母,其所有可能的元素组合为0a, 0b, ..., 0z, 1a, 1b, ..., 9z。字典字符集的笛卡尔乘积示例如下:
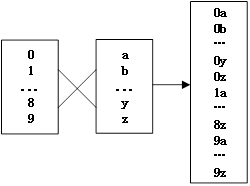
问题分析:对于任意一个由字典字符集构成的表达式[dic0][dic1]...[dicn],可以将其从左到右视为一个由字典元素组成的“数”,这符合我们日常表示数值的高低位习惯。例如,如果所有字典都是[0-9],那么表达式[0-9][0-9]就代表数值字符串00到99。笛卡尔乘积的空间是各个字典高度的乘积,给定其空间中的任意一个元素下标,就可以对应到每个字典中的元素下标。比如[0-9][0-9]的笛卡尔乘积空间是10*10=100,第0个元素是00,第99个元素是99。
每个字典元素都有一个位权重。例如,表达式[0-9][0-9]中,第一个字典的位权重w=10,第二个字典的位权重w=1。我们常说的个位、十位、百位,就是基于数值位的位权重来称呼的。位权重的意义在于,数值是其位权重的多少倍,就取第几个元素。例如,第99个元素(下标从0开始),数值99是十位的位权重w=10的9倍,所以元素为字符‘9’,对数值99取w=10的余数得9,9是个位的位权重w=1的9倍,所以元素为字符‘9’,因此构成了字符串99。
实现示例:对于表达式[0-9][a-z][A-Z],其笛卡尔乘积的具体过程可以描述如下:(1)从左至右(高位到低位)计算各个字典字符集所在数位的计算单位,通过当前字典右边的字典高度相乘得到,例如[0-9]的计数单位w=2626=676,[a-z]的计数单位w=261=26,[A-Z]的计数单位w=1。(2)给定笛卡尔乘积空间的元素下标i,根据i找到各个字典内的元素下标的过程如下,从高位开始查找,即从左开始查找。(2.1)查找字典[0-9]中的元素下标:[0-9].index=i/[0-9].w;(2.2)查找字典[a-z]中的元素下标[a-z].index:i=i%[0-9].w; [a-z].index=i/[a-z].w;(2.3)查找字典[A-Z]中的元素下标[A-Z].index:i=i%[a-z].w;[A-Z].index=i/1=i。(3)将i从0递增至笛卡尔乘积的空间大小减一,即10*26*26-1,重复步骤2,即可完成表达式[0-9][a-z][A-Z]的笛卡尔乘积。
例如,给定第677个笛卡尔乘积的元素,那么[0-9].index=1,所以取[0-9]内的元素‘1’,[a-z].index=671%676/26=0,所以取出元素‘a’,[A-Z].index=1/1=1,所以取出元素‘B’,因此第677个元素就是“1aB”。
- 源码
以下代码在Linux平台上编译运行,稍作修改即可移植到Windows平台。其功能是完成多个字典字符集的笛卡尔乘积,并通过OpenMP进行并行加速。该代码的正确性已在实际项目中通过验证。
代码语言:JavaScript 代码运行次数:0
运行 复制#include#include #include #include
- 优化
在撰写毕业论文时,通过实验室同学的建议,发现无需预先计算各个字典所在数位的计数单位,也可以根据给定的笛卡尔乘积的元素下标唯一地找到各个字典中对应的元素。为了避免论文查重时的重复,这里只展示图片。具体实现已经抽象为以下算法:

算法中的注释中的热词就是上文提到的字典,其实现原理是从表达式的低位到高位计算每一个字典的元素下标,而未优化的方法是从高位到低位顺序计算。从低位到高位计算时,无需预先求出各个字典位的计数单位。因为:当字典位的计数单位为w=1时,可以通过笛卡尔乘积的元素下标i对其高度h取余,即得到最低字典位字典内的元素下标。当对下一个字典求其元素下标时,需要将下一个字典位的计数单位w’变为1,具体做法就是i除以当前字典的高度向下取整。依次类推,就可以求出各个字典内的元素下标了。具体描述见上面的算法。
以表达式[0-9][a-z][A-Z]为例,求笛卡尔乘积中第677个(从0开始)元素的各个字典内的元素下标的过程描述如下:(1)求字典[A-Z]的元素下标index=i%[A-Z].h=677%26=1,所以取元素‘B’;(2)求字典[a-z]的元素下标index:(2.1)将[a-z]的计数单位变为1,做法是i=i/[A-Z].h=677/26=26;(2.2)求[a-z].index=i%[a-z].h=26%26=0,所以取元素‘a’。(3)求字典[0-9]的元素下标index:(3.1)将[0-9]的计数单位变为1,做法是i=i/[a-z].h=26/26=1;(3.2)求[0-9].index=i%[0-9].h=1%10=1,所以取元素‘1’。因此,第677个笛卡尔乘积的元素就是“1aB”,与上面的算法殊途同归。
- 再优化
仔细阅读上面的算法描述,你会发现算法的内层循环存在重复的字典元素拷贝,例如笛卡尔乘积元素下标0~25对应的字典[0-9]和[a-z]内的元素下标始终是0,那么就重复拷贝了[0-9]和[a-z]中元素25次。针对该问题,可以对上面的算法做进一步的优化。
以一次字典元素拷贝作为基本操作,那么第二小节和第三小节的时间复杂度是O(hn),h为笛卡尔乘积空间大小,n为字典个数。
再优化算法描述如下:

再优化步骤描述如下:(1)选取高度最高的字典S_k;(2)循环h次,h为其它字典高度的乘积;(2.1)将其它字典元素拼接在一起;(2.2)循环最高字典高度H_k次,k为最高字典的下标,将元素填充到临时字符串s中后,将s加入笛卡尔乘积集合。
时间复杂度为O(h_0(n-1)+h_0h_1)=O(h_0(h_1+n-1))。其中h_0为非最高字典高度乘积,h_1为最高字典高度,n为字典个数,n≥2。上文中未优化的时间复杂度是优化后的倍数t=h_0h_1n/h_0(h_1+n-1)=n/(1+(n-1)/ h_1),可见,n和h_1越大,优化效果越明显。假设h_1*很大,那么优化的倍数大约为字典的个数。
终于介绍完啦!小伙伴们,这篇关于《OpenMP加速笛卡尔乘积并行计算技巧》的介绍应该让你收获多多了吧!欢迎大家收藏或分享给更多需要学习的朋友吧~golang学习网公众号也会发布文章相关知识,快来关注吧!
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
文章 · 软件教程 | 6小时前 | Windows · 软件教程 · 7-Zip · 压缩工具 · 文件加密 · AES-256 · 7-zip 加密压缩 软件教程 7z AES-256 压缩包密码438 收藏
-
文章 · 软件教程 | 7小时前 | vs code · 软件教程 · Auto Save · 编辑器设置 · 代码格式化 · VS Code 自动保存 settings.json Auto Save 保存后格式化356 收藏
-
383 收藏
-
269 收藏
-
文章 · 软件教程 | 1天前 | Redis · 数据库工具 · ttl · 软件教程 · RedisInsight · Key管理 · redis 软件教程 TTL WorkBench RedisInsight Key筛选119 收藏
-
270 收藏
-
文章 · 软件教程 | 3天前 | MySQL · SQL · dbeaver · 软件教程 · 数据库客户端 · mysql 数据库工具 SQL Editor DBeaver Database Navigator465 收藏
-
278 收藏
-
343 收藏
-
105 收藏
-
122 收藏
-
151 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习